Download to read offline



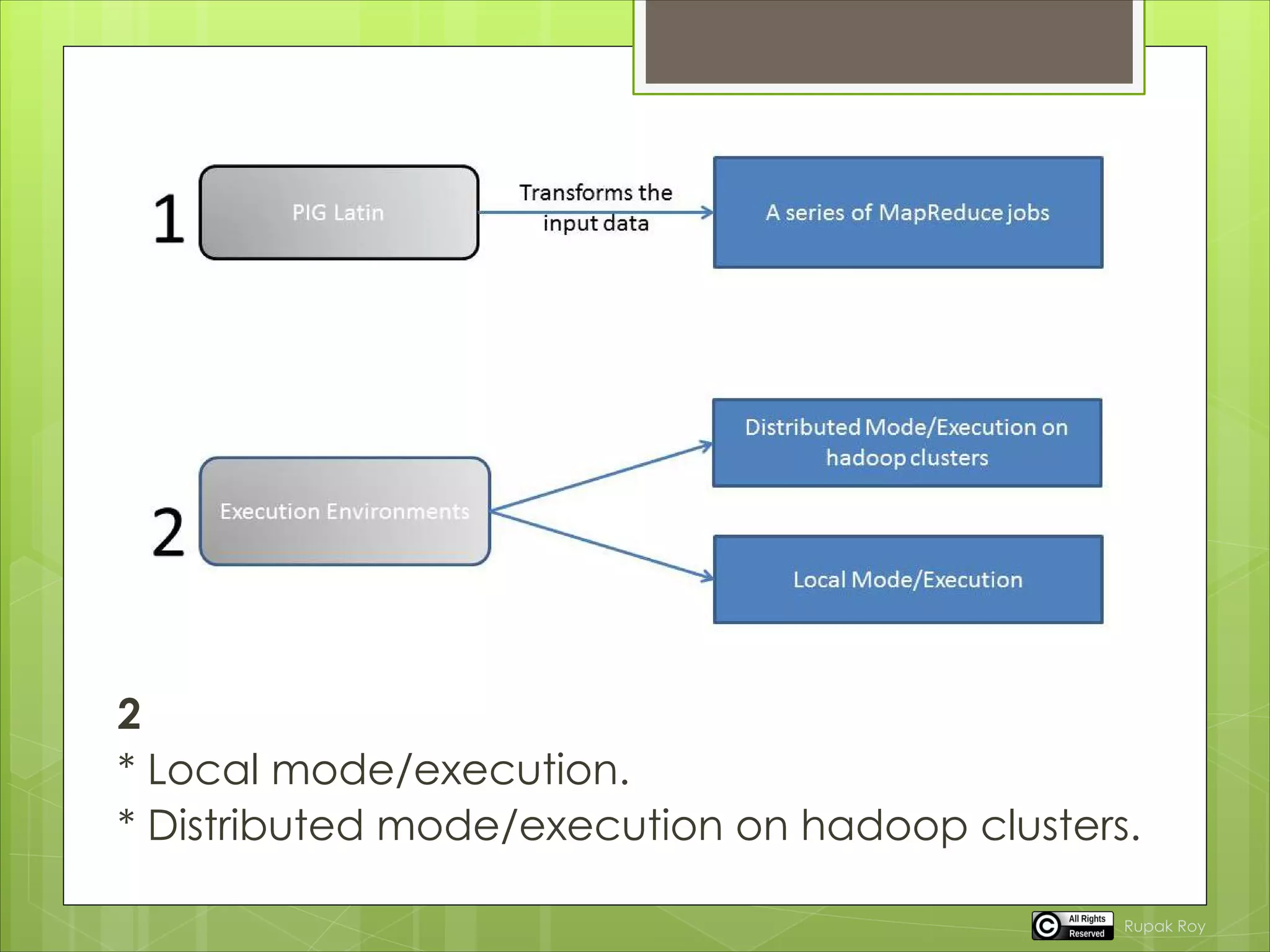

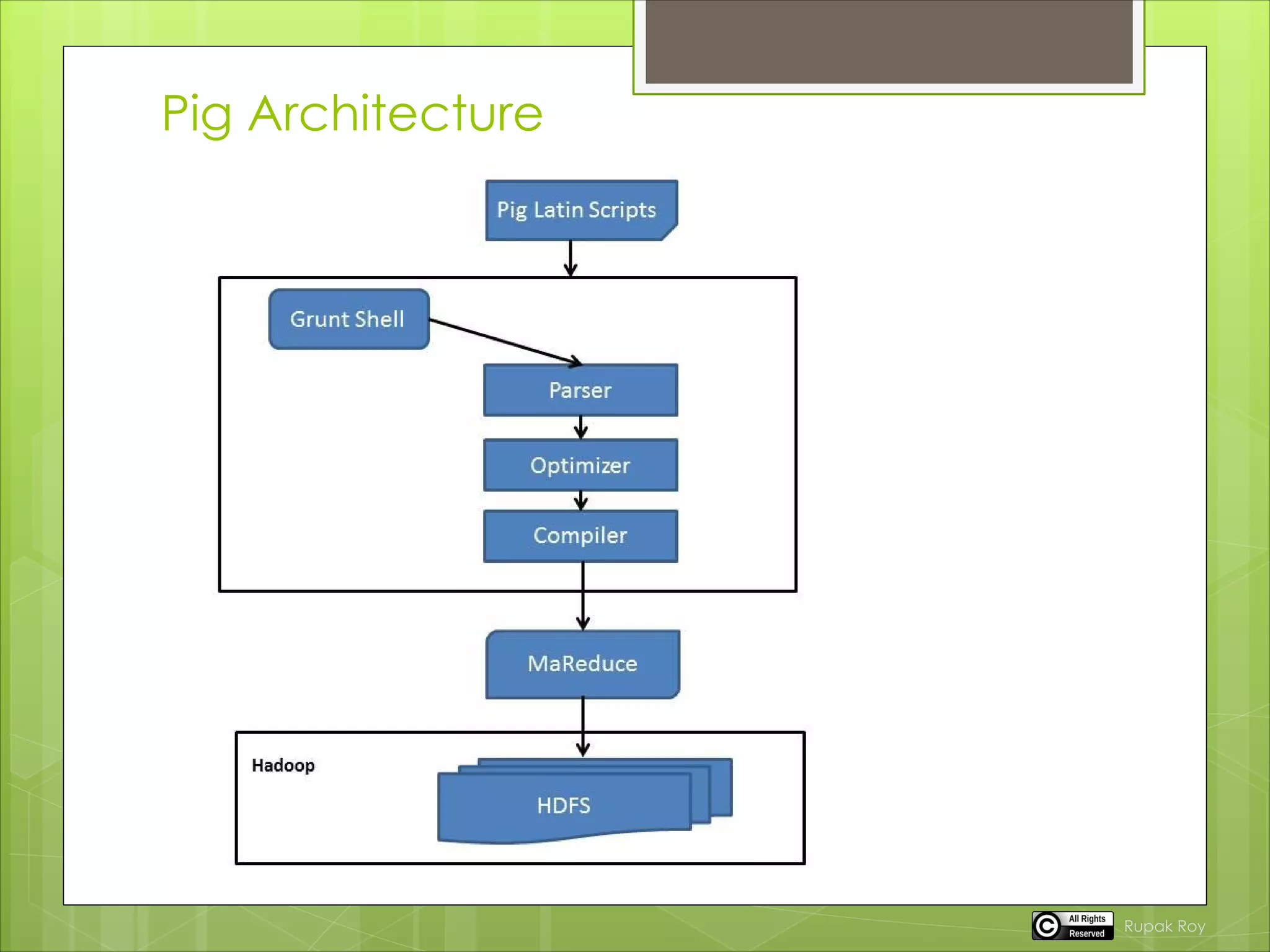



Pig is a tool for analyzing large datasets. It consists of a compiler that turns user input into a series of MapReduce programs. This allows users to focus on data analysis rather than writing MapReduce programs. Pig Latin is the language used, which compiles user scripts into directed acyclic graphs that are optimized and compiled into MapReduce jobs. Pig can read and write to HDFS as well as local storage. It has two execution modes - local mode for debugging on a local machine and cluster mode for running on Hadoop clusters using MapReduce.



































































