Download to read offline



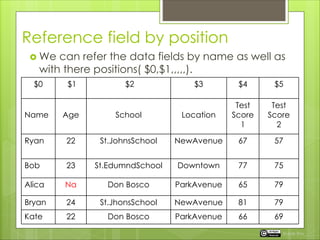







This document discusses various ways to reference and select fields or columns from a Pig dataset: - Fields can be referenced by position (e.g. $0, $1) or by name. When the schema is unknown, position is safer. - The entire range of fields can be selected using .. syntax (e.g. $0..$3). - Fields can be cast to different types (e.g. (chararray)$4) during selection. - Filters should reference fields by position rather than name when the schema is unknown, to avoid errors from missing or misplaced values.



































































