Downloaded 13 times




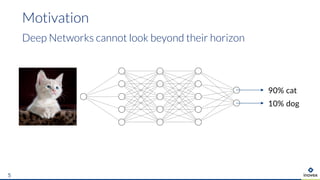
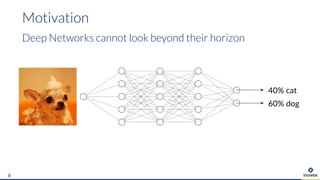
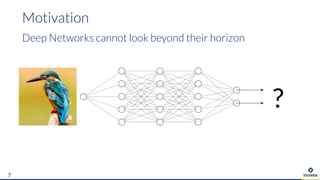

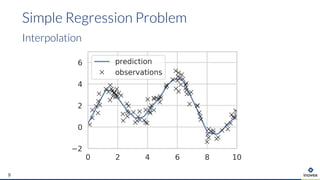
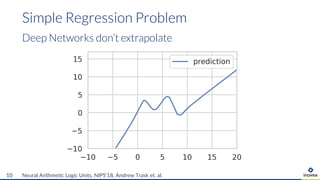
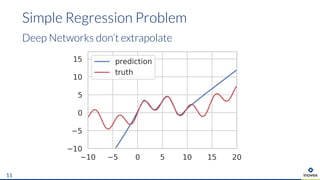
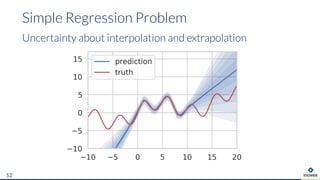
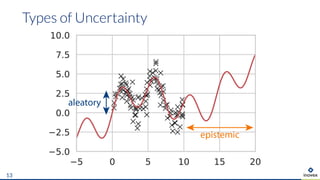




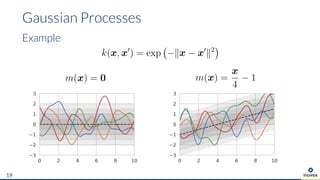
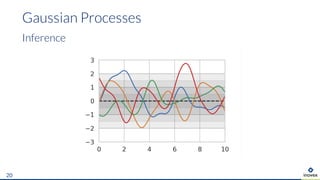
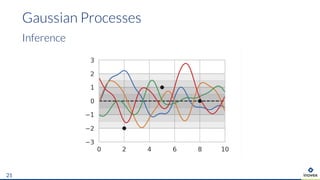
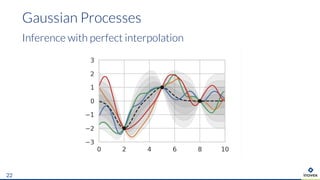
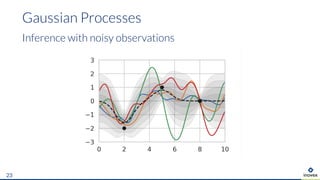


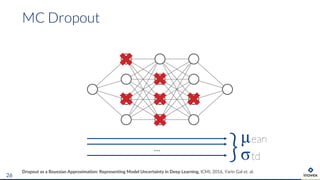


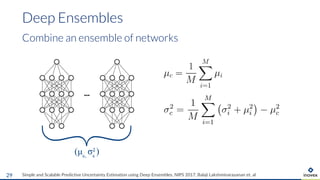

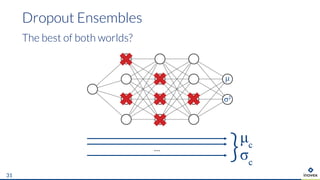


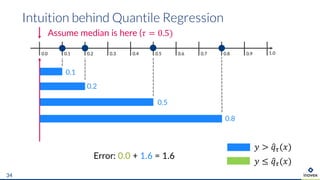
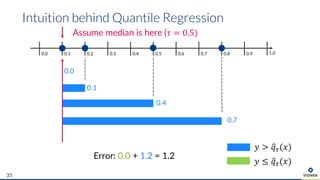
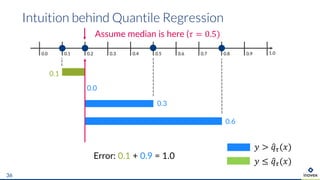





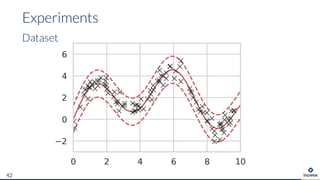


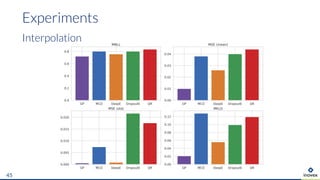
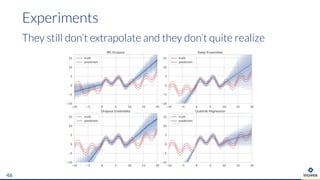
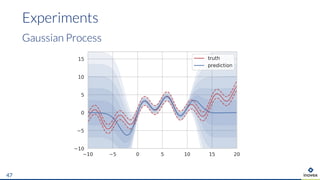
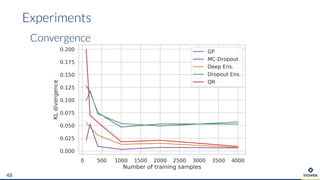
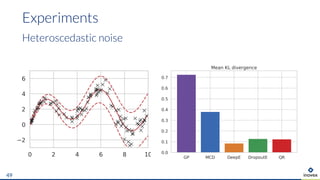
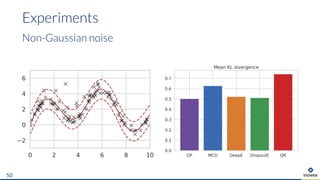
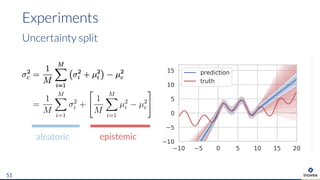
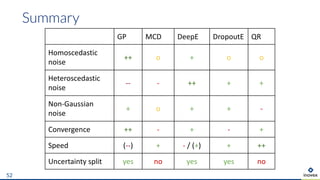





The document presents an overview of uncertainty quantification methods in artificial intelligence, focusing on deep learning techniques such as Gaussian processes, Monte Carlo dropout, and deep ensembles. It discusses the limitations of deep networks in extrapolation and the significance of estimating both aleatory and epistemic uncertainties. The conclusion emphasizes the need for developing combined solutions that effectively address uncertainty estimation in critical applications.
![[PR12] understanding deep learning requires rethinking generalization](https://cdn.slidesharecdn.com/ss_thumbnails/pr12understandingdeeplearningrequiresrethinkinggeneralization-180121135850-thumbnail.jpg?width=640&height=640&fit=bounds)


![[PR12] intro. to gans jaejun yoo](https://cdn.slidesharecdn.com/ss_thumbnails/pr12intro-170416162251-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]Conditional Neural Processes](https://cdn.slidesharecdn.com/ss_thumbnails/conditionalneuralprocesses-180727001730-thumbnail.jpg?width=640&height=640&fit=bounds)


















































