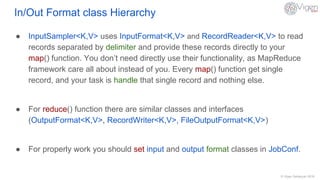
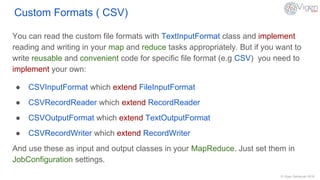
This document discusses data types and formats used in Hadoop MapReduce. It covers basic data types like IntWritable and Text that support serialization and comparability. It also describes common file formats like XML, JSON, SequenceFiles, Avro, Parquet, and how to implement custom formats like CSV. Input/output classes are discussed along with how different formats can be used in MapReduce jobs.