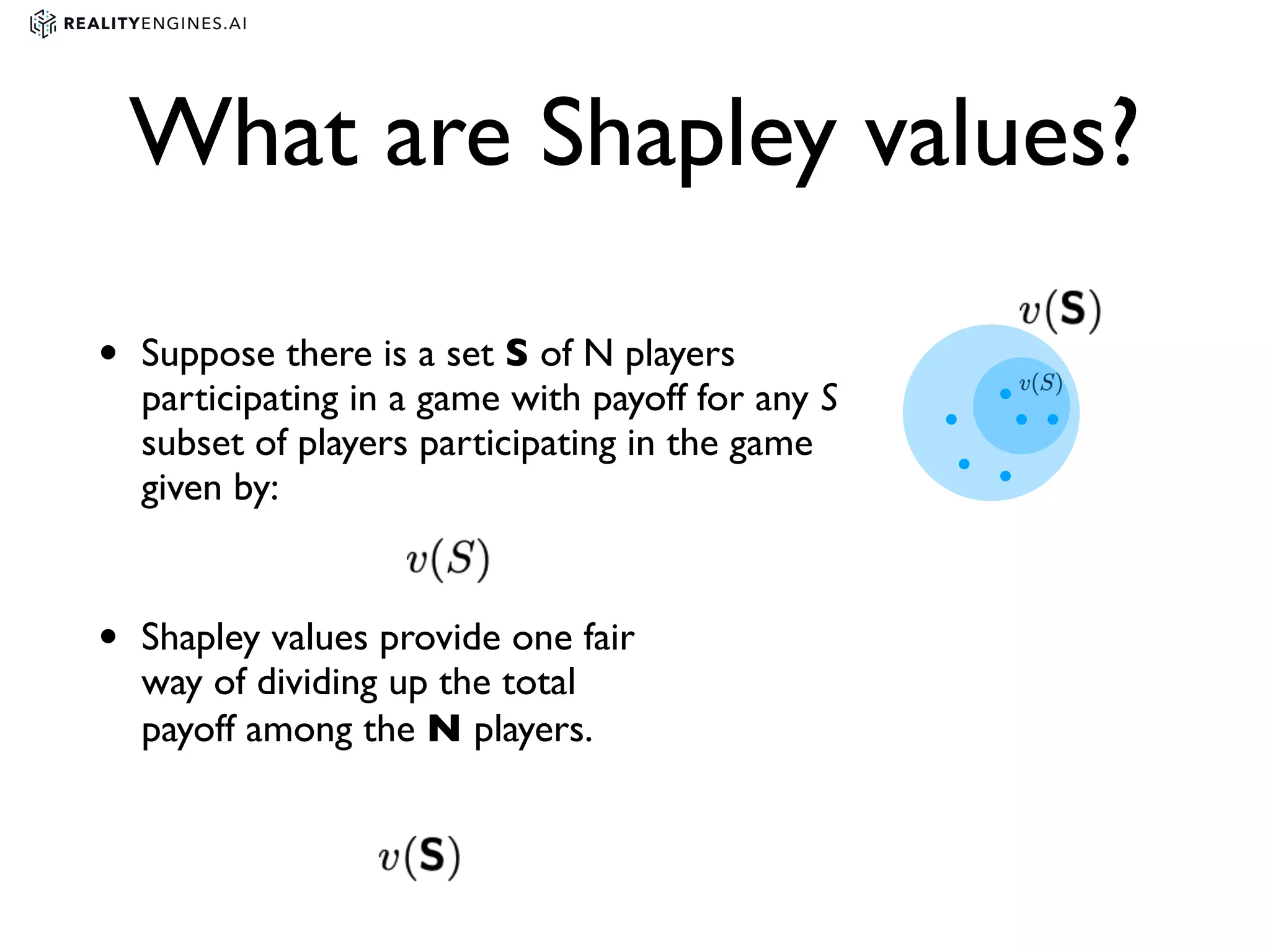The document discusses explainability and bias in machine learning/AI models. It covers several topics:
