Downloaded 34 times







![Python Code
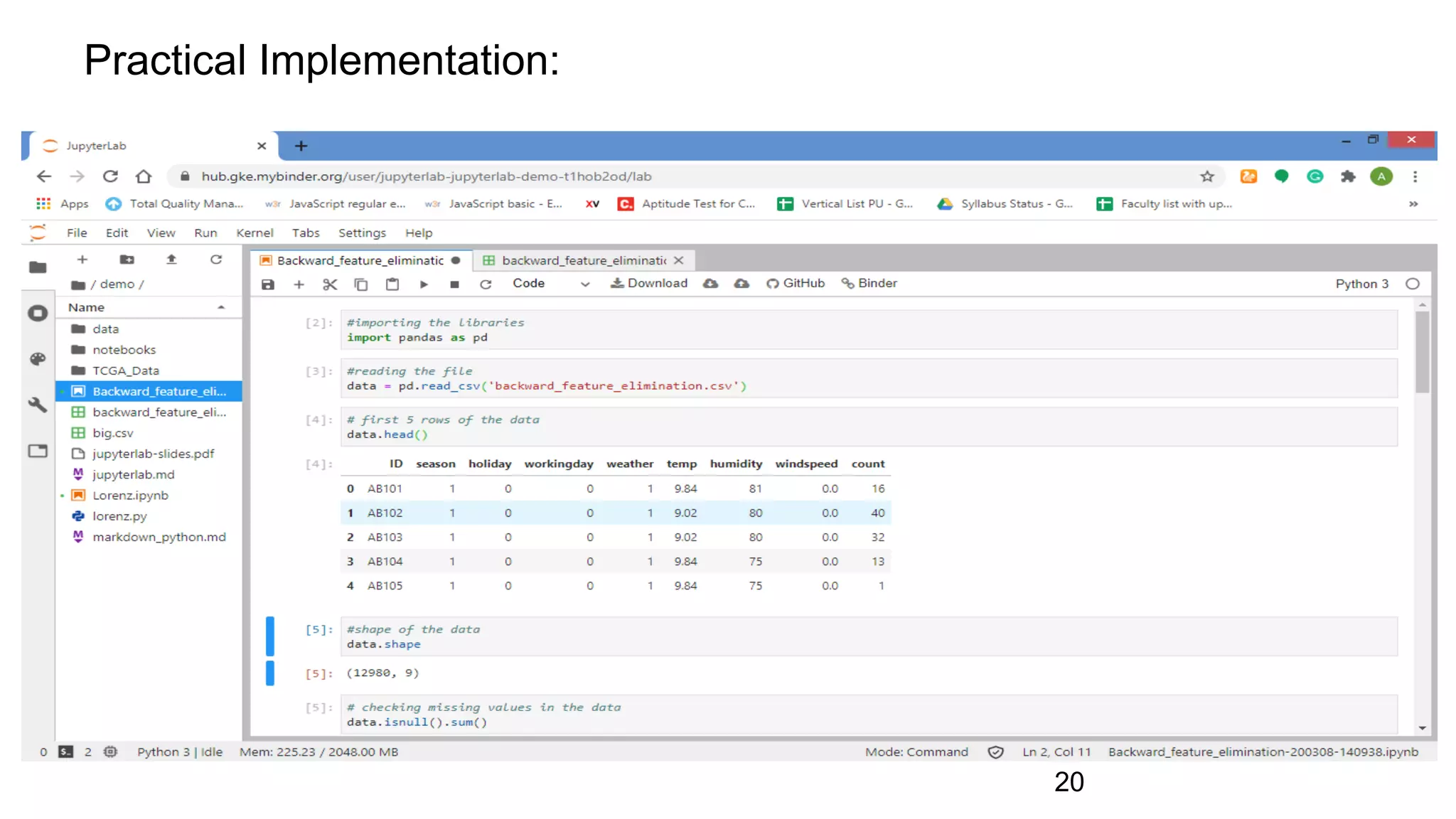
#importing the libraries
import pandas as pd
#reading the file
data = pd.read_csv('backward_feature_elimination.csv')
# first 5 rows of the data
data.head()
#shape of the data
data.shape
# creating the training data
X = data.drop(['ID', 'count'], axis=1)
y = data['count']
#Checking Shape
X.shape, y.shape
#Installation of MlEXTEND
!pip install mlxtend](https://image.slidesharecdn.com/dimensionreductiontechnibyaakankshajain-210625102243/75/Dimension-reduction-techniques-Feature-Selection-16-2048.jpg)
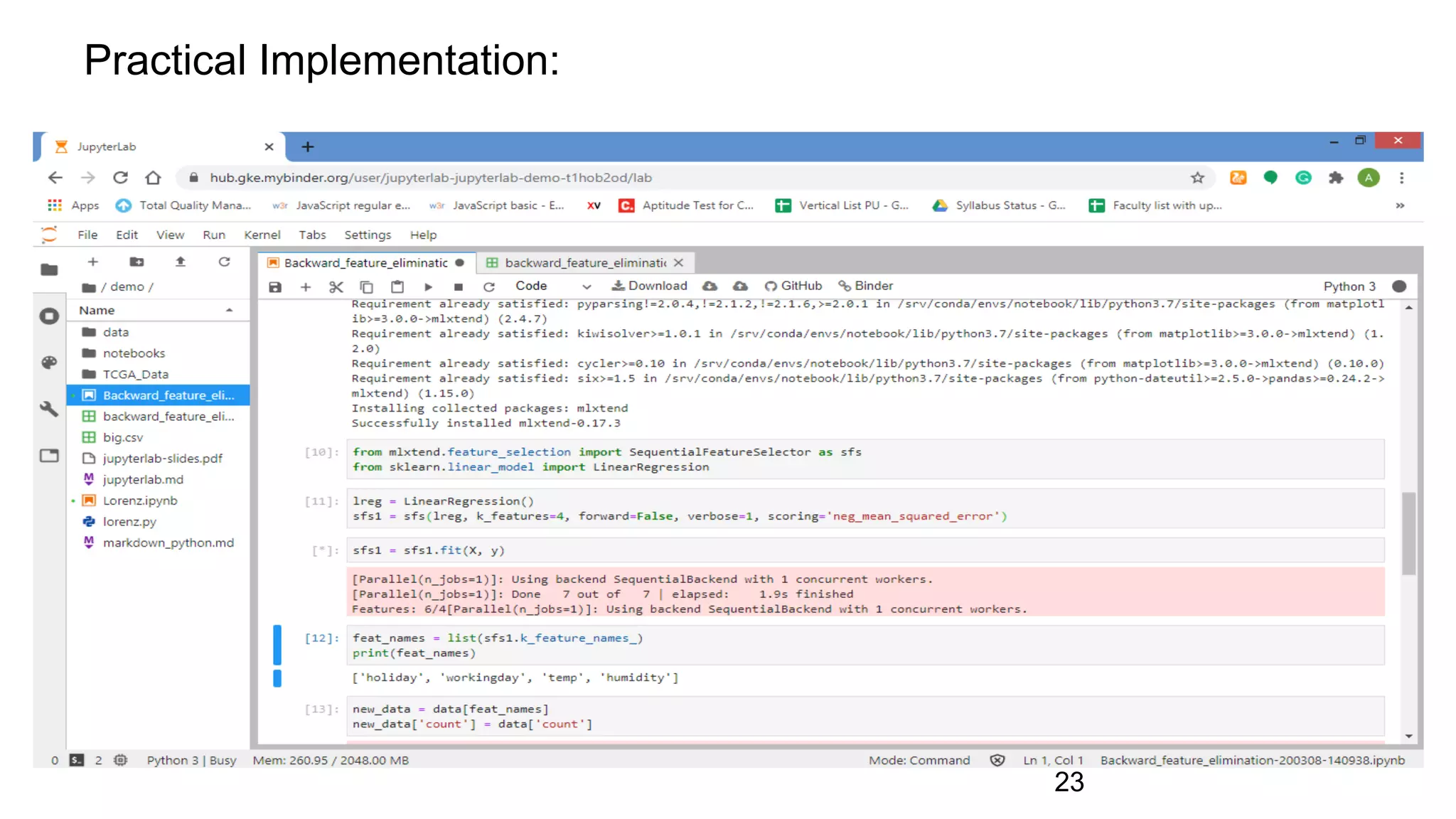
![Python Code
#importing the libraries
