Download as PDF, PPTX

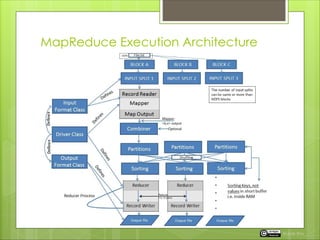










The document outlines the MapReduce execution architecture, detailing components such as input format, record reader, driver class, combiner, partitioner, output format, and record writer. It explains how the process occurs with examples, showing how combiners can optimize data transmission but have limitations with certain functions. The document also describes how to run a MapReduce job and the types of output files generated, including success indicators and logs.























































