1. Why explainability of models is important, including for laypeople using models and potential legal needs for explanations of decisions.
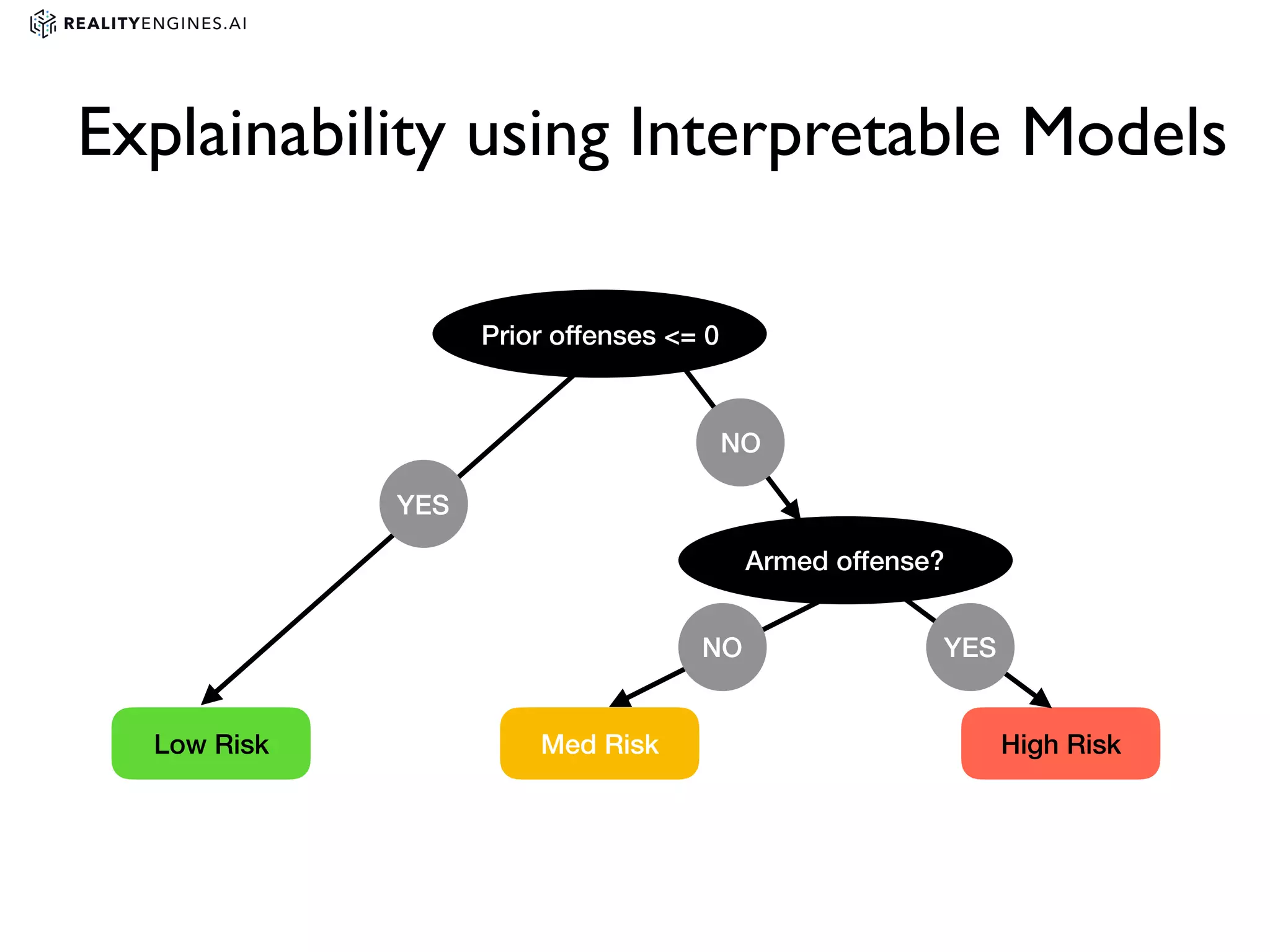
