Downloaded 27 times




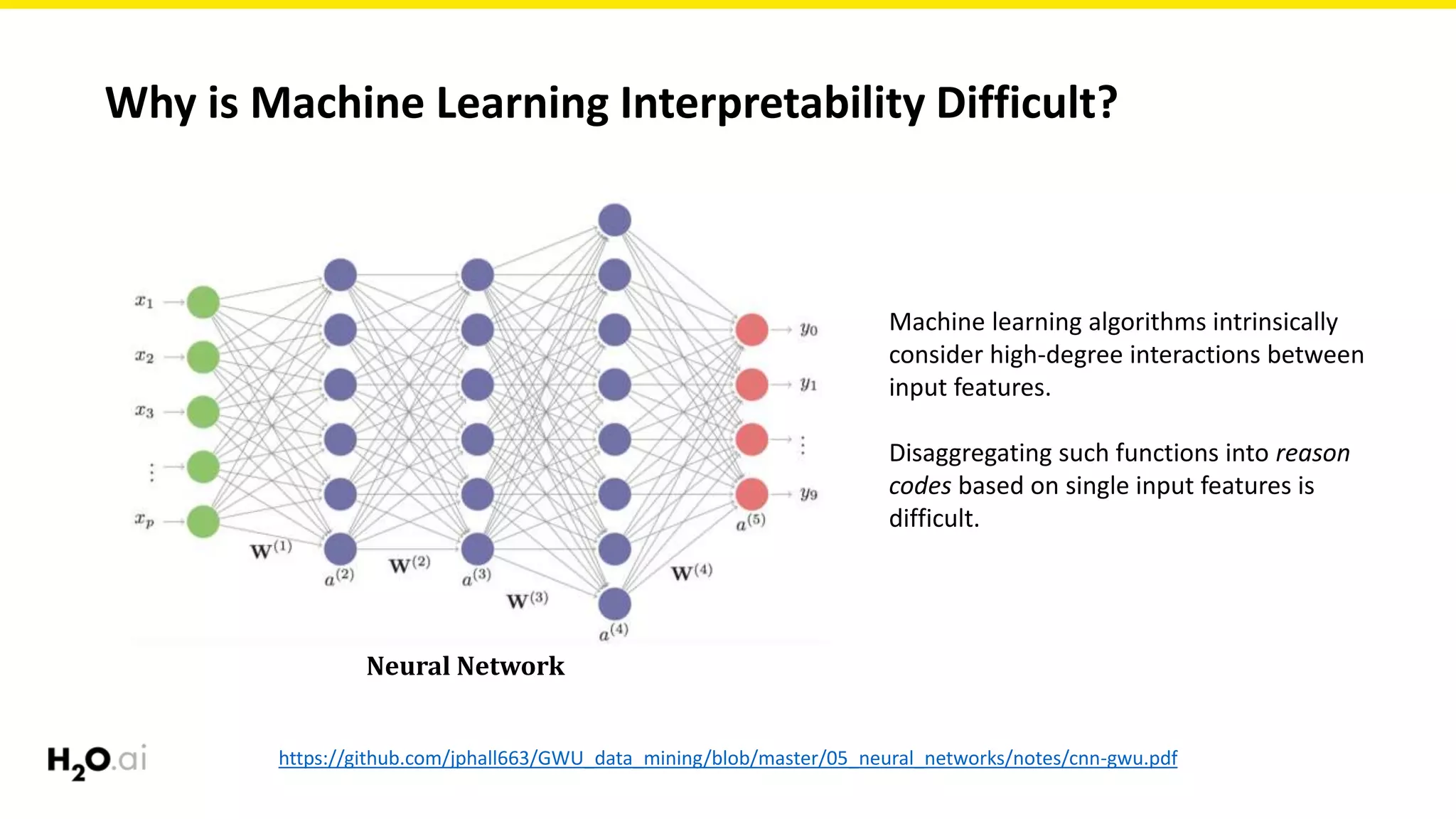

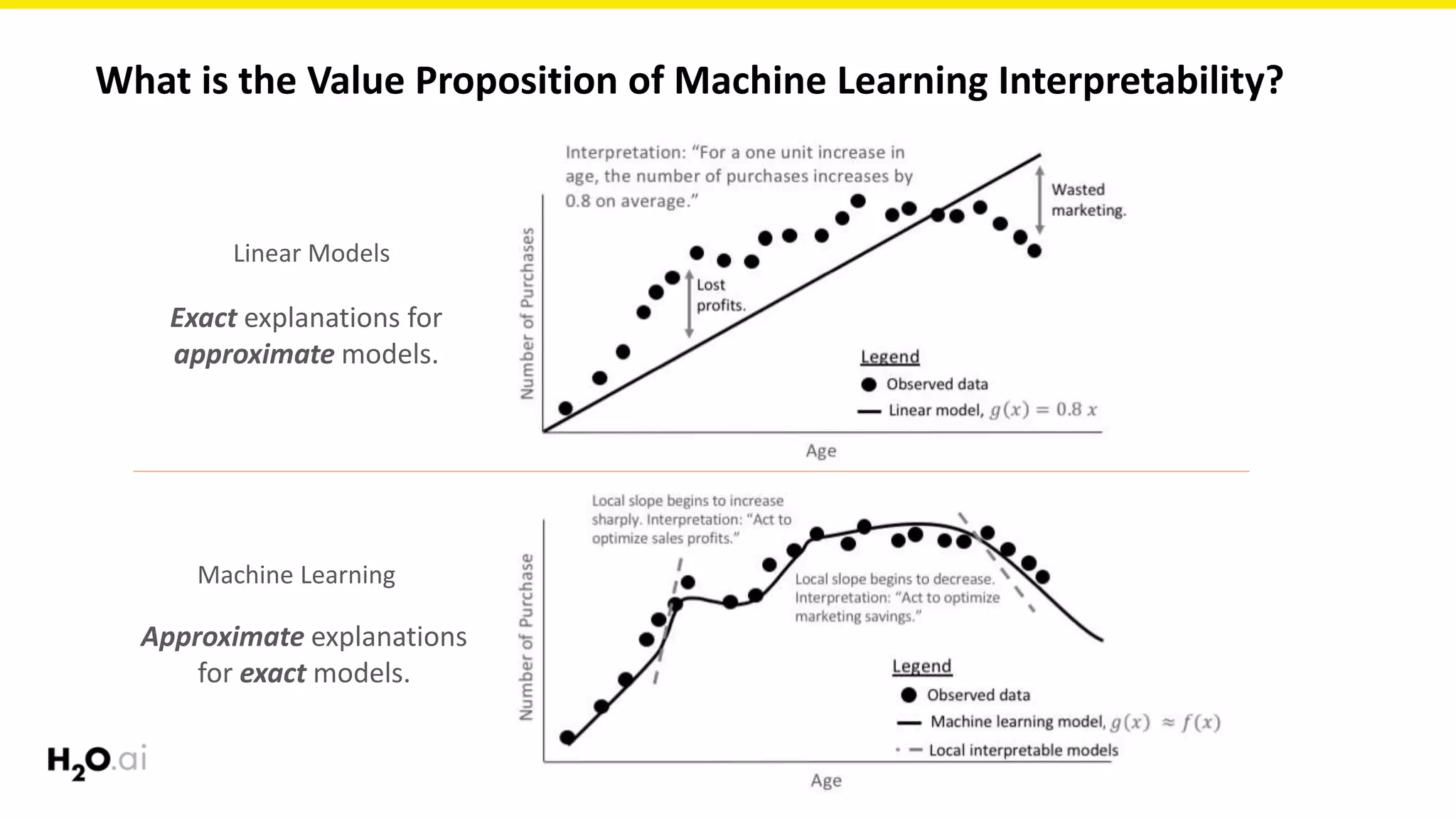


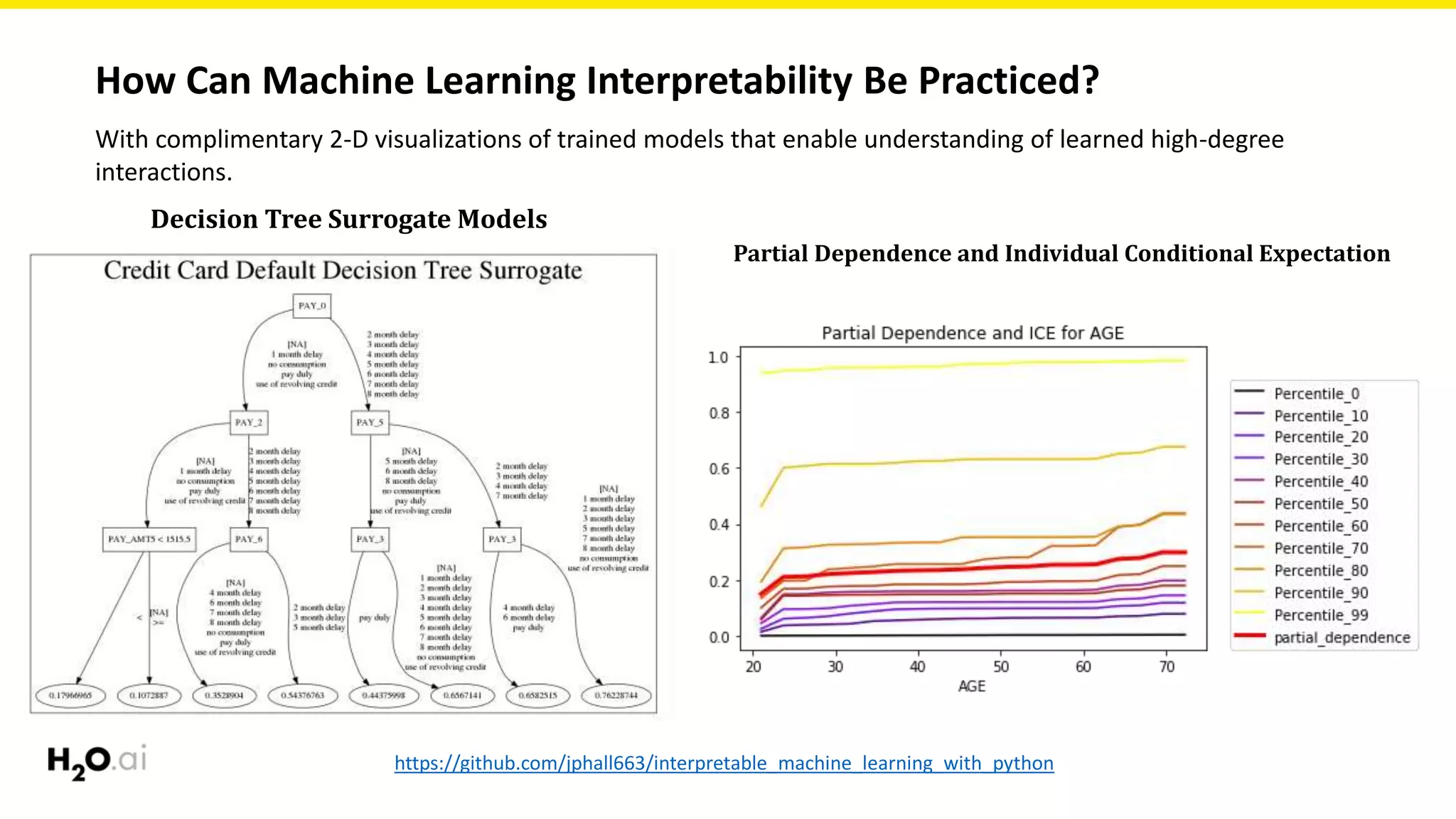
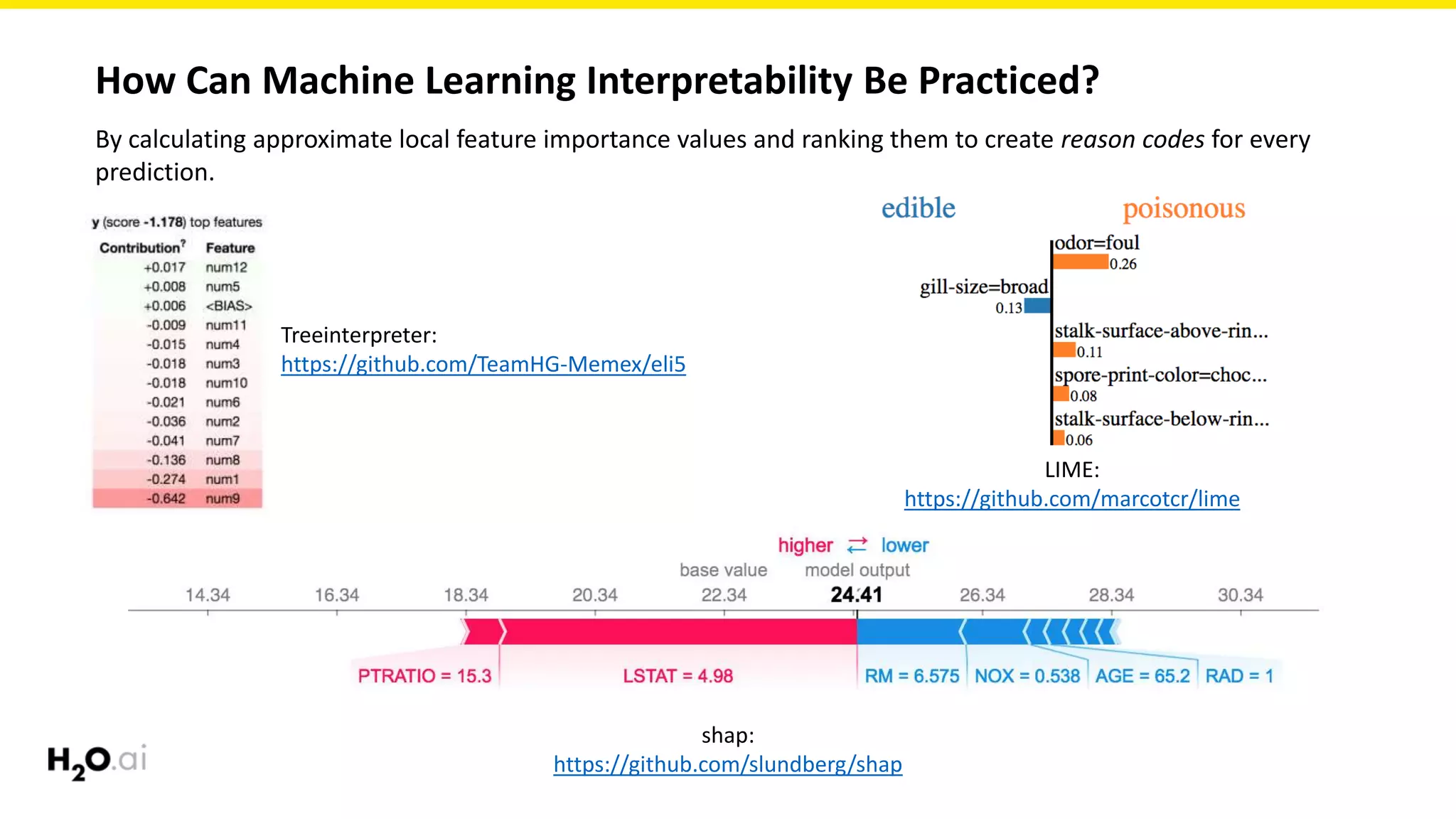








The document discusses machine learning interpretability, emphasizing its significance for both social and commercial reasons, such as regulatory compliance and improved decision-making. It explores the complexities involved in achieving interpretability due to the intricate nature of machine learning models and offers practical approaches to enhance understanding through various modeling techniques and visualization methods. Additionally, it outlines the importance of testing interpretability mechanisms to ensure reliability and robustness in explanations.























































