from mlxtend.feature_selection import SequentialFeatureSelector as sfs
from sklearn.linear_model import LinearRegression
#Setting parameters to apply Backward Feature Elimination
lreg = LinearRegression()
sfs1 = sfs(lreg, k_features=4, forward=False, verbose=1, scoring='neg_mean_squared_error')
#Apply Backward Feature Elimination
sfs1 = sfs1.fit(X, y)
#Checking selected features
feat_names = list(sfs1.k_feature_names_)
print(feat_names)
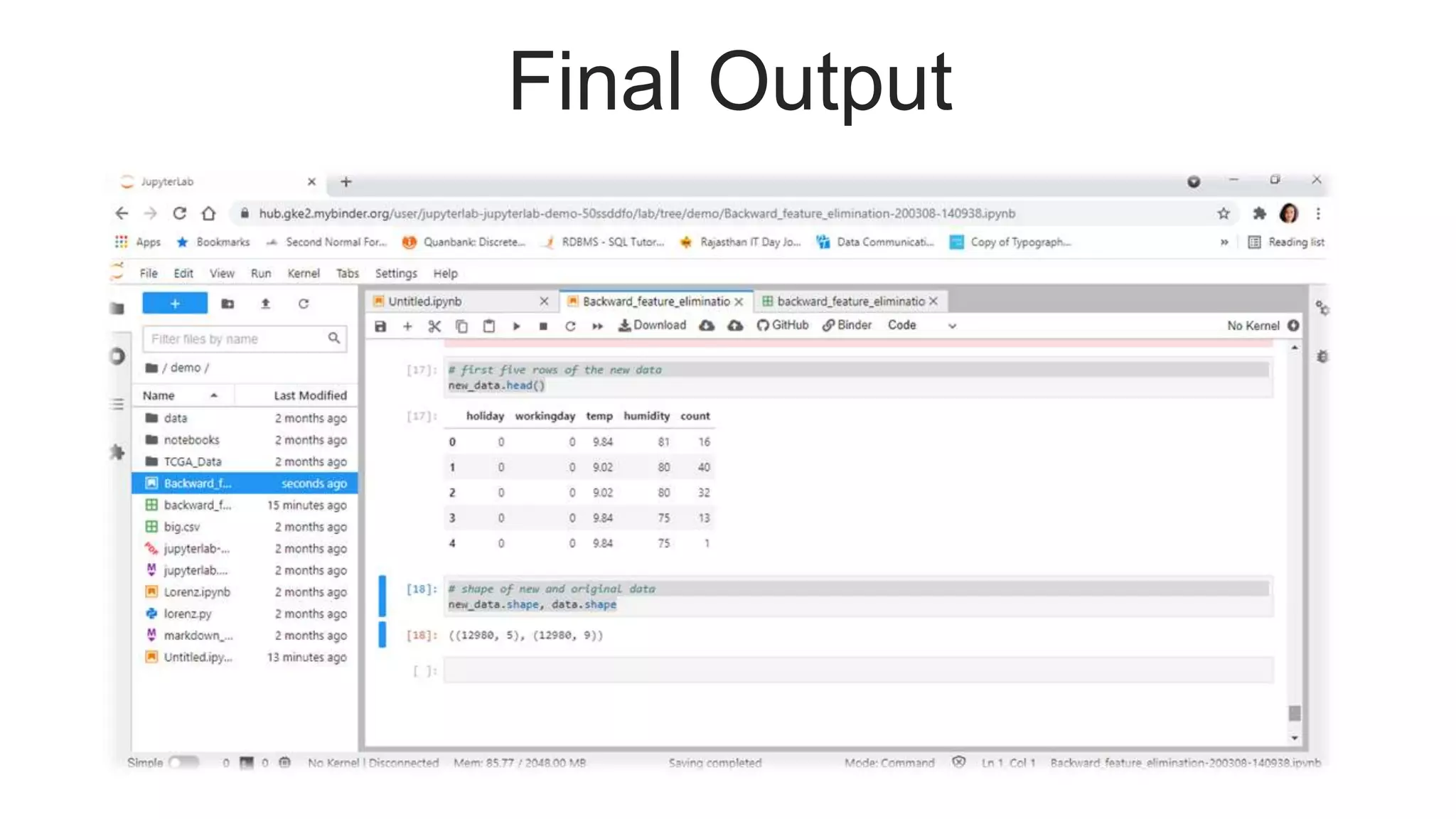
#Setting new dataframe
new_data = data[feat_names]
new_data['count'] = data['count']](https://image.slidesharecdn.com/dimensionreductiontechnibyaakankshajain-210625102243/75/Dimension-reduction-techniques-Feature-Selection-17-2048.jpg)