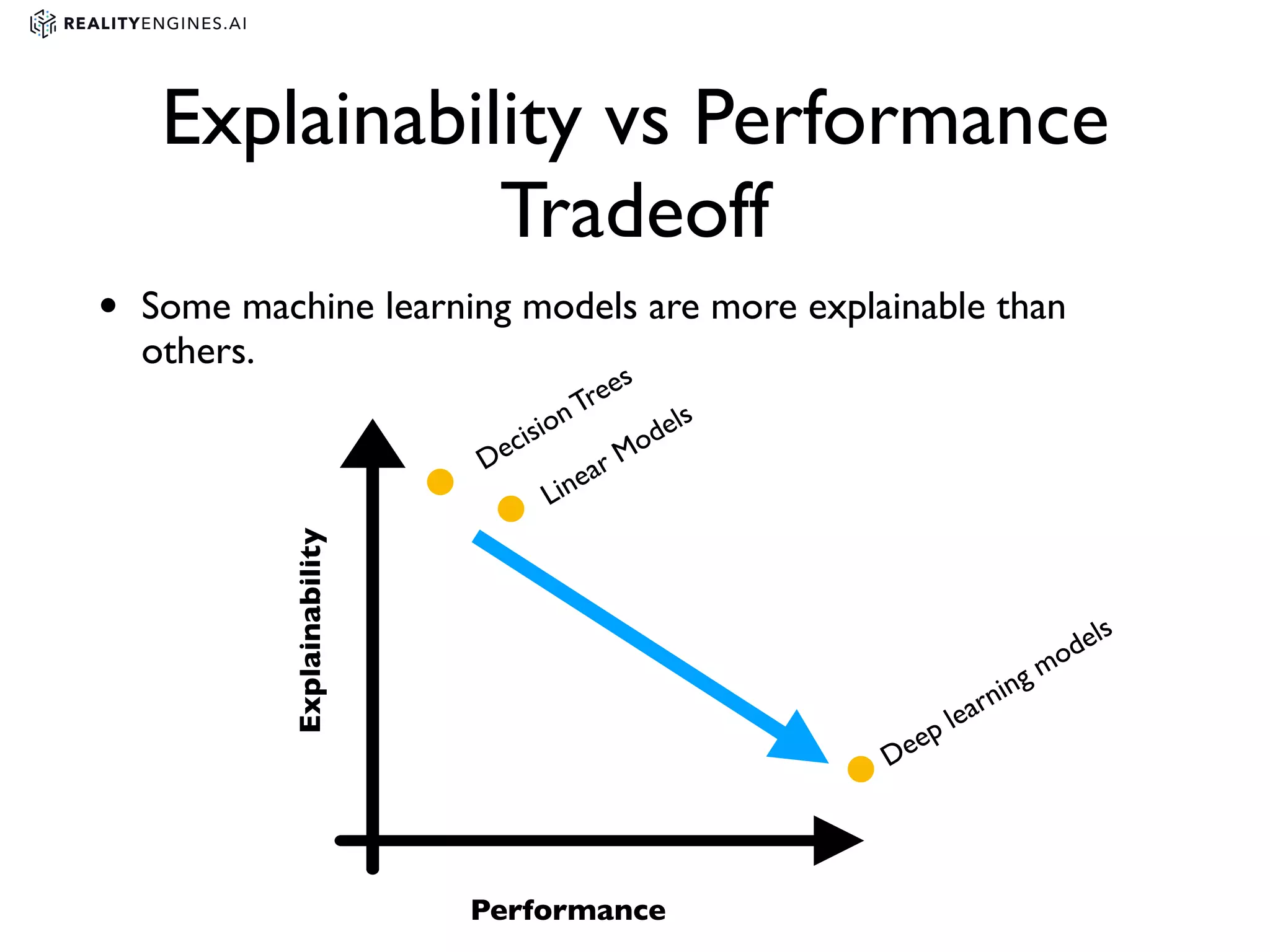
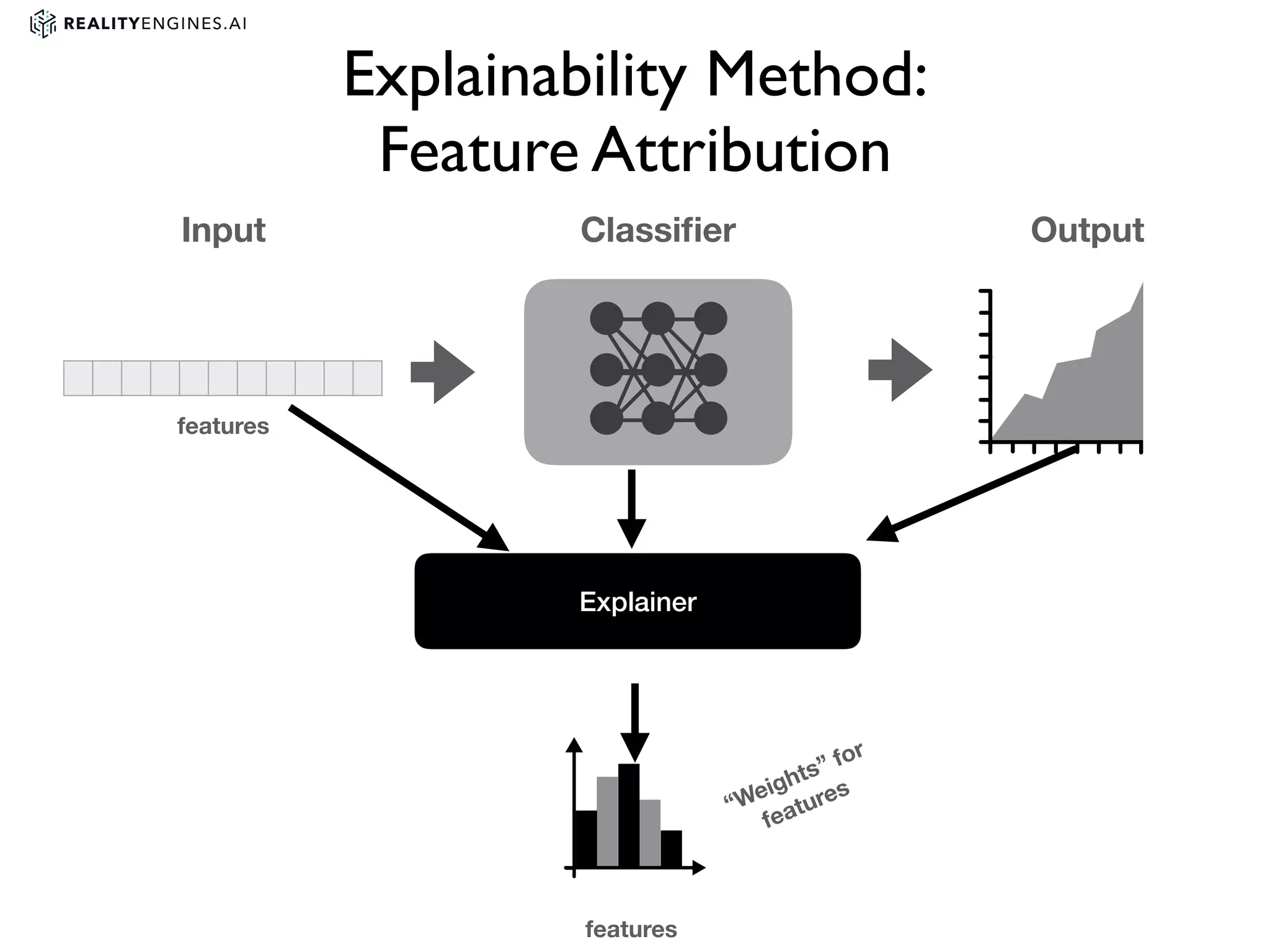
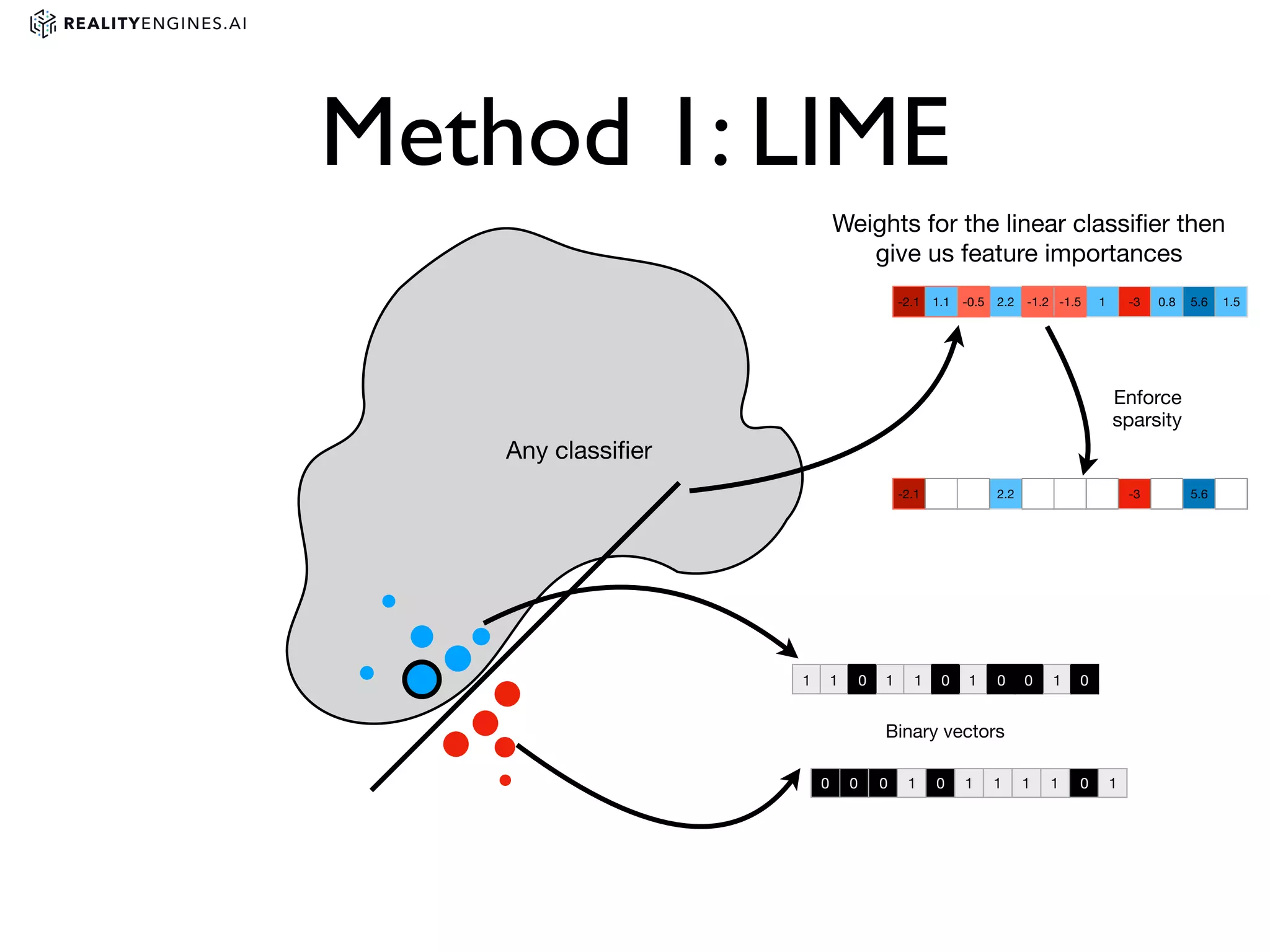
