Download as PDF, PPTX






![Data Types of Apache Hive
2. Data/Time types
3. String Types: STRING, CHAR, VARCHAR
4. Others like BOOLEAN , BINARY
Complex Data Types:
1) Arrays: it is a collection of elements of same type.
Example: store the data like char[] arrary=(i,am,…..)
then,
elements can be called by
array[0] means i
array[1] means am
array[2] means array
Rupak Roy](https://image.slidesharecdn.com/15-220114074348/85/Introductive-to-Hive-7-320.jpg)

![Data Types of Apache Hive
MAP: is a collection of elements in Key-Value pairs.
The key-value pairs can be of different data
types.
Example: MAP < PRIMITIVE_type, data_type>
student MAP < STRING,TINYINT>
Now if we save the value in STRING(KEY) as ‘Emma’
Then TINYINT(VALUE) as 782
Then you can accessed by using
student[“Emma”] will give 782
Rupak Roy](https://image.slidesharecdn.com/15-220114074348/85/Introductive-to-Hive-9-320.jpg)


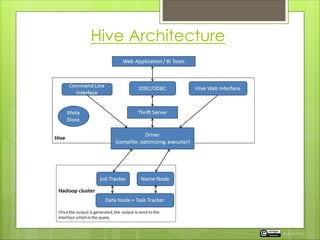
Apache Hive is a data warehouse platform for Hadoop, enabling data summarization and query analysis using a SQL-like language called HiveQL. It simplifies query execution through a structured interface and translates HiveQL into MapReduce jobs executed on Hadoop. The document also outlines Hive's architecture, data types, and functionalities including a metastore for managing metadata.























































































