Download as PDF, PPTX






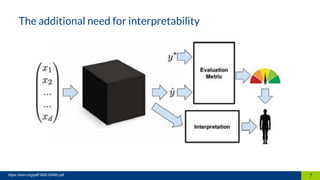



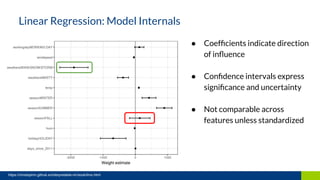

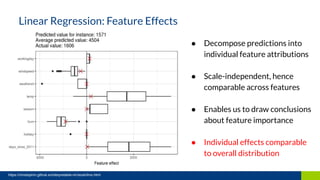

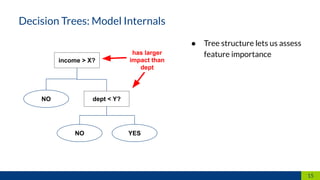
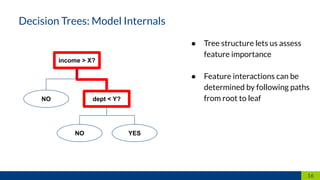




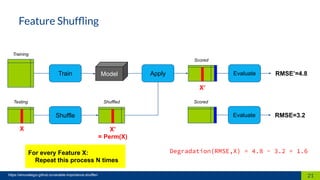

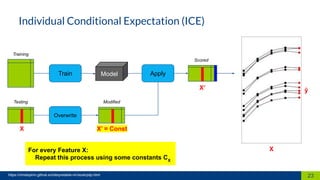












The document discusses the importance of interpretability in machine learning models, emphasizing the need for models to be understandable to humans and to avoid biases in decision-making. It highlights techniques for achieving interpretability, including using intrinsically interpretable models like linear regression and decision trees, as well as post-hoc methods. The conclusion stresses that transparency in models is crucial for building trust and acceptance in AI systems.


















































































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)