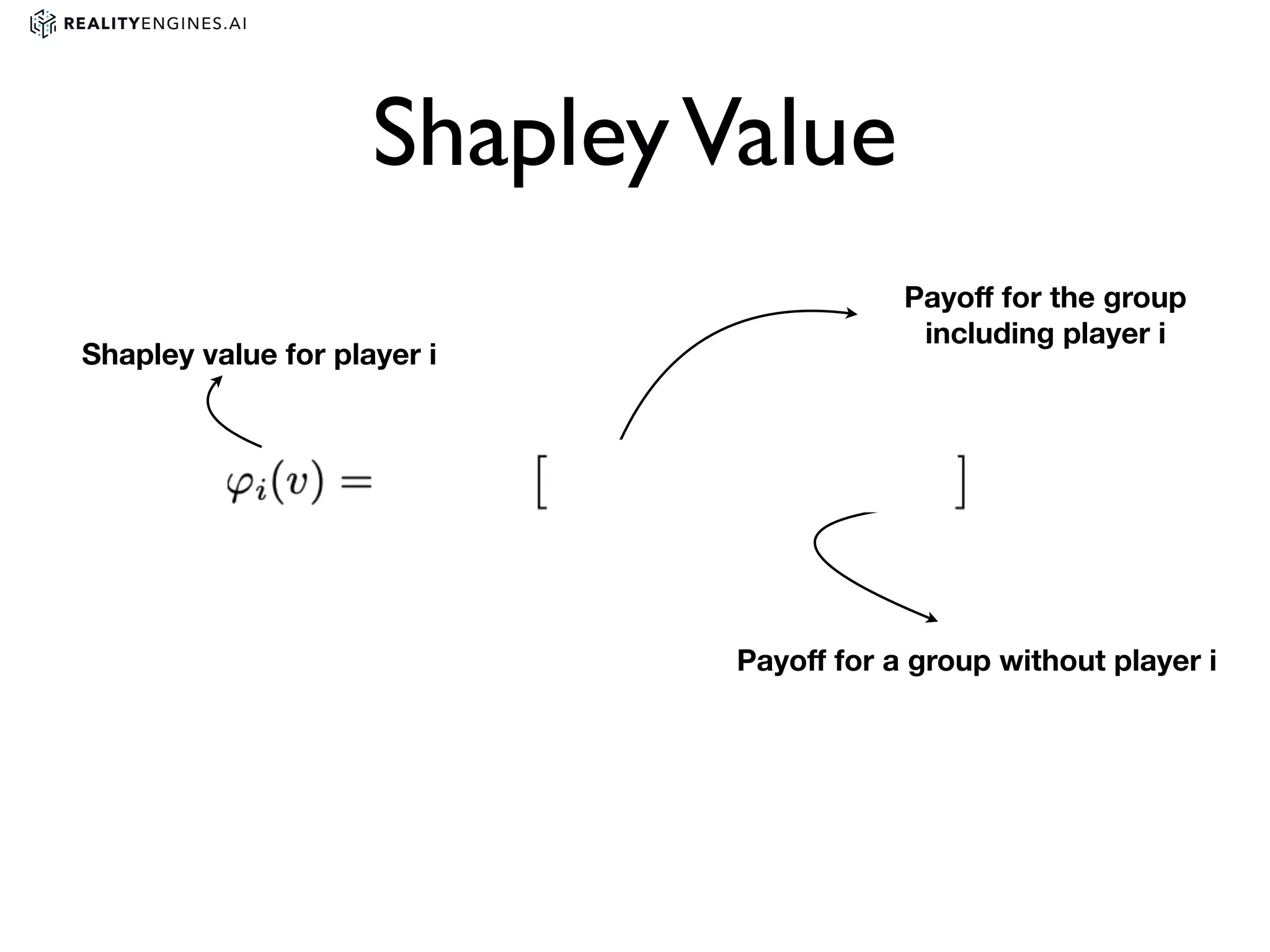
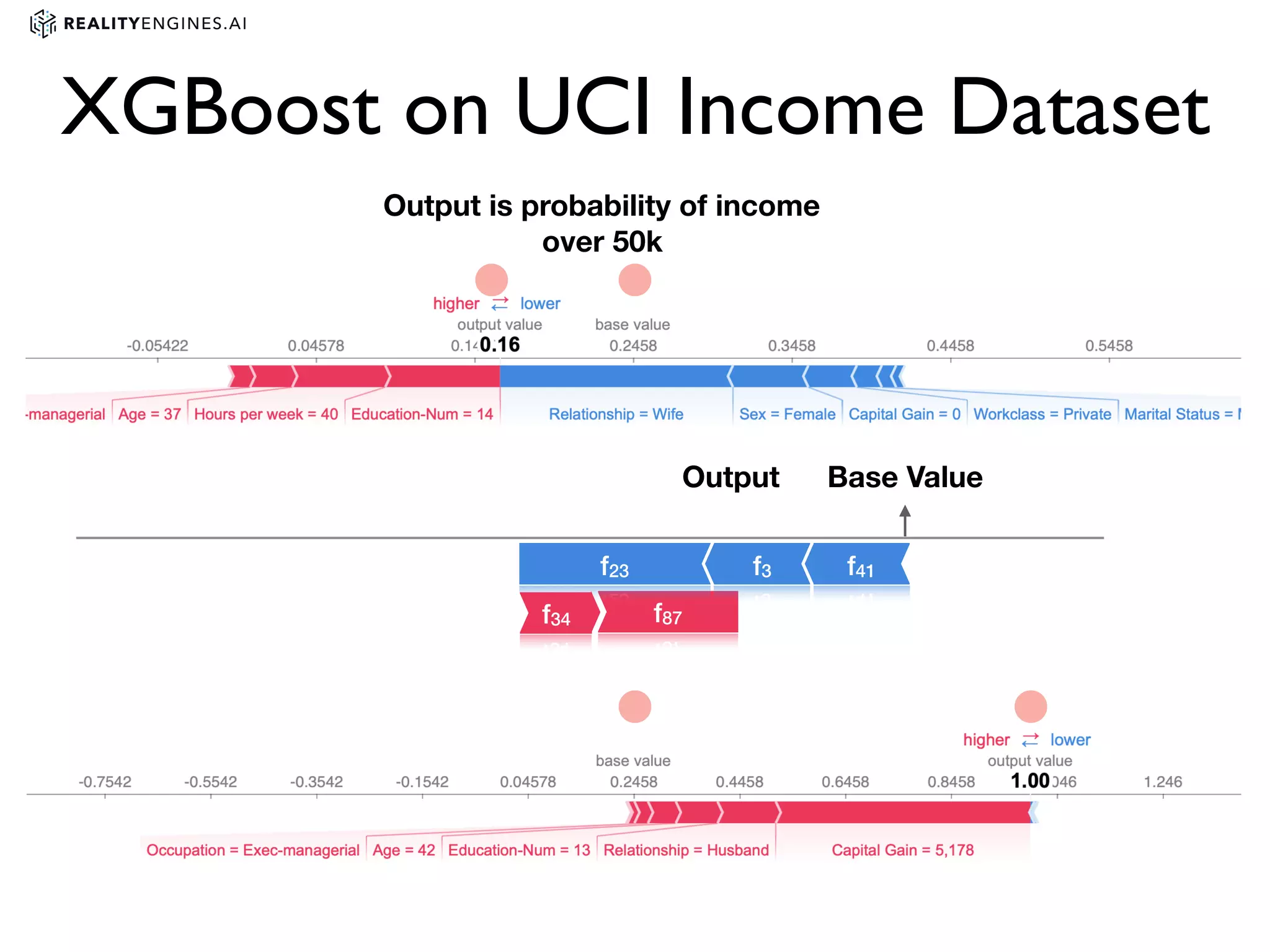
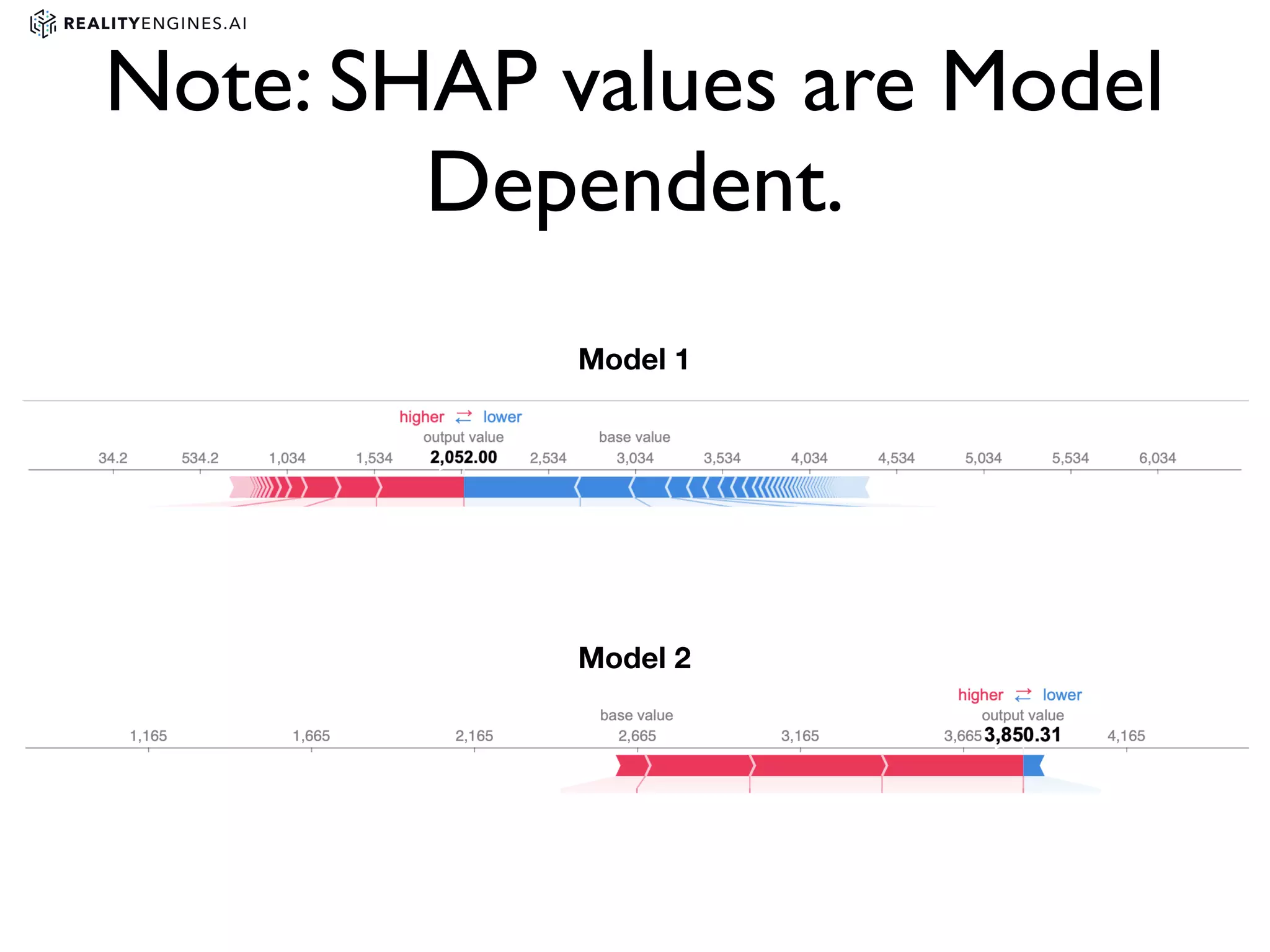
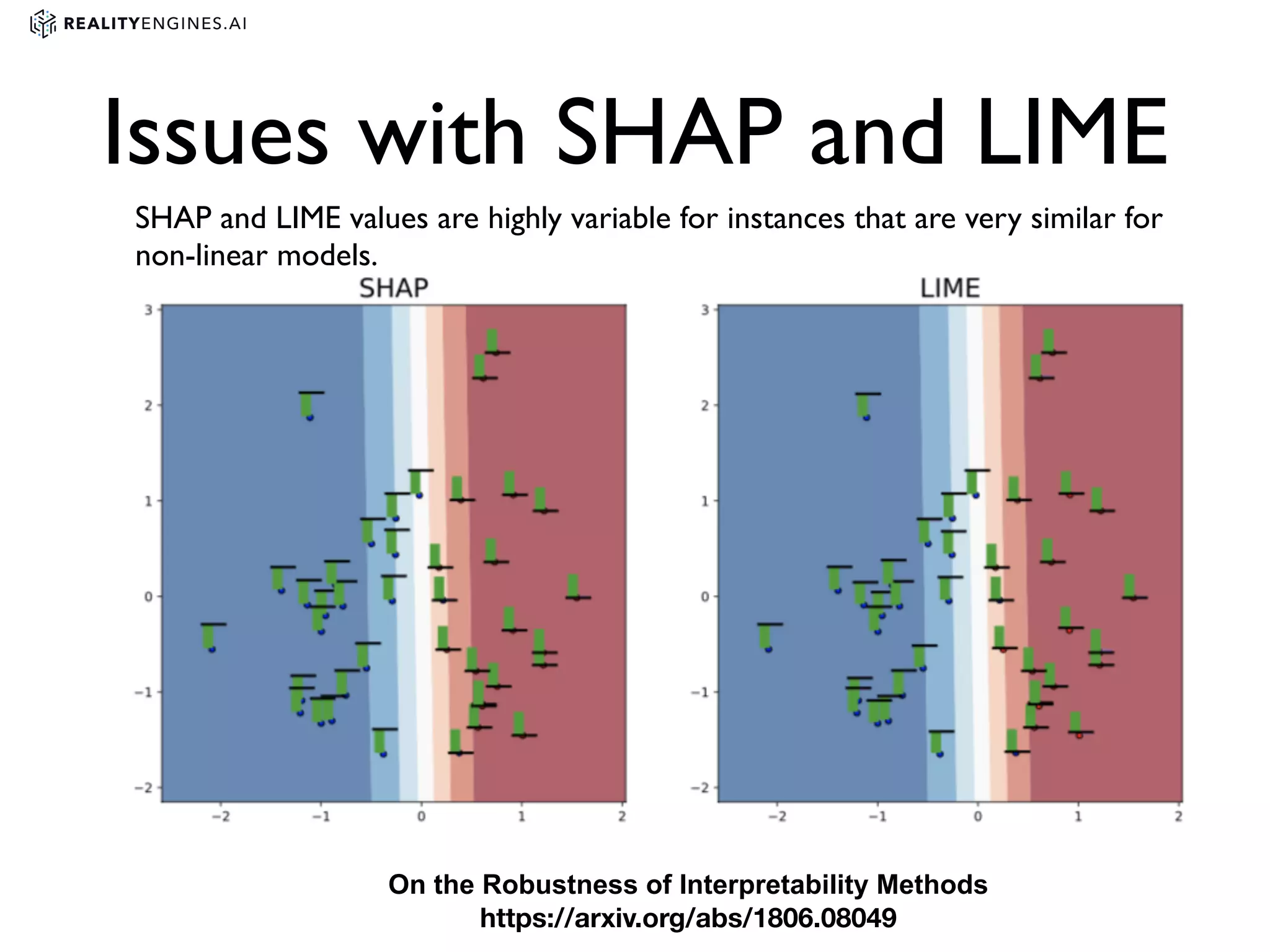
