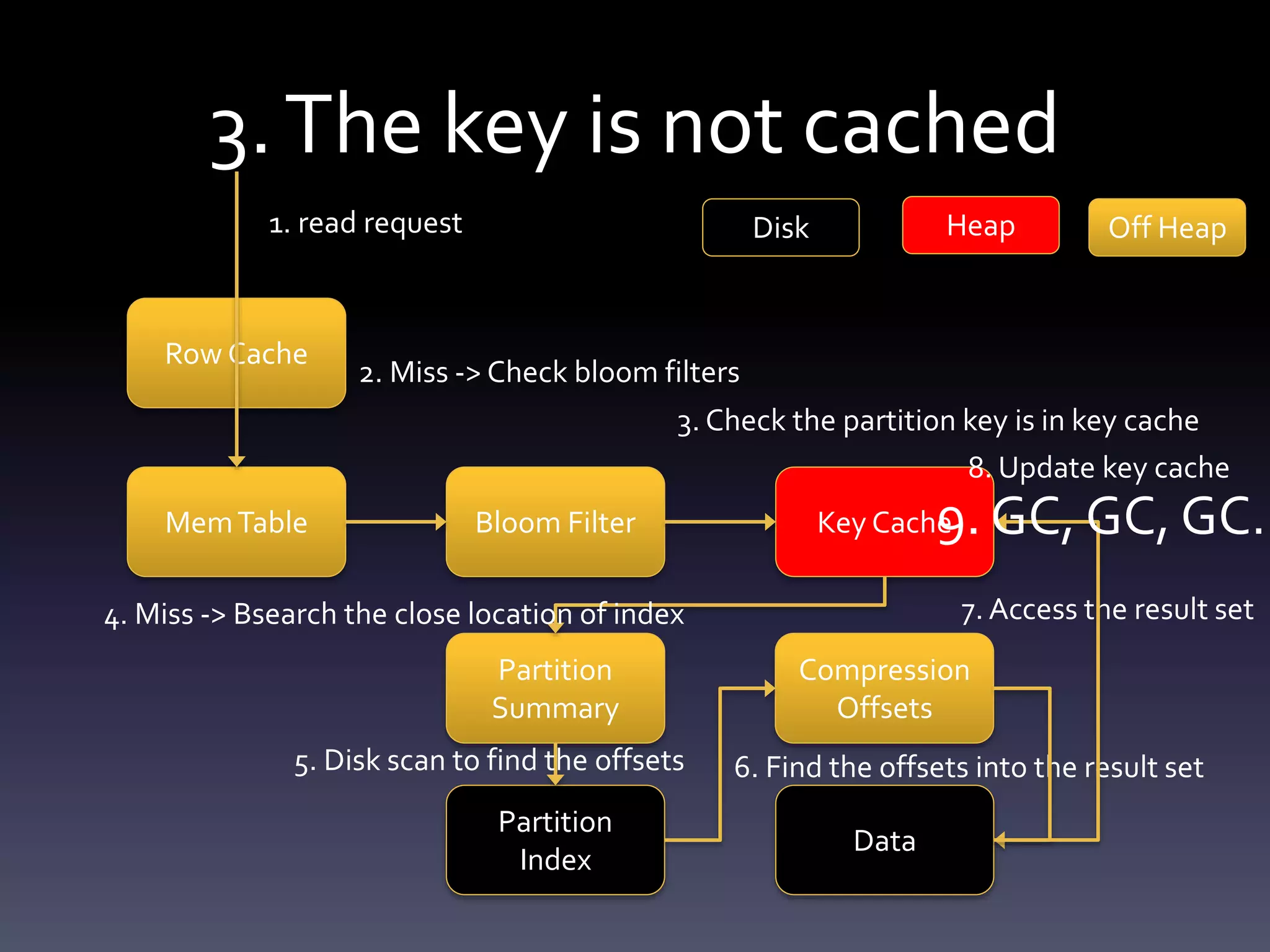
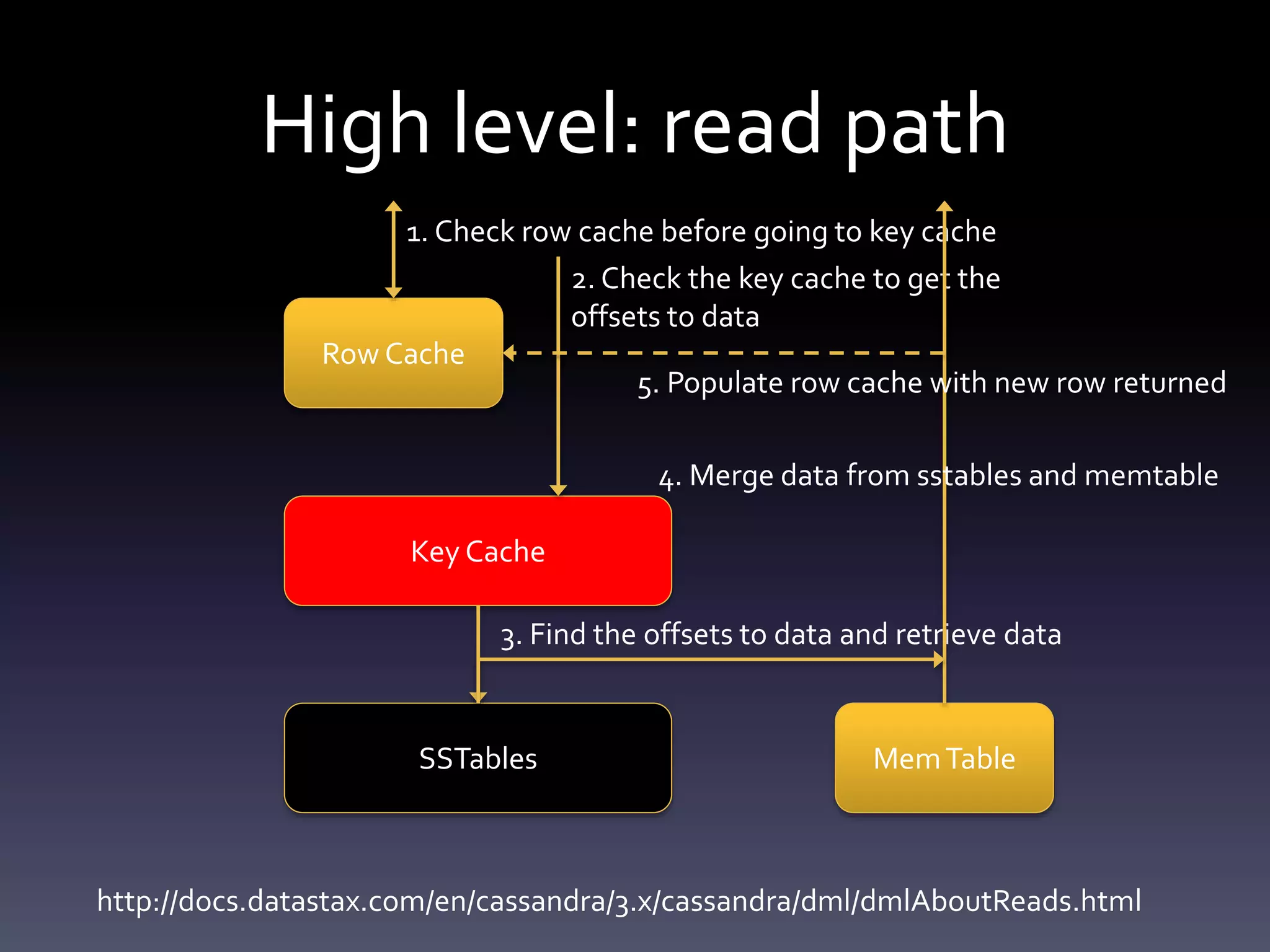
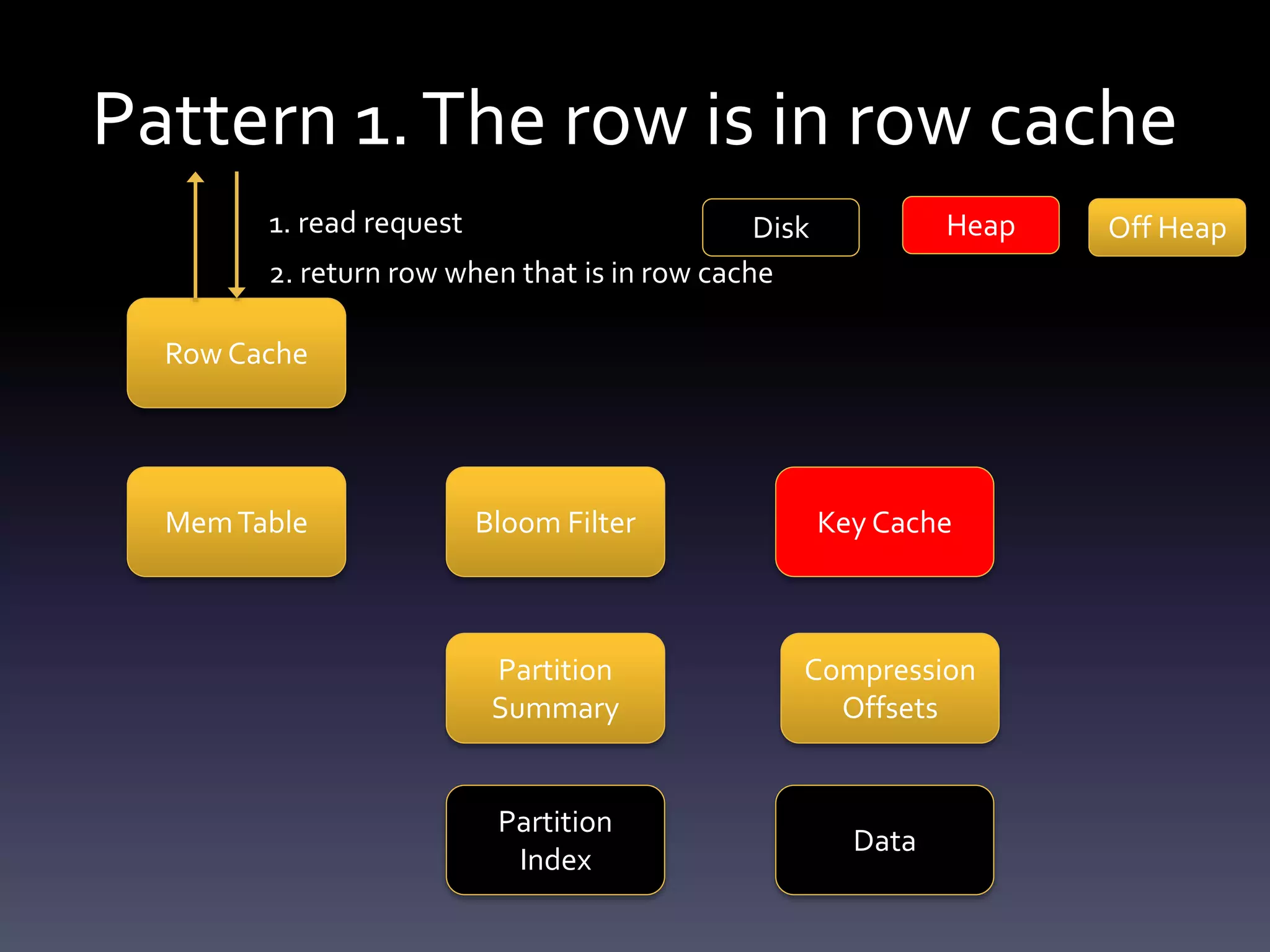
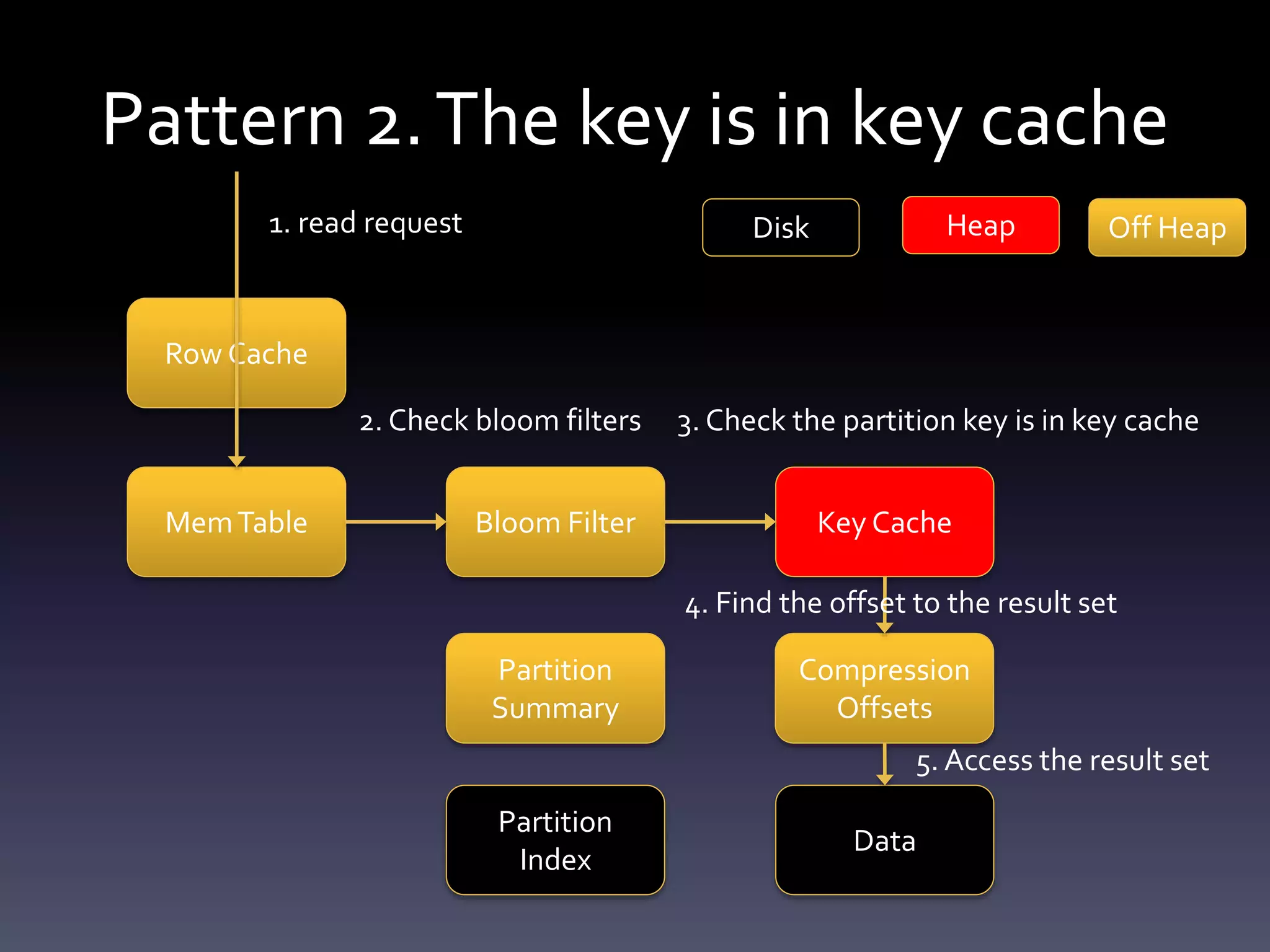
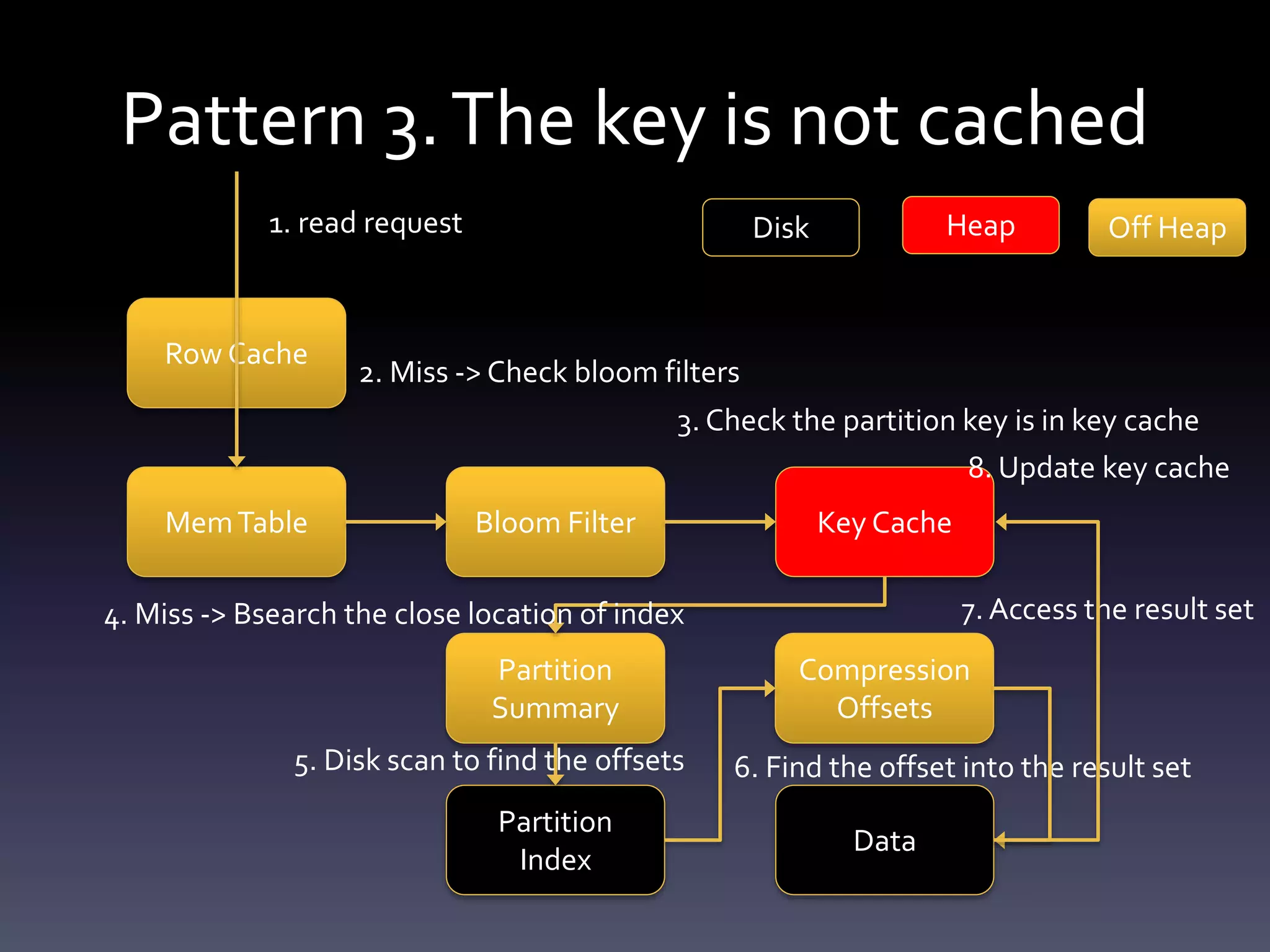
This document summarizes challenges with large partitions in Cassandra and potential solutions. When a large partition is read, the key cache can cause garbage collection pressure as it stores the partition's index on the Java heap. Currently, the index is stored off-heap only if the partition exceeds a configurable size, otherwise it is kept on-heap. Fully migrating the key cache off-heap is another potential solution but incurs serialization costs.






![RowIndexEntry
• Partition size < 64 kb
– RowIndexEntry
• Position
• Seriarized size of data
• Partition size > 64 kb
– IndexedEntry
• Position
• Seriarized size of data
• IndexInfo[]
– Seriarize method
– Offset
– width
– Etc.
Approximation on 16 byte value
1mb : 3kb / > 200 objects
4mb : 11kb / > 800 objects
64mb : 180kb / > 13k objects
512mb : 1.4mb / > 106k objects](https://image.slidesharecdn.com/cassandrareadpath-160623060829/75/Large-partition-in-Cassandra-11-2048.jpg)