Download as PDF, PPTX











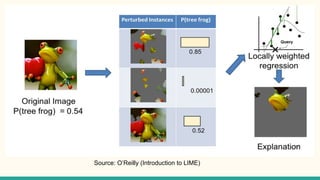



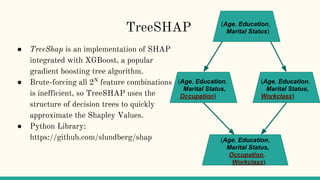
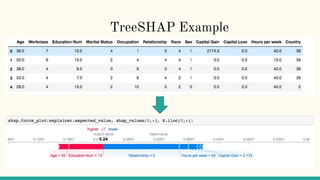







1. Interpretability helps understand complex machine learning models by explaining their outcomes based on inputs. Higher predictive accuracy often reduces interpretability. 2. Methods like LIME and SHAP attribute model outcomes to input features through local surrogate models and game theory. 3. Recourse analysis identifies actions individuals could take to improve outcomes from automated decisions.



































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)