Download as PDF, PPTX


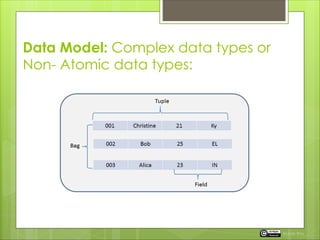










The document details the Pig Latin data model which includes single (atomic) and complex (non-atomic) data types. It explains how to load, store, and manipulate data using Pig commands, including the use of the PigStorage function for different delimiters. Additionally, it discusses the behavior of loading data when the defined schema does not match the actual data structure.























































































