Download to read offline



![Operator Description Example
() Tuple constructor
operator − This
operator is used to
construct a tuple.
(Raju, 30)
{} Bag constructor
operator − This
operator is used to
construct a bag.
{(Raju, 30),
(Mohammad, 45)}
[] Map constructor
operator − This
operator is used to
construct a tuple.
[name#Raja,
age#30]
Pig Latin – Type Construction Operators
The following table describes the Type construction operators of Pig Latin.](https://image.slidesharecdn.com/unit-4lecture-3-210825041541/85/Unit-4-lecture-3-8-320.jpg)
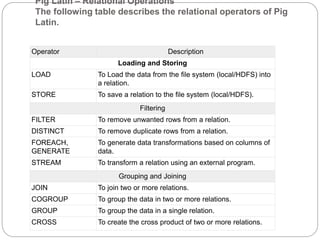
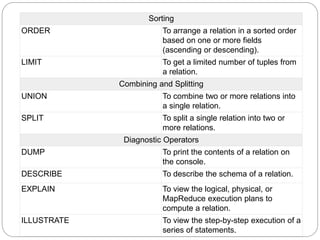

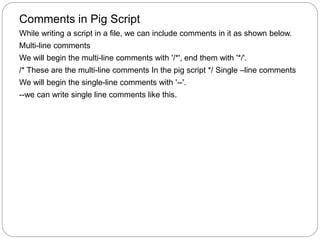
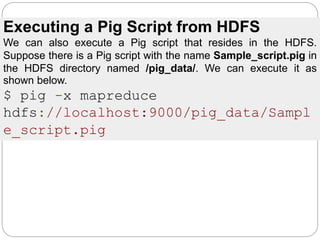
The document discusses Pig Latin scripts and how to execute them. It provides examples of multi-line and single-line comments in Pig Latin scripts. It also describes how to execute Pig Latin scripts locally or using MapReduce and how to execute scripts that reside in HDFS. Finally, it summarizes key differences between Pig Latin and SQL and describes common relational operators used in Pig Latin.





































![Unit-5 [Pig] working and architecture.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/unit-5pig-240605082042-8125c633-thumbnail.jpg?width=640&height=640&fit=bounds)
















































