Downloaded 74 times








![ Atom
Any single value in Pig Latin, irrespective of their data, type is known as an Atom. It is stored as string
and can be used as string and number. int, long, float, double, chararray, and bytearray are the
atomic values of Pig. A piece of data or a simple atomic value is known as a field.
Example − ‘raja’ or ‘30’
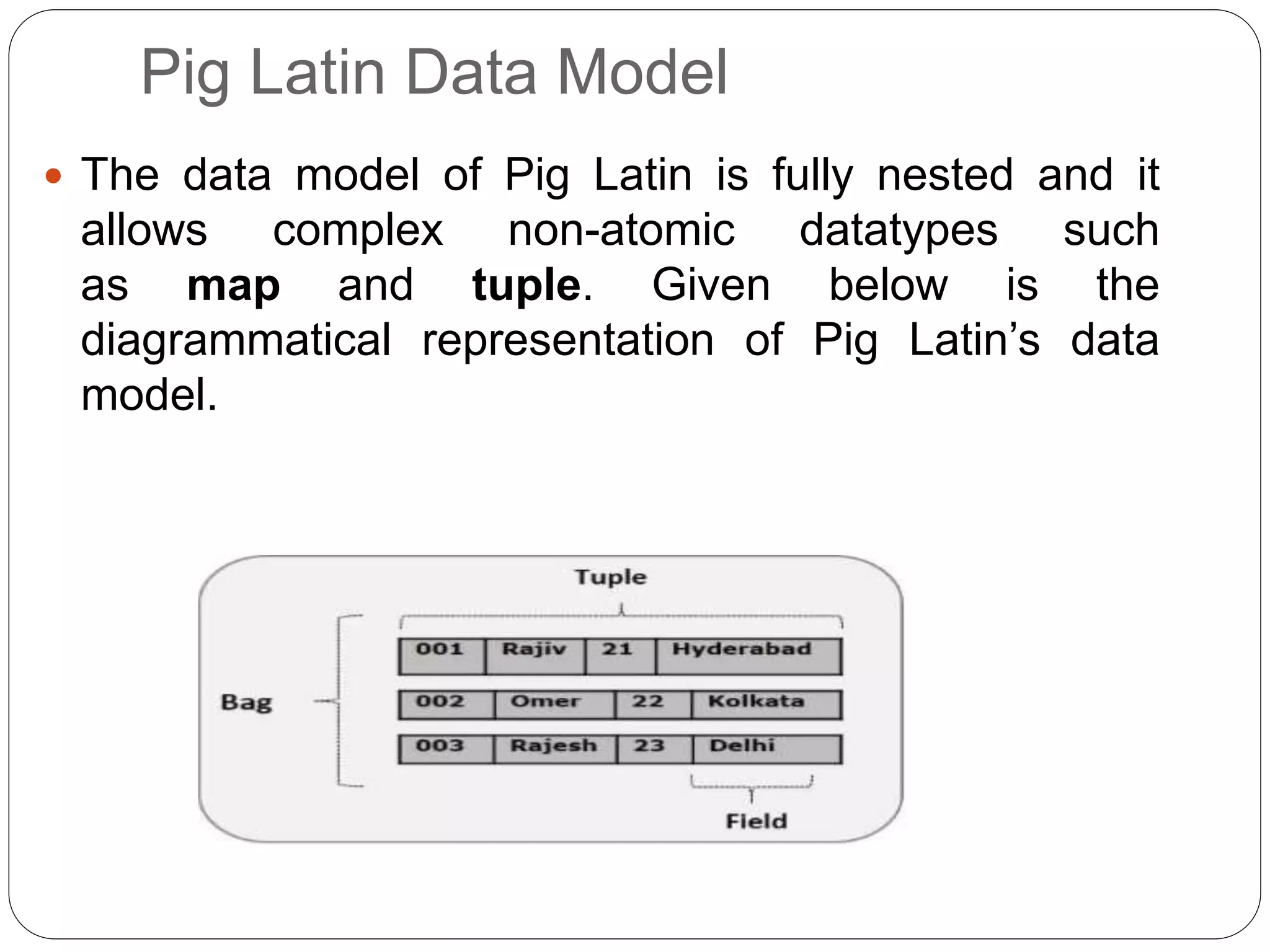
Tuple
A record that is formed by an ordered set of fields is known as a tuple, the fields can be of any type. A
tuple is similar to a row in a table of RDBMS.
Example − (Raja, 30)
Bag
A bag is an unordered set of tuples. In other words, a collection of tuples (non-unique) is known as a
bag. Each tuple can have any number of fields (flexible schema). A bag is represented by ‘{}’. It is
similar to a table in RDBMS, but unlike a table in RDBMS, it is not necessary that every tuple
contain the same number of fields or that the fields in the same position (column) have the same
type.
Example − {(Raja, 30), (Mohammad, 45)}
A bag can be a field in a relation; in that context, it is known as inner bag.
Example − {Raja, 30, {9848022338, raja@gmail.com,}}
Map
A map (or data map) is a set of key-value pairs. The key needs to be of type chararray and should be
unique. The value might be of any type. It is represented by ‘[]’
Example − [name#Raja, age#30]
Relation
A relation is a bag of tuples. The relations in Pig Latin are unordered (there is no guarantee that tuples
are processed in any particular order).](https://image.slidesharecdn.com/unit-4-apachepig-210825041412/75/Unit-4-apache-pig-12-2048.jpg)