The document discusses dimensionality reduction techniques by Ms. Aakanksha Jain, focusing on feature selection and extraction, specifically highlighting backward feature elimination and forward feature selection. It emphasizes the importance of dimension reduction in data analysis and machine learning, demonstrating the concepts with practical Python implementations. The document also includes a hands-on session showcasing a dataset and utilizing specific Python libraries for feature selection.
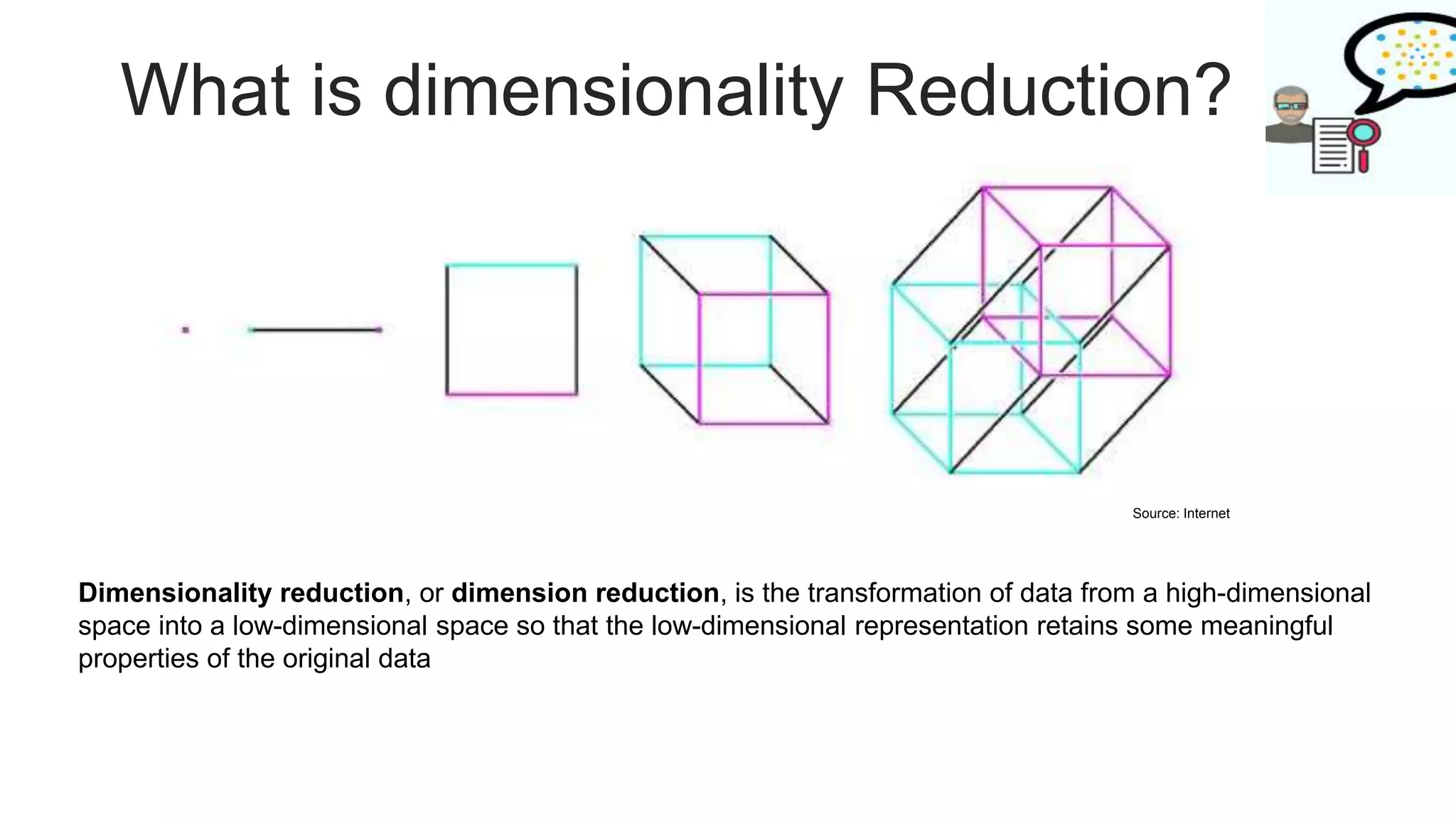
Introduces dimensionality reduction and emphasizes its significance in machine learning.
