Download as PDF, PPTX




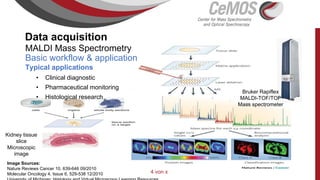
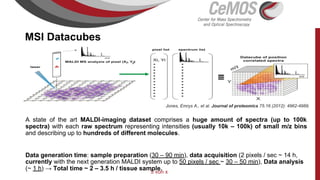

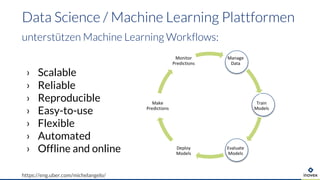
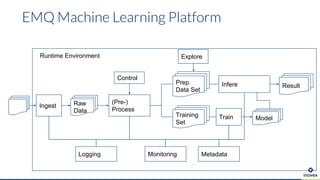
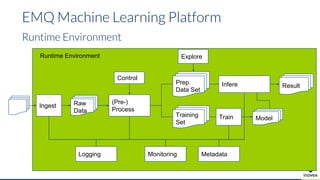

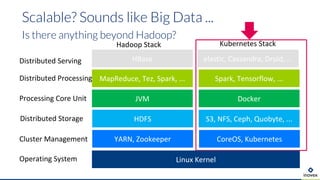





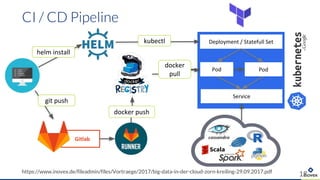
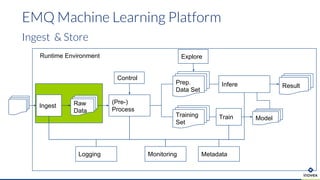
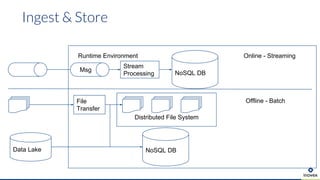
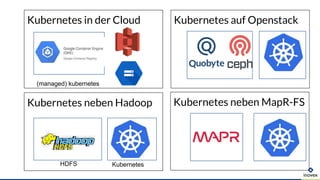
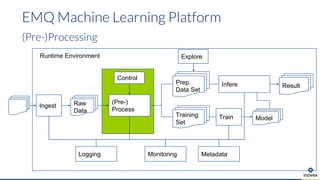
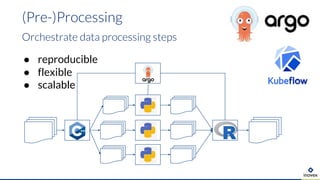
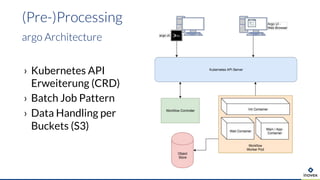
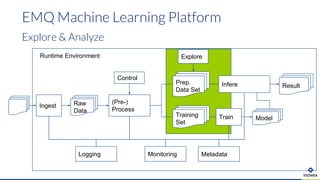

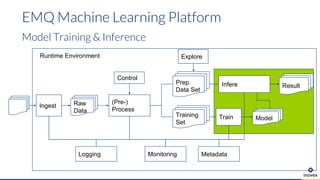

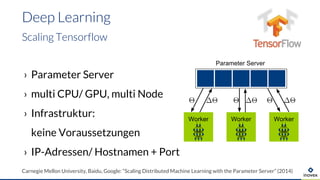

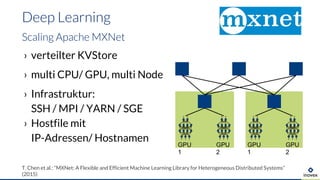


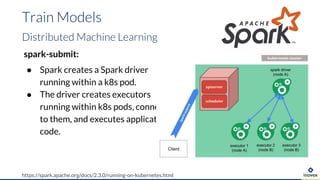
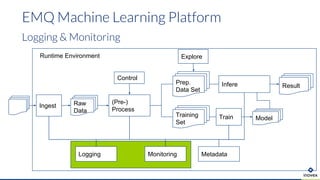

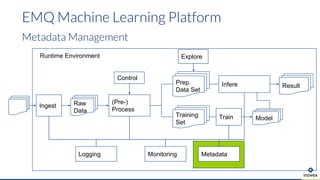
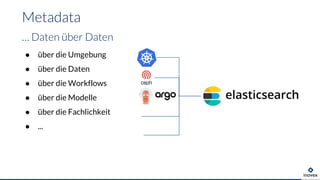
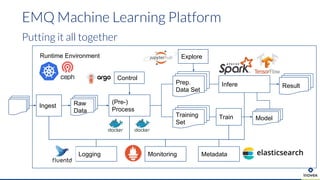
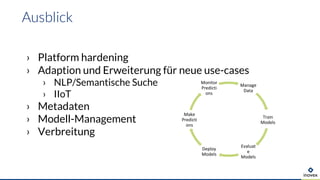



Die Präsentation behandelt die Nutzung von Data Science und Machine Learning im Kubernetes-Ökosystem, einschließlich spezifischer Anwendungsfälle wie der Bildgebung in der Massenspektrometrie. Die Autoren erörtern die Entwicklung von Workflows, die Nutzung verschiedener Tools und Komponenten sowie die Herausforderungen und Möglichkeiten beim Einsatz von Kubernetes für maschinelles Lernen. Ein Ausblick wird auf zukünftige Projekte und Anwendungen gegeben, wobei betont wird, dass Flexibilität, Skalierbarkeit und Benutzerfreundlichkeit entscheidend sind.























































































