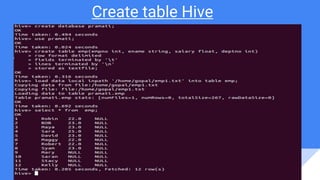
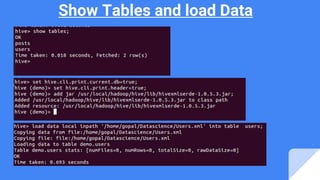
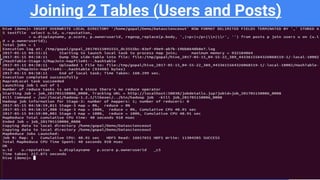
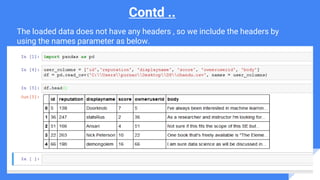
Downloaded 45 times














![Plotting Graph (“Bar”)
%matplotlib inline
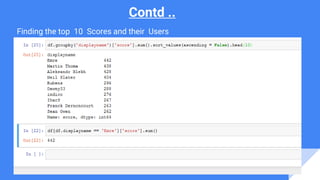
ax = df.groupby(by = ['displayname', 'id'])['score'].sum().sort_values(ascending = False).head(10).
plot(kind='bar',figsize=(10,5), ylim = (50,500), title = "Top 10 users", grid = True, colormap='jet' )
ax.set_xlabel ( "DisplayNames and UsersID")
ax.set_ylabel ("Scores")](https://image.slidesharecdn.com/hiveanddataanalysisusingpandas-170524042516/85/Hive-and-data-analysis-using-pandas-27-320.jpg)


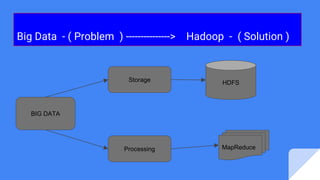
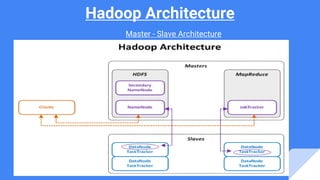
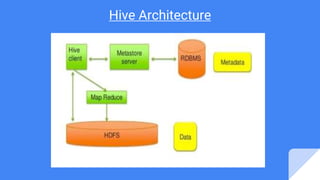
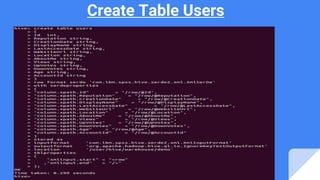
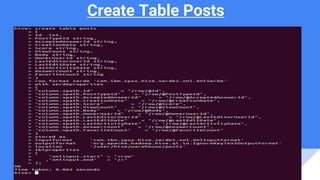
The document provides an overview of big data and Hadoop, explaining Hive's role as a data warehouse infrastructure on top of Hadoop that compiles SQL queries into MapReduce jobs. It discusses Hive architecture, components, and features, highlighting its capacity for working with various data formats and enabling data analysis using Python's Pandas library. An example is given using the Stack Overflow dataset to illustrate the process of creating tables, loading data, and visualizing results graphically.


































