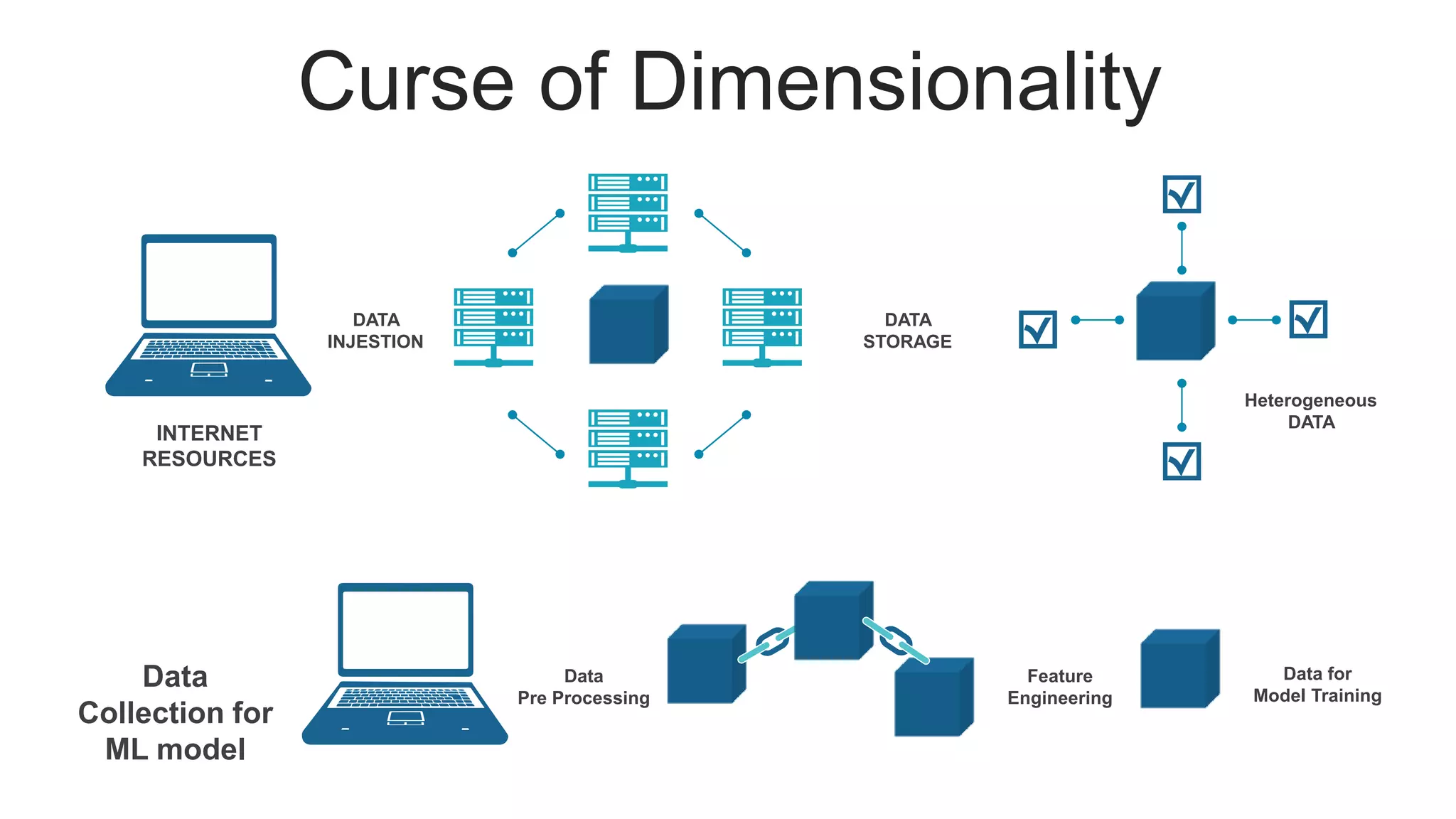
Defines dimensionality reduction and presents the curse of dimensionality related to data analysis.