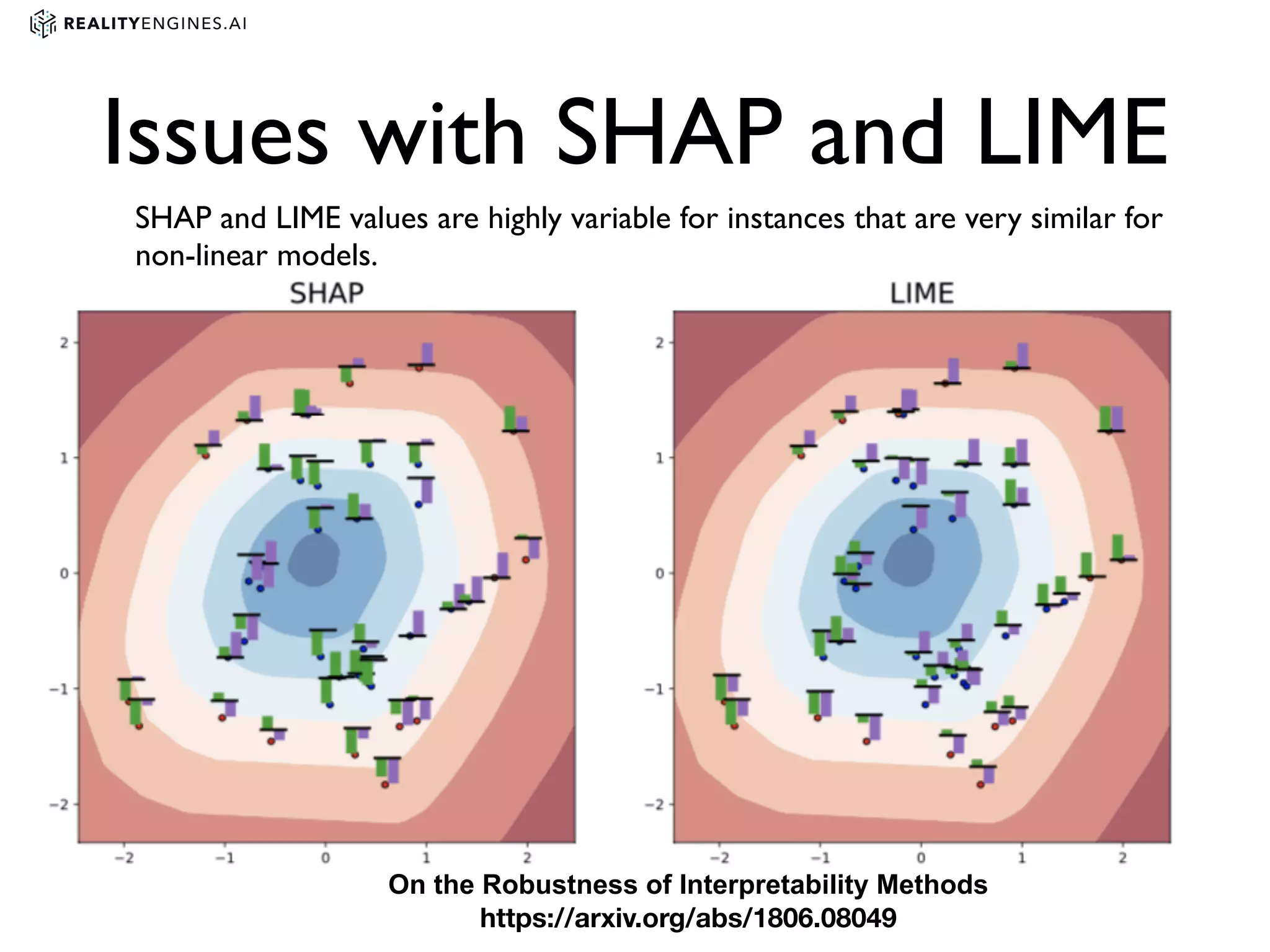
2. Methods for explainability including using interpretable models directly and post-hoc explainability methods like