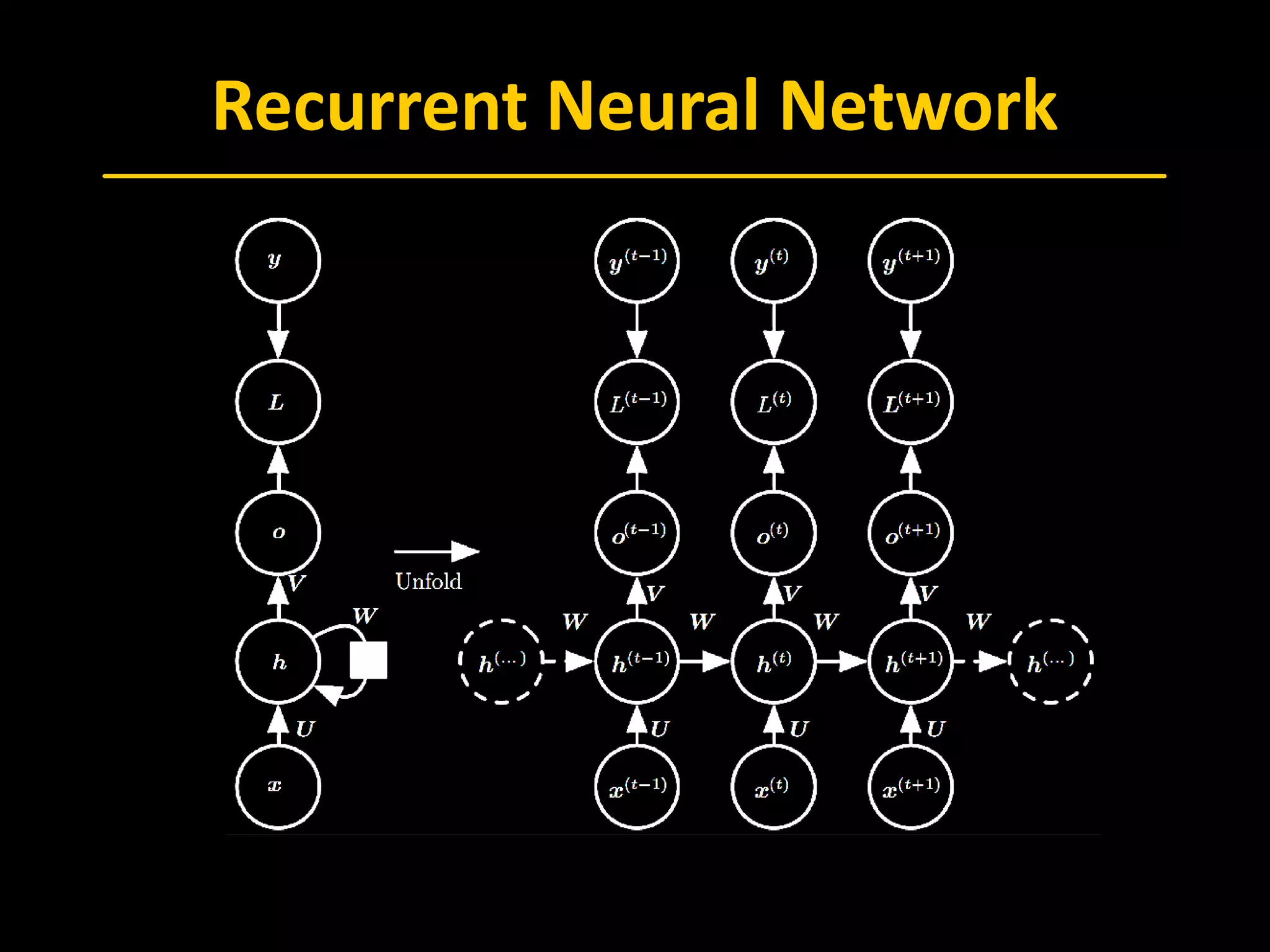
