Download as PDF, PPTX














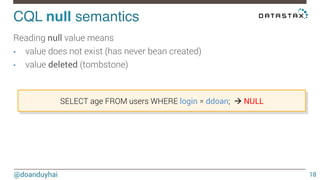
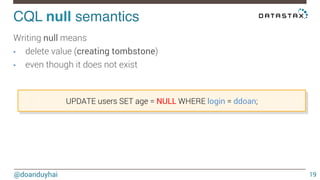
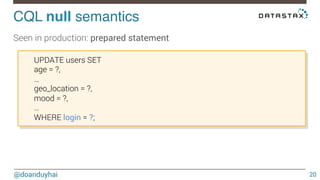
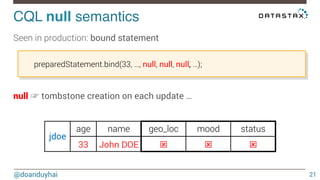

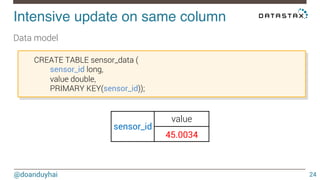

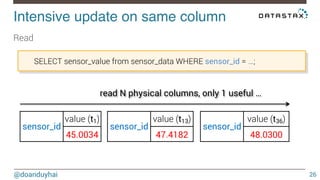

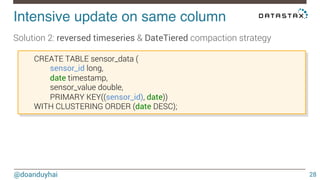
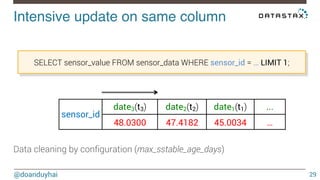






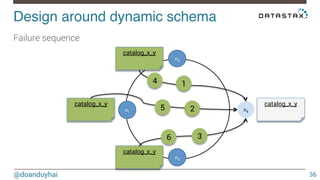
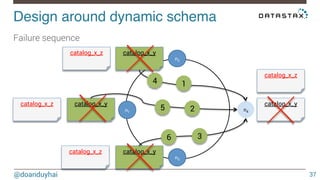
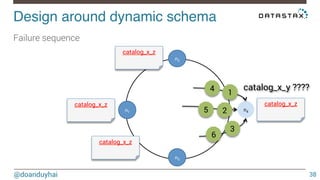






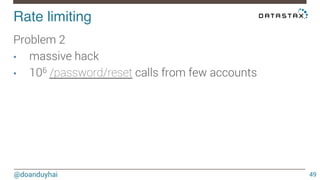
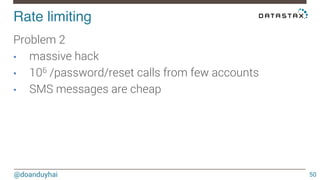

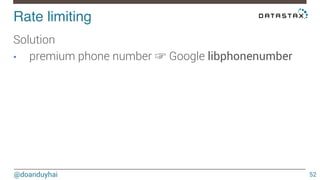


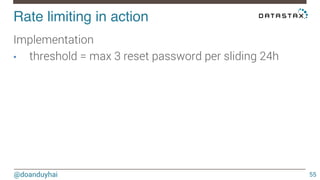
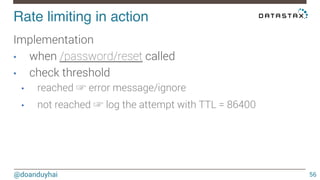


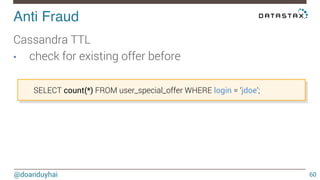
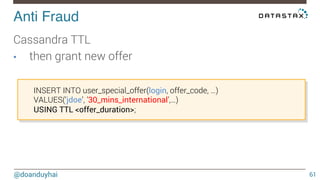
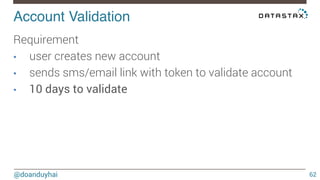
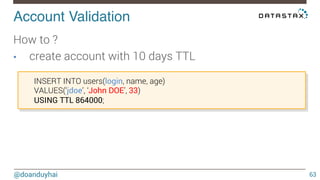
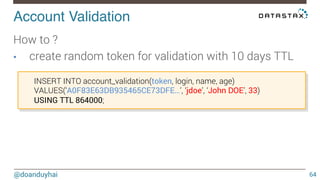
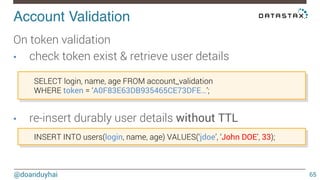

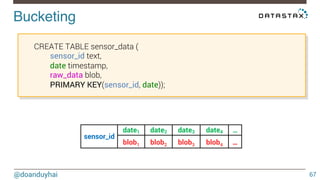

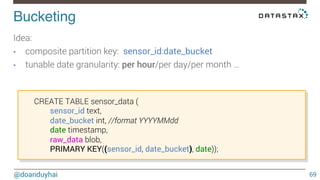
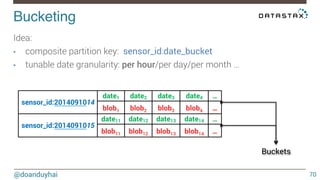
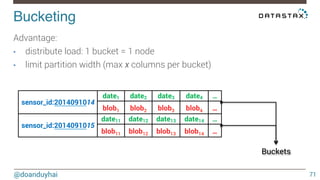
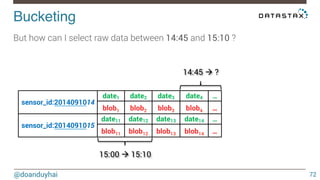
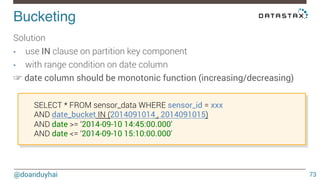
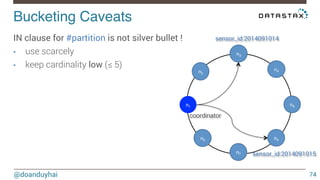
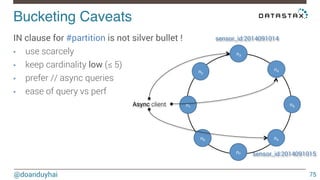






This document discusses Cassandra use cases and anti-patterns. Some good use cases include rate limiting, fraud prevention, account validation, and storing sensor time series data. Poor designs include using Cassandra like a queue, storing null values, intensive updates to the same column, and dynamically changing the schema. The document provides examples and explanations of how to properly implement these scenarios in Cassandra.