LIME and SHAP which provide feature attributions.
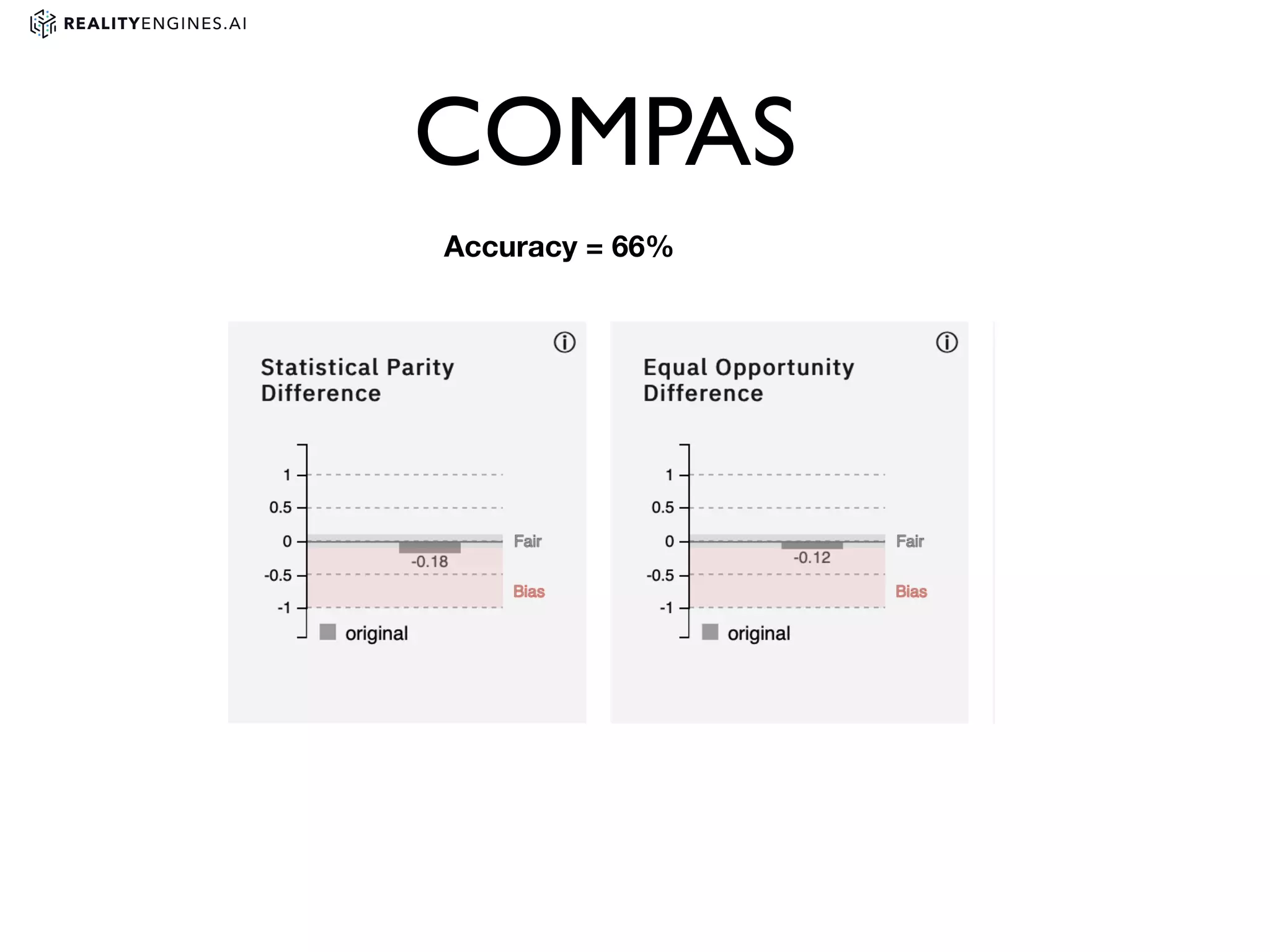
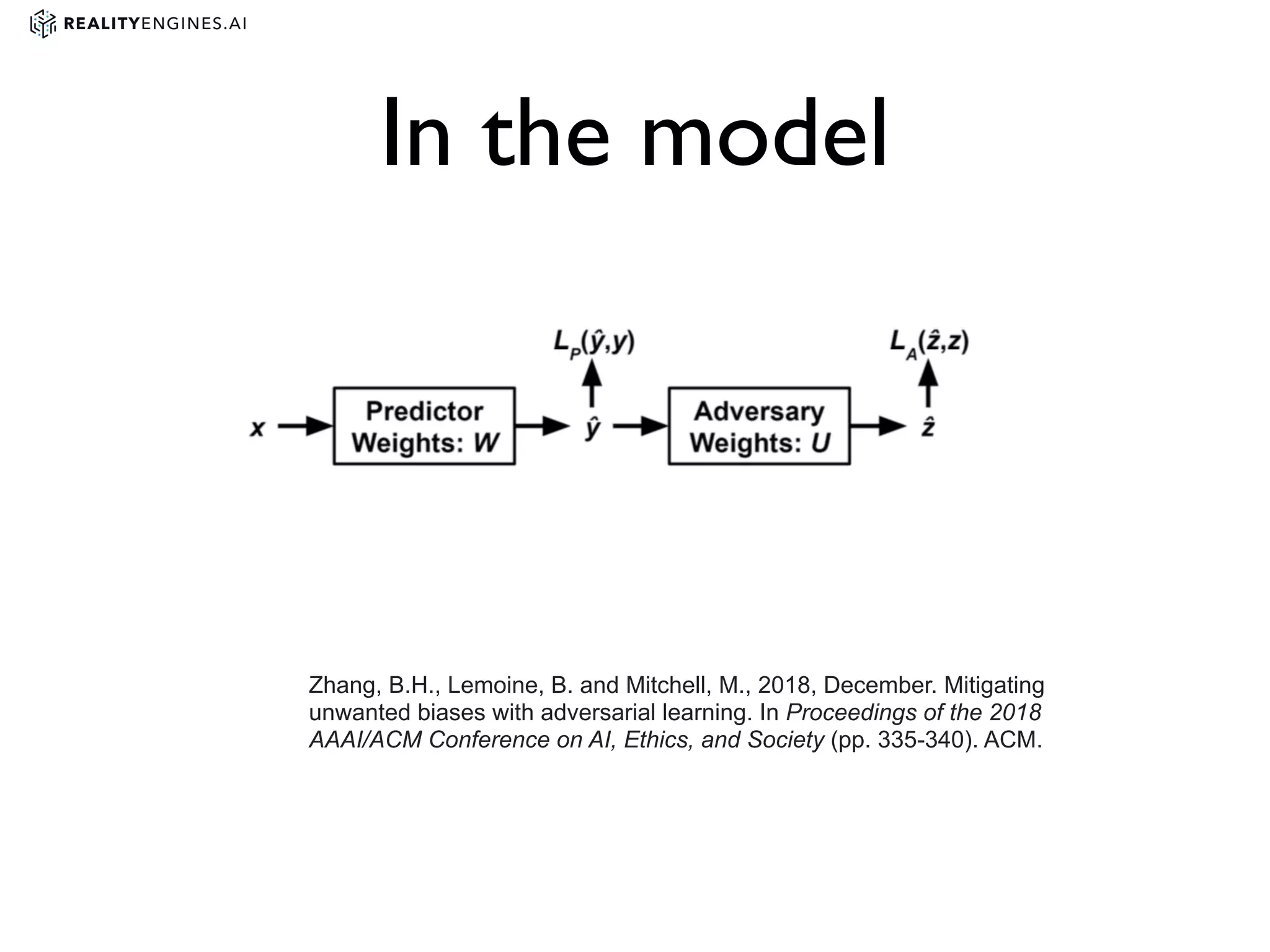
