Downloaded 51 times

























![Cassandra Collections
CREATE TABLE posts (
id
uuid,
body
varchar,
created timestamp,
authors set<varchar>,
tags
set<varchar>,
PRIMARY KEY(id)
);
!
INSERT INTO posts (id,body,created,authors,tags) VALUES (
ea4aba7d-9344-4d08-8ca5-873aa1214068,
‘アルトビーの犬はばかね’,
‘now',
[‘アルトビー’, ’ィオートビー’],
[‘dog’, ‘silly’, ’犬’, ‘ばか’]
);
quick story about 犬ばかね
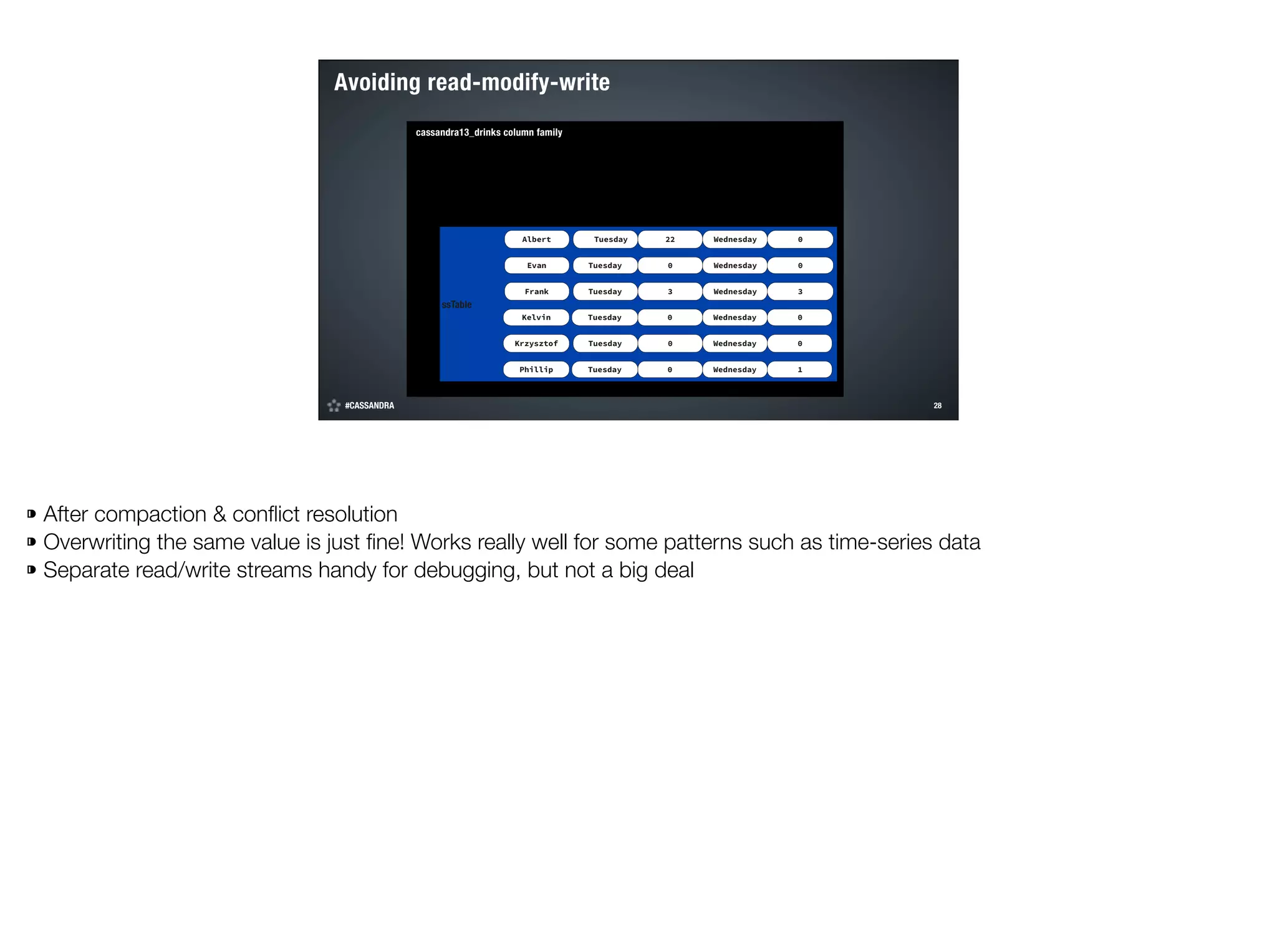
sets & maps are CRDTs, safe to modify](https://image.slidesharecdn.com/managing-cassandra-scale12x-140224125509-phpapp01/75/Managing-Cassandra-at-Scale-by-Al-Tobey-33-2048.jpg)















This document discusses managing Apache Cassandra at scale. It provides an overview of Cassandra's history and evolution from Dynamo and BigTable. It also discusses Cassandra's data model and how it handles operations like reads, writes and updates in a distributed system without relying on read-modify-writes. The document also covers Cassandra best practices like using collections, lightweight transactions and time series data modeling to optimize for scalability.











































































