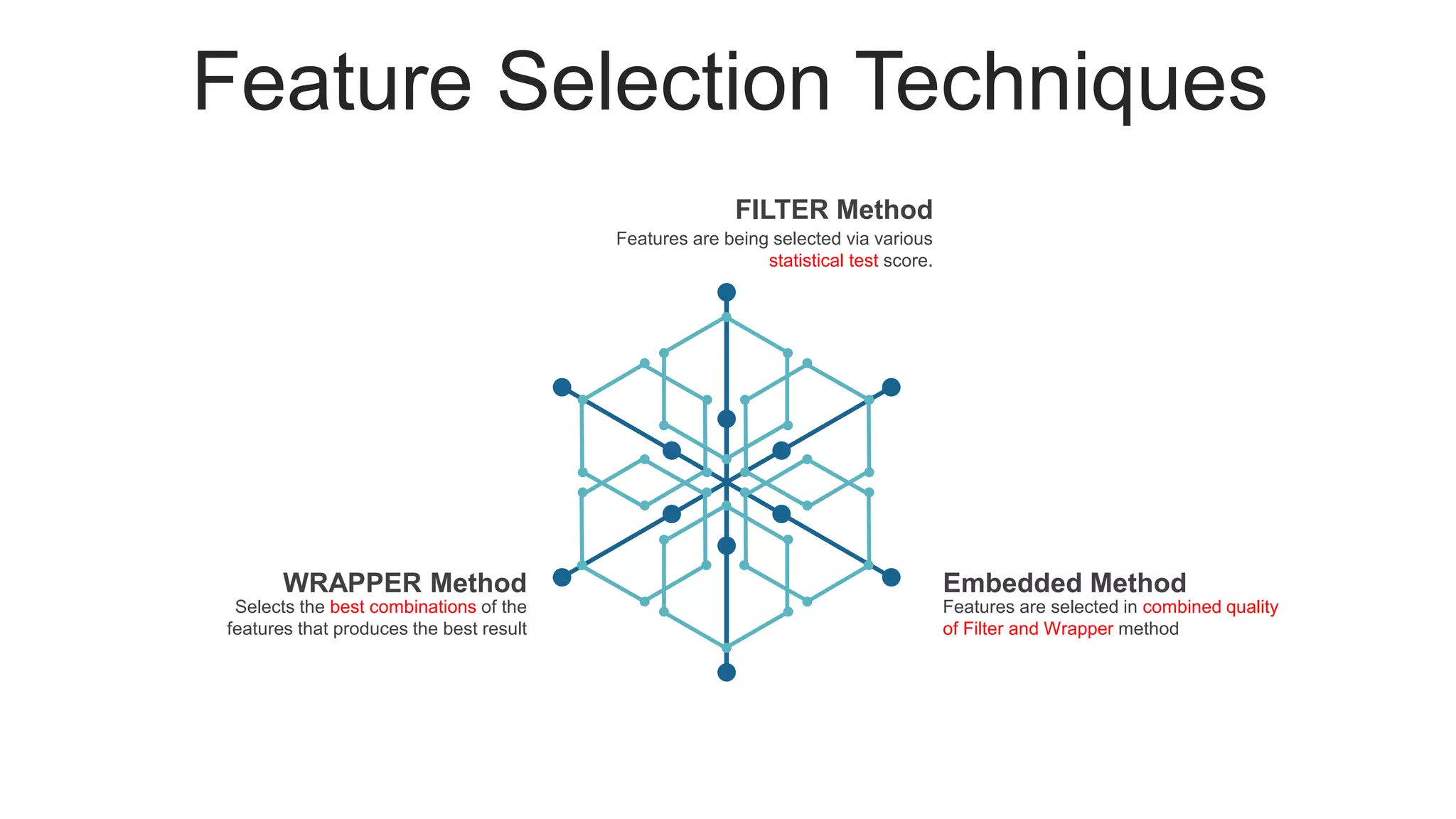
Explains feature extraction and selection methods, including embedded, wrapper, and filter techniques.
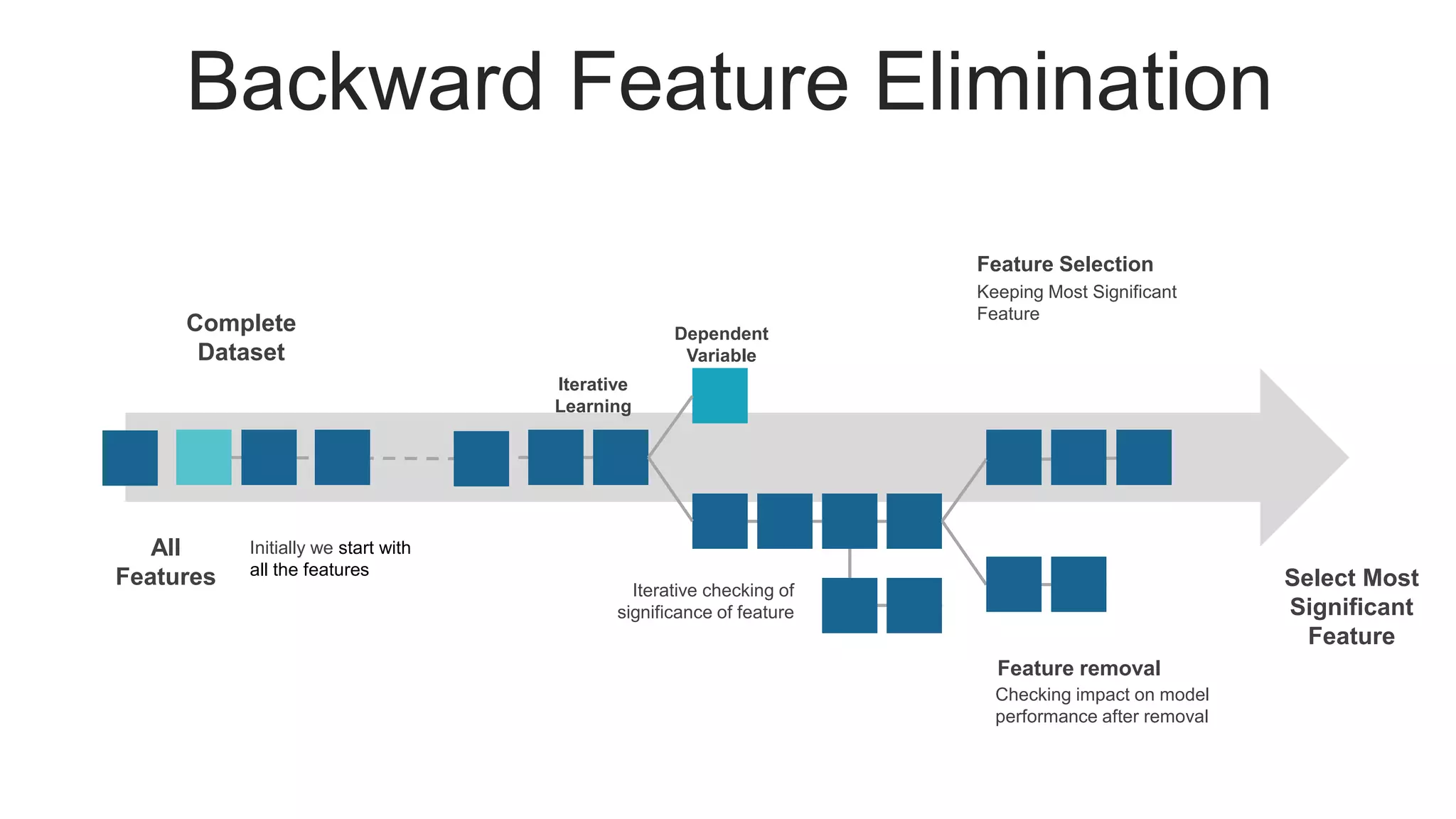
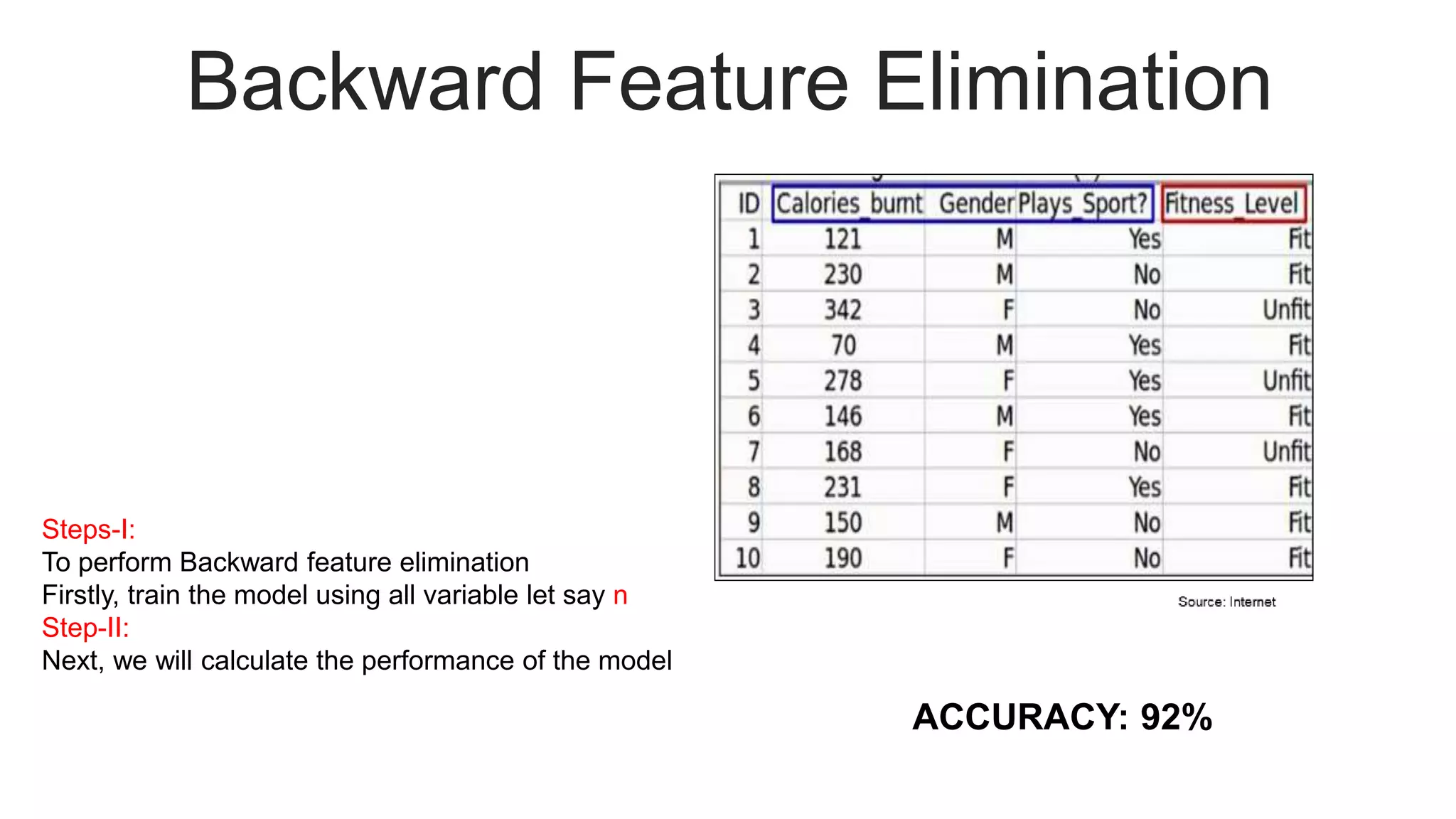