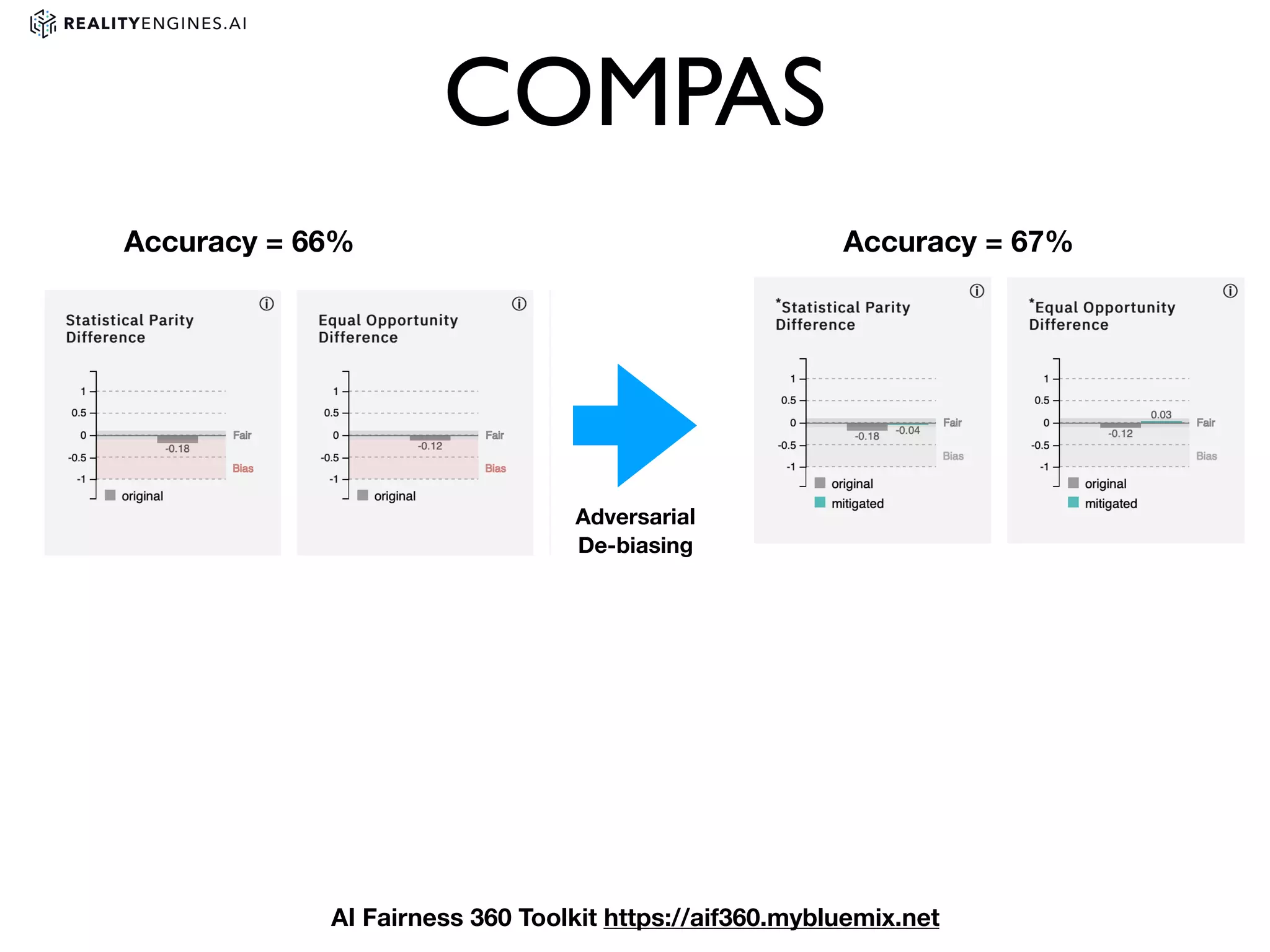
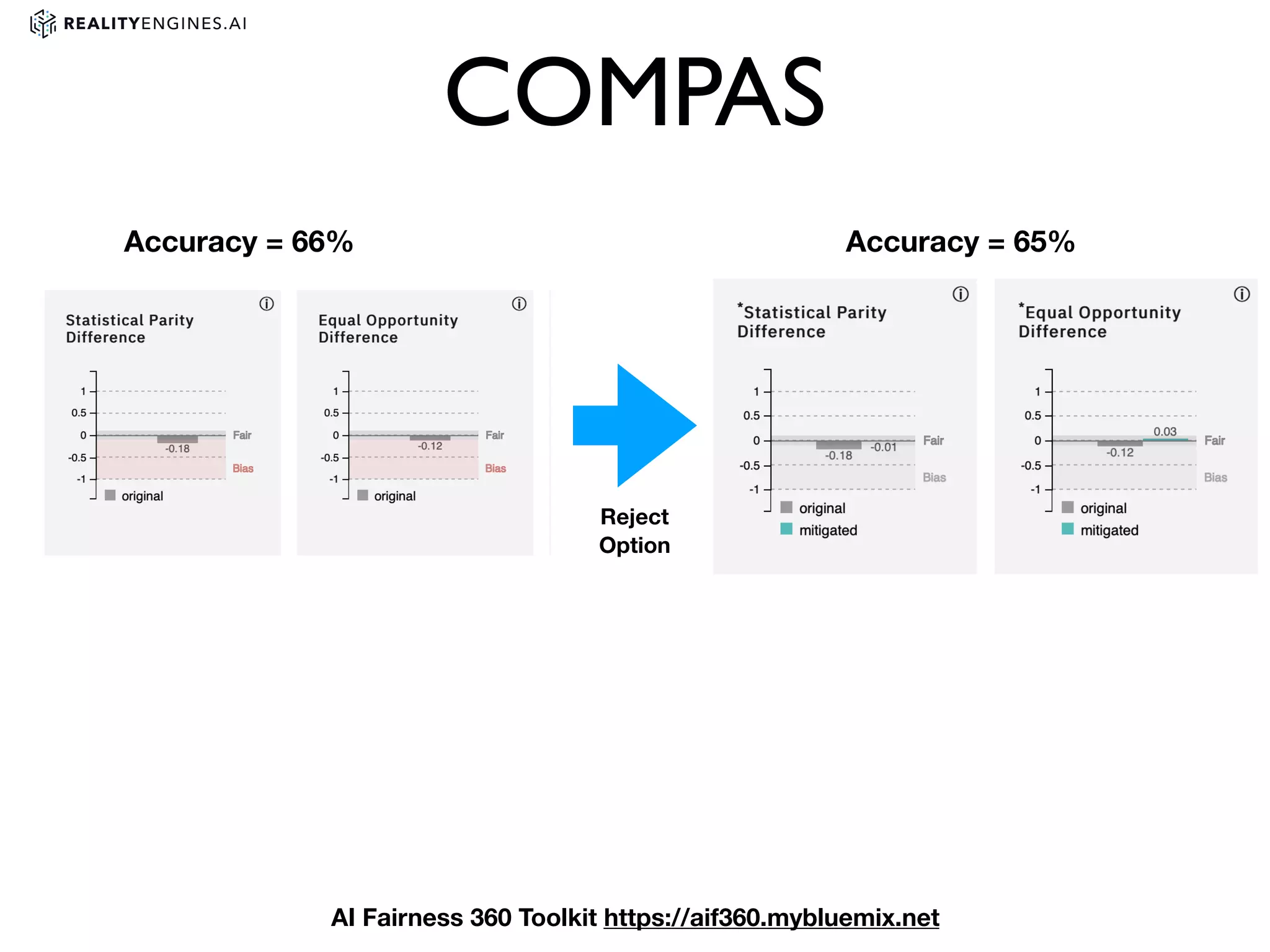
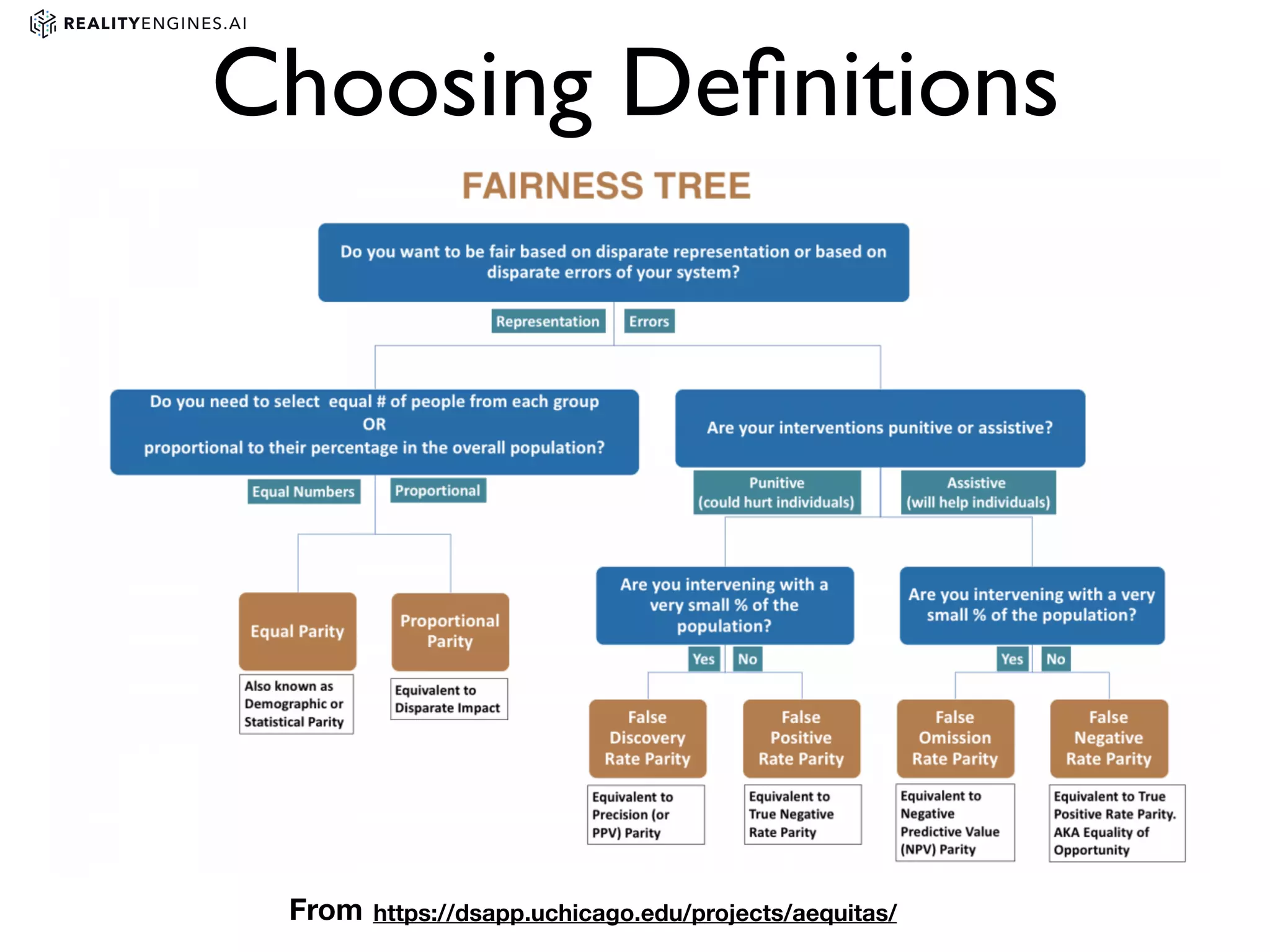
3. Issues with bias in machine learning models and different definitions of fairness. It also discusses techniques for measuring and mitigating bias, such as reweighting data or using adversarial learning.