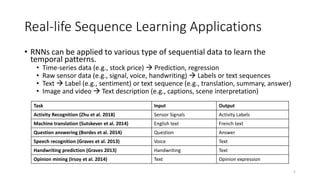
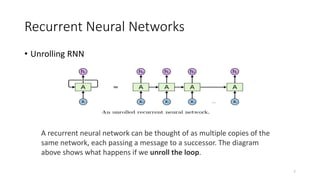
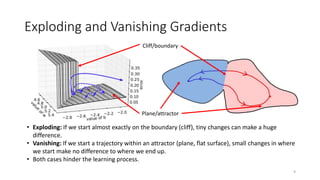
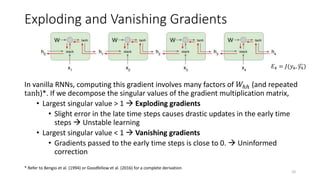
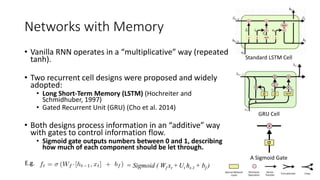
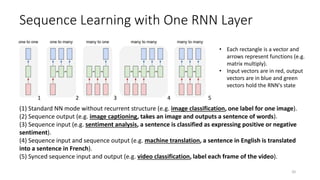
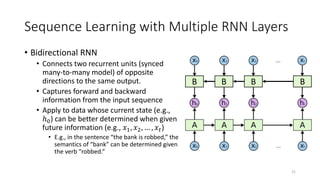
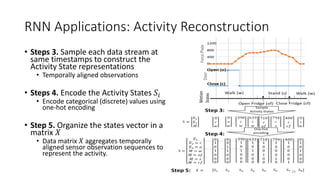
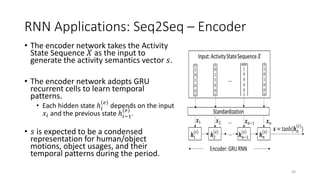
The document provides an overview of recurrent neural networks (RNNs), including their implementation and applications. It discusses how RNNs can process sequential data due to their ability to preserve information from previous time steps. However, vanilla RNNs suffer from exploding and vanishing gradients during training. Newer RNN architectures like LSTMs and GRUs address this issue through gated connections that allow for better propagation of errors. Sequence learning tasks that can be addressed with RNNs include time-series forecasting, language processing, and image/video caption generation. The document outlines RNN architectures for different types of sequential inputs and outputs.







![Step-by-step LSTM Walk Through
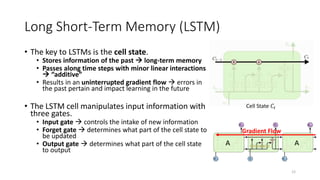
• Step 1: Decide what information to throw away from the cell state
(memory)
• The output of the previous state ℎ𝑡−1 and the new information 𝑥𝑡 jointly
determine what to forget
• ℎ𝑡−1 contains selected features from the memory 𝐶𝑡−1
• Forget gate 𝑓𝑡 ranges between [0, 1]
14
Forget gate
Text processing example:
Cell state may include the gender
of the current subject (ℎ𝑡−1).
When the model observes a new
subject (𝑥𝑡), it may want to forget
(𝑓𝑡 → 0) the old subject in the
memory (𝐶𝑡−1).](https://image.slidesharecdn.com/recurrentneuralnetworksapril2020-230520112002-cb0ccaec/85/recurrent_neural_networks_april_2020-pptx-14-320.jpg)
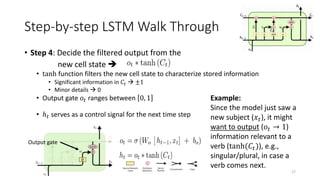
![Step-by-step LSTM Walk Through
• Step 2: Prepare the updates for the cell state
from input
• An alternative cell state 𝐶𝑡 is created from the new information 𝑥𝑡 with the
guidance of ℎ𝑡−1.
• Input gate 𝑖𝑡 ranges between [0, 1]
15
Input gate Alternative
cell state
Example:
The model may want to add
(𝑖𝑡 → 1) the gender of new
subject (𝐶𝑡) to the cell state to
replace the old one it is
forgetting.](https://image.slidesharecdn.com/recurrentneuralnetworksapril2020-230520112002-cb0ccaec/85/recurrent_neural_networks_april_2020-pptx-15-320.jpg)






![Implementation Example: Sequence Classification with LSTM
(many to one)
25
# define word embedding size
embedding_vecor_length = 32
# create a sequential model
model = Sequential()
# transform input sequence into word embedding representation
model.add(Embedding(top_words, embedding_vecor_length,
input_length=max_review_length))
# generate a 100-dimention output, can be replaced by GRU or SimpleRNN
recurrent cells
model.add(LSTM(100))
# a fully connected layer weight the 100-dimention output to one node for
prediction
model.add(Dense(1, activation='sigmoid’))
# use binary_crossentropy as the loss function for the classification
model.compile(loss='binary_crossentropy', optimizer='adam',
metrics=['accuracy'])
print(model.summary())
# model training (for 3 epochs)
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=3,
batch_size=64)
# Final evaluation of the model
scores = model.evaluate(X_test, y_test, verbose=0)
print("Accuracy: %.2f%%" % (scores[1]*100))
100 dims
Fully
connected
layer
Word embeddings
Recurrent cell
… movie fantastic, awesome …
Review
32 dims
0/1?](https://image.slidesharecdn.com/recurrentneuralnetworksapril2020-230520112002-cb0ccaec/85/recurrent_neural_networks_april_2020-pptx-25-320.jpg)








































![[DSC Europe 25] Ivica Milaric - The Future of Gaming and AI Tools.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/tijgzsmgse2kj2y5pzzp-5-ivica-milaric-the-future-of-gaming-x-ai-tools-260114111931-87c2b3ac-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Srba Markovic - From Pilot to Production: Overcoming AI Deplo...](https://cdn.slidesharecdn.com/ss_thumbnails/yjjmrtytmwbalxlba7px-4-srba-markovic-from-pilot-to-production-overcoming-ai-deployment-blockers-with-260114111931-4a892d44-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)