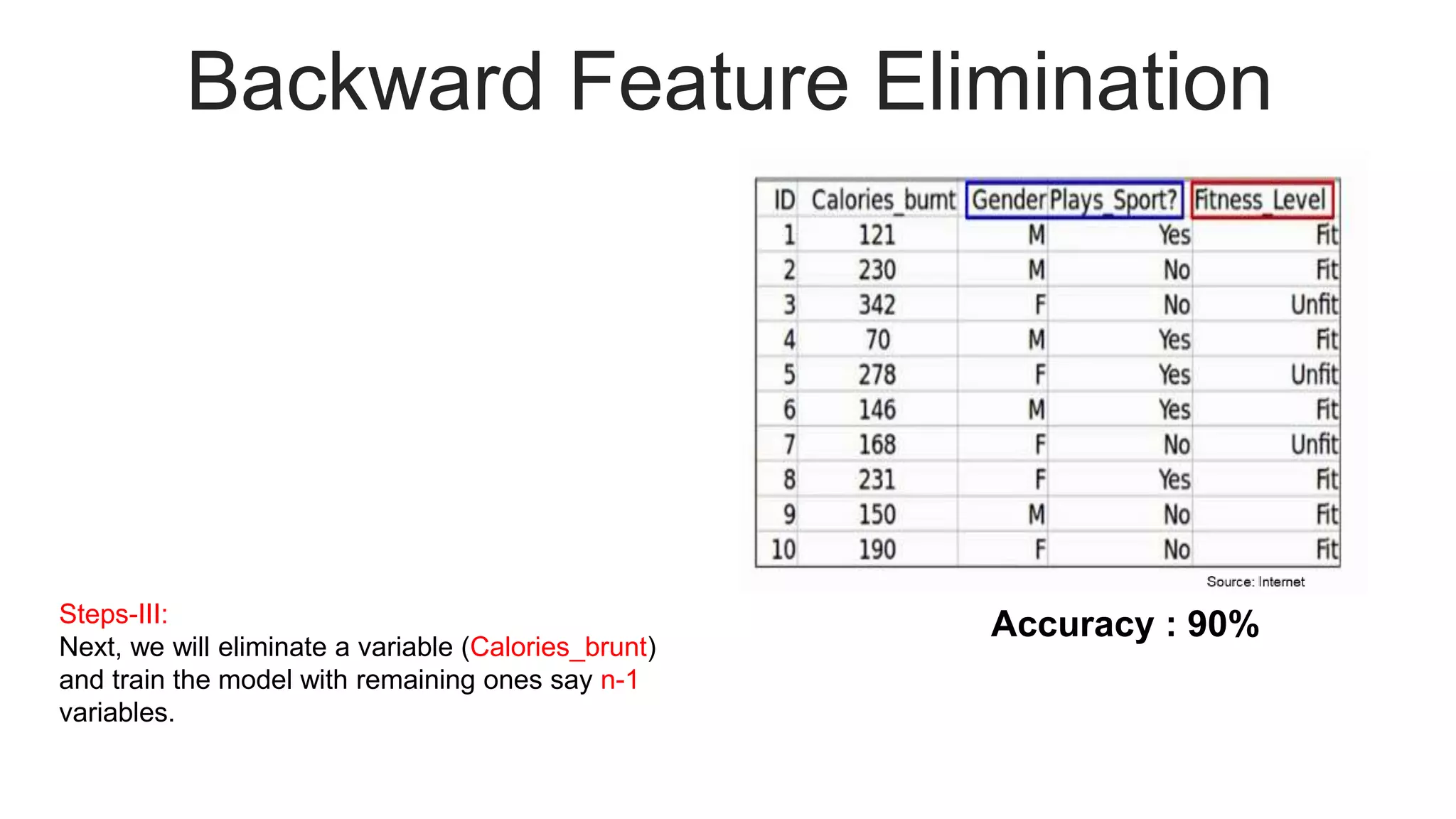
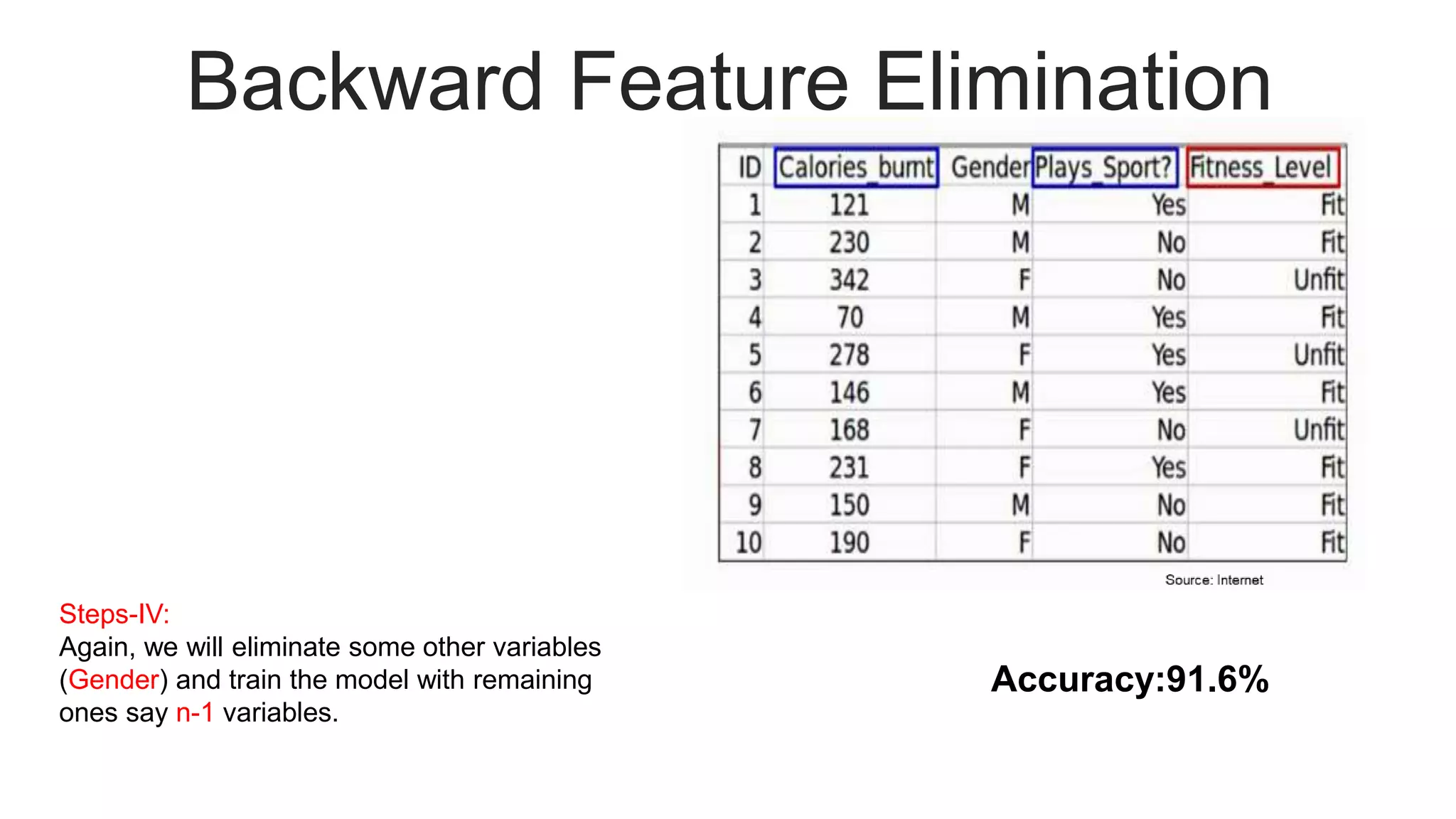
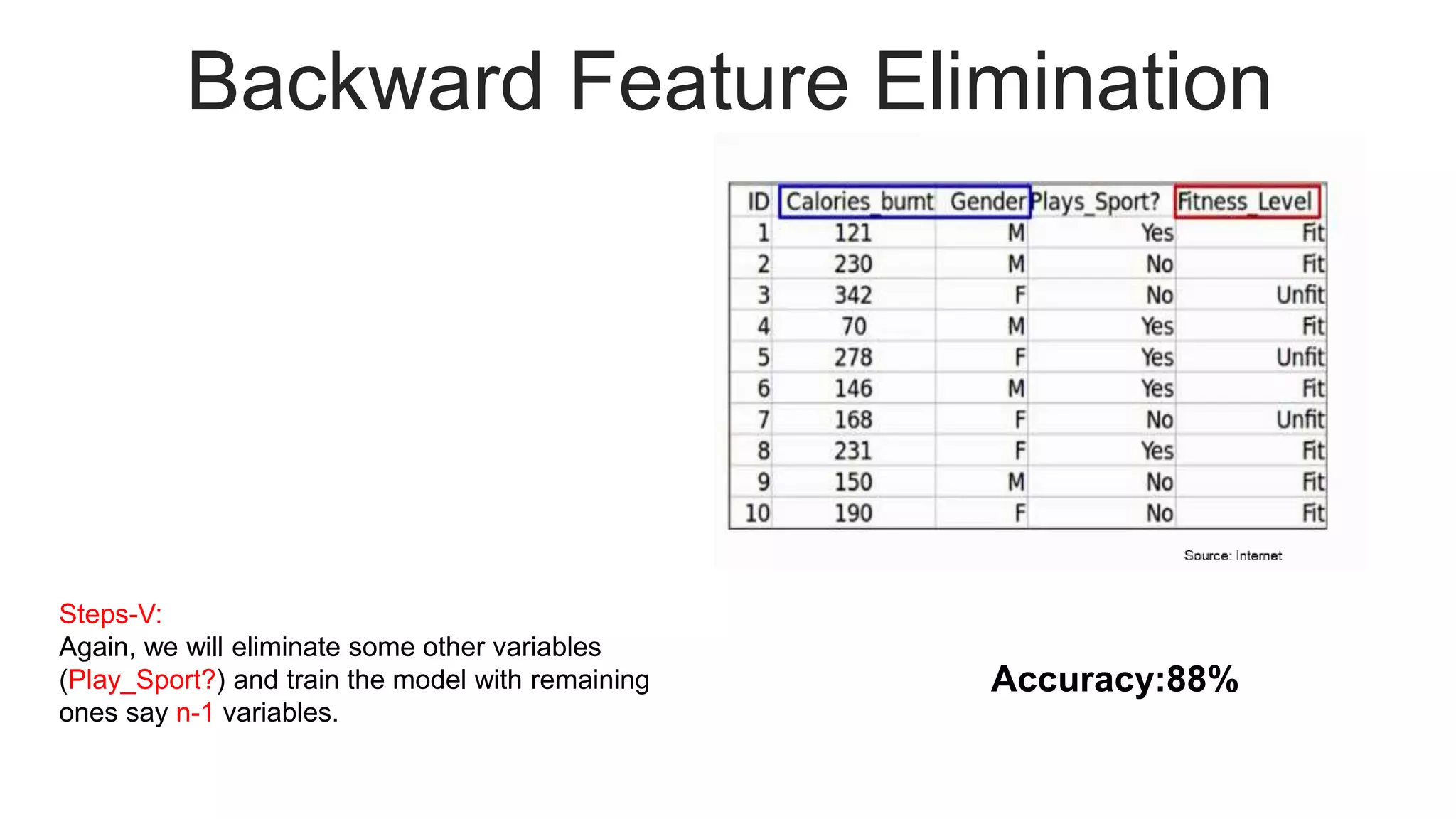
Illustrates the process of backward feature elimination with assumptions and detailed steps, including accuracy results.
Presents a sample dataset for practical application of feature selection techniques.
Demonstrates Python code for implementing backward feature elimination using a sample dataset.
Continues with multiple practical implementation slides to convey hands-on experience.
Concludes the presentation with the final output and thanks attendees.















































