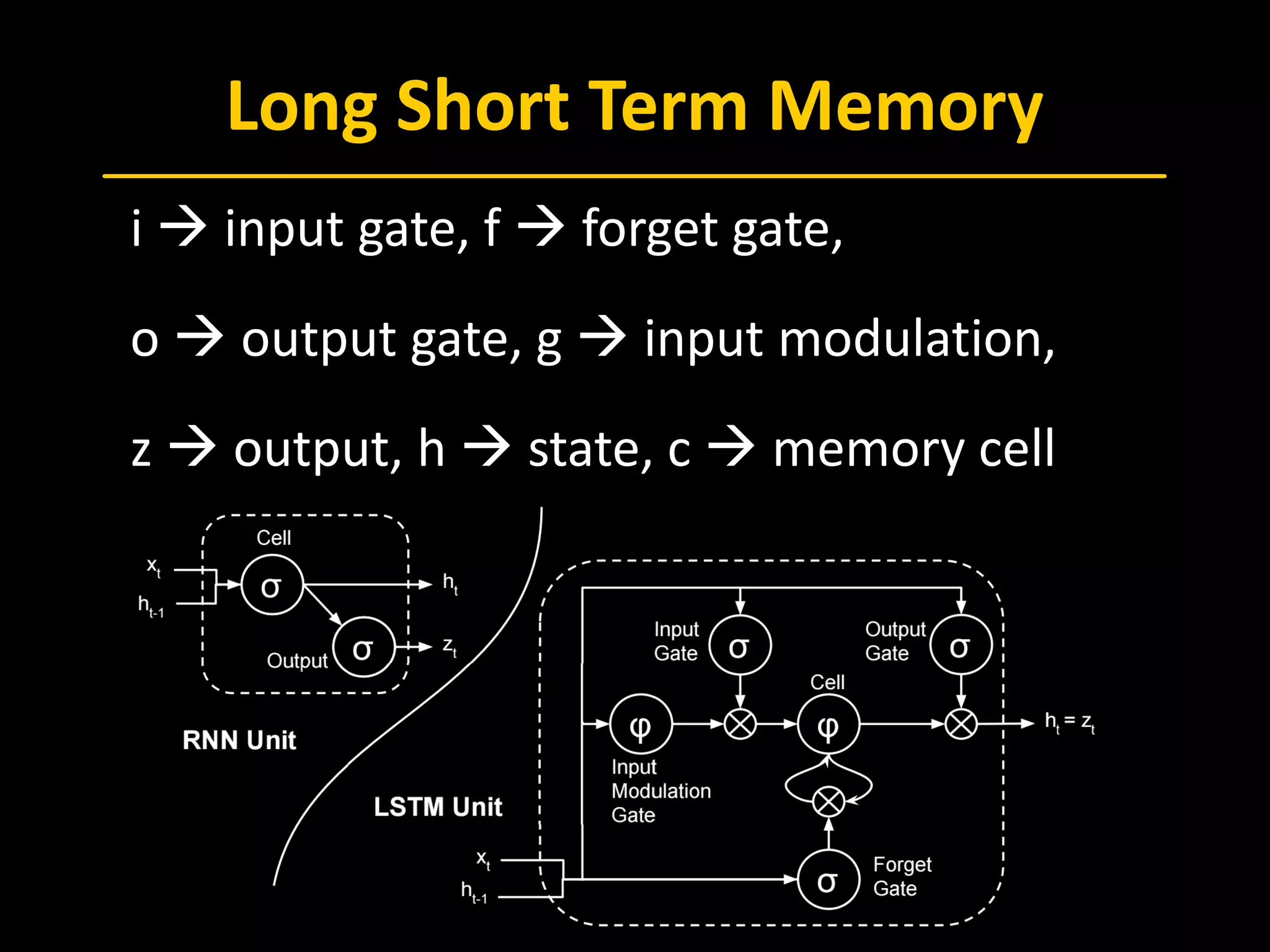