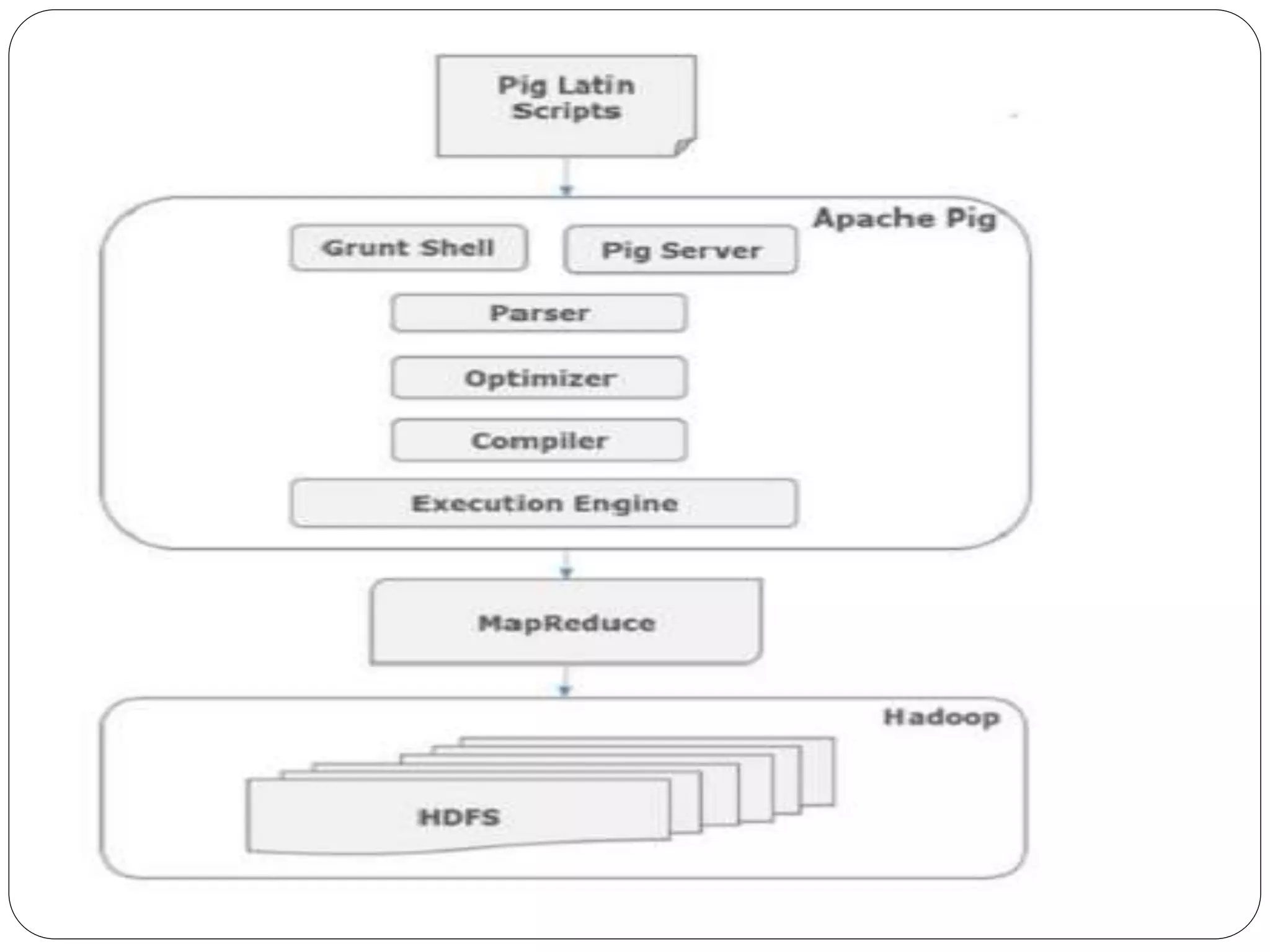
Apache Pig is a platform for analyzing large datasets that operates on top of Hadoop. It provides a high-level language called Pig Latin that allows users to express data analysis programs, which Pig then compiles into MapReduce jobs for execution. The main components of the Pig architecture are the Pig Latin parser and optimizer, which generate a logical plan, and the compiler, which converts this into a physical execution plan of MapReduce jobs. Pig aims to simplify big data analysis for users by hiding the complexity of MapReduce.










































![Unit-5 [Pig] working and architecture.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/unit-5pig-240605082042-8125c633-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Imai Jen-La Plante - The New Generation: AI and the Future of...](https://cdn.slidesharecdn.com/ss_thumbnails/kxi8t2l5rggivgcenyba-1-jenlaplante-dsc-251208152532-d1e076c2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)




