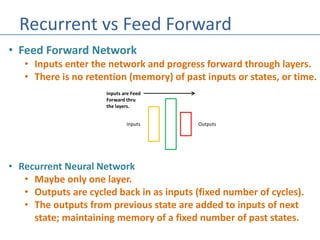
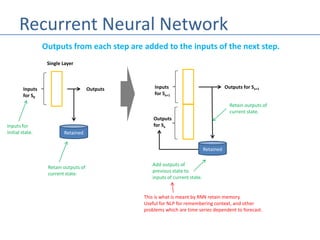
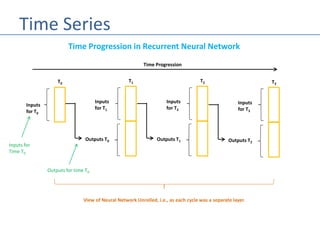
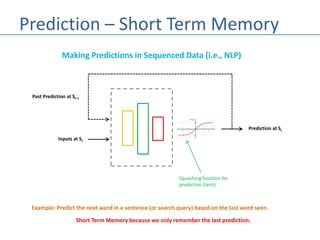
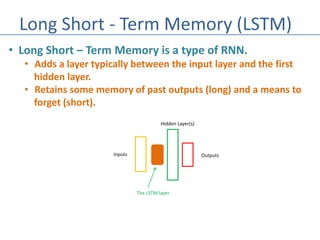
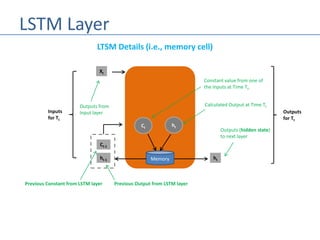
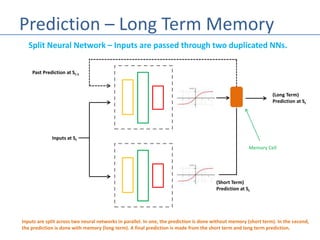
The document discusses recurrent neural networks (RNNs) and their differences from feed-forward networks, emphasizing RNNs' ability to retain memory of past states, which is essential for tasks like natural language processing and time series forecasting. It introduces long short-term memory (LSTM) networks, a type of RNN that retains long-term and short-term memories and includes mechanisms to forget irrelevant information. The document also mentions the concept of split neural networks for predictions based on both short-term and long-term inputs.