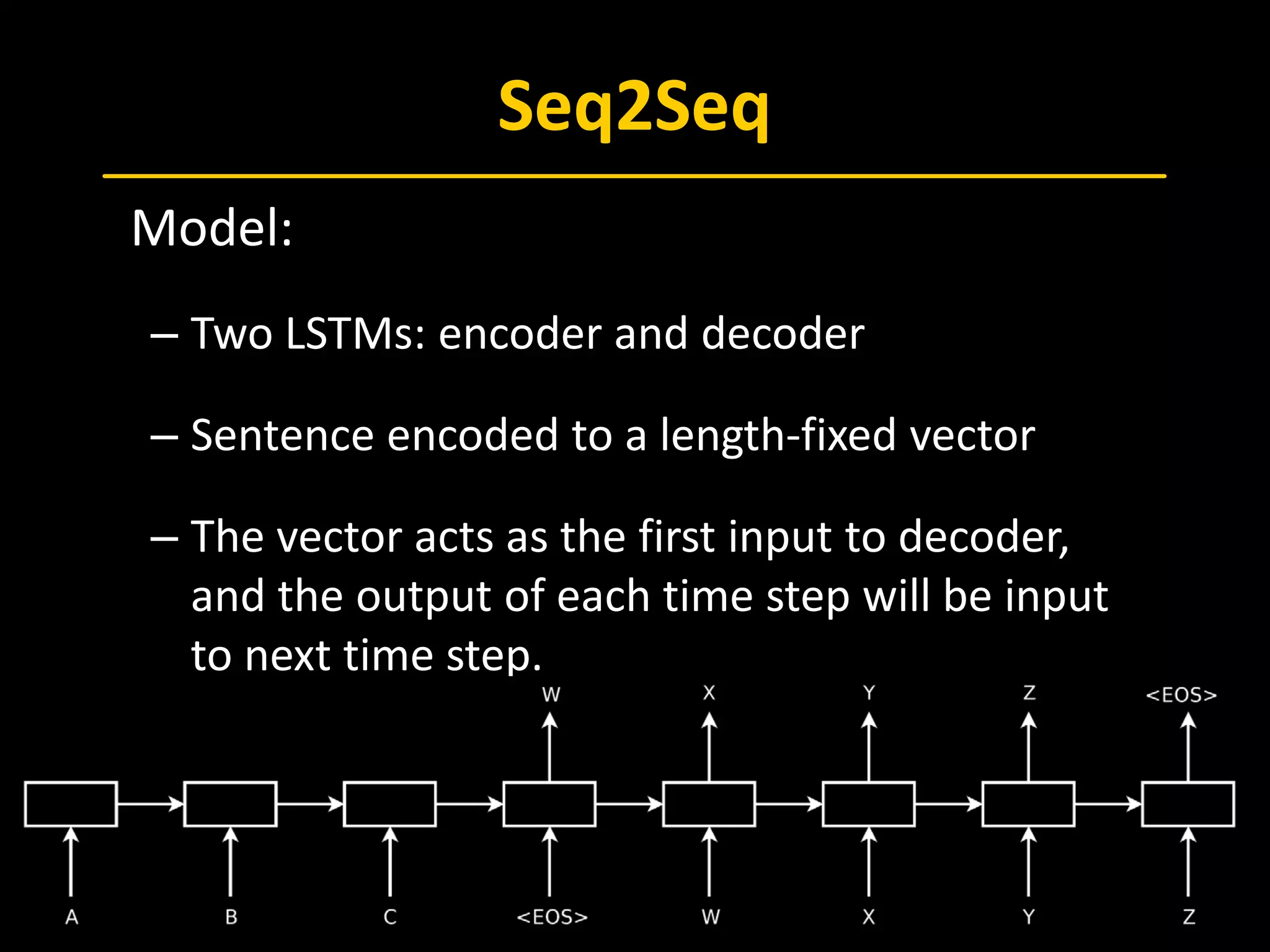
