Downloaded 12 times






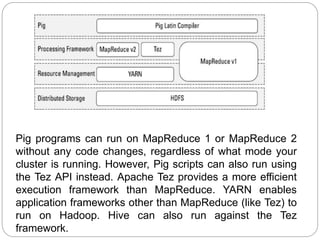






Pig is a tool that makes Hadoop programming easier for non-Java users. It provides a high-level declarative query language called Pig Latin that is compiled into MapReduce jobs. Pig Latin allows users to express data analysis logic without dealing with low-level MapReduce code. It was developed at Yahoo! to help users focus on analyzing large datasets rather than writing Java code. Pig includes features like automatic optimization and extensibility to make it smarter and more useful for developers.












































































![[DSC Europe 25] Raul Cruz Bonilla - Harnessing GEN AI in Fashion, Luxury and ...](https://cdn.slidesharecdn.com/ss_thumbnails/me7nvup5thwqzwzblbvw-raul-cruz-harnessing-ai-en-luxury-260123083019-32ac5a43-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)

