Download as PDF, PPTX





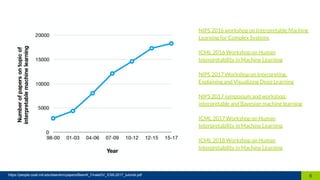




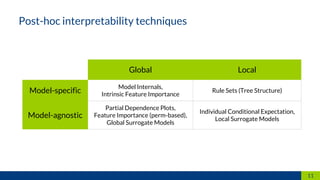
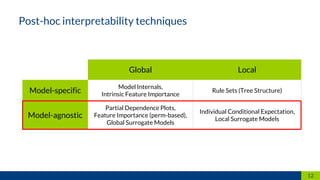

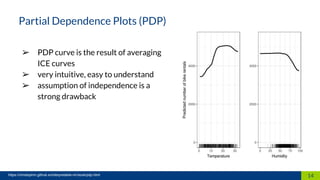




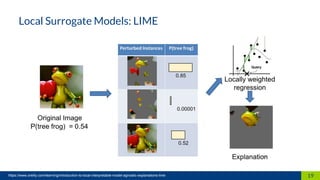




This document discusses machine learning interpretability. It defines interpretation as giving explanations to humans for machine learning models and decisions. It notes that humans create, are affected by, and demand explanations for decision systems. The document outlines different techniques for model interpretability including intrinsically interpretable models, post-hoc interpretability techniques that provide explanations for black box models, and model-specific and model-agnostic techniques. It provides examples like partial dependence plots, individual conditional expectation, and local surrogate models. It recommends choosing techniques based on the recipient and purpose of explanations.






















![Dimension reduction techniques[Feature Selection]](https://cdn.slidesharecdn.com/ss_thumbnails/dimensionreductiontechnibyaakankshajain-210625102243-thumbnail.jpg?width=640&height=640&fit=bounds)




























































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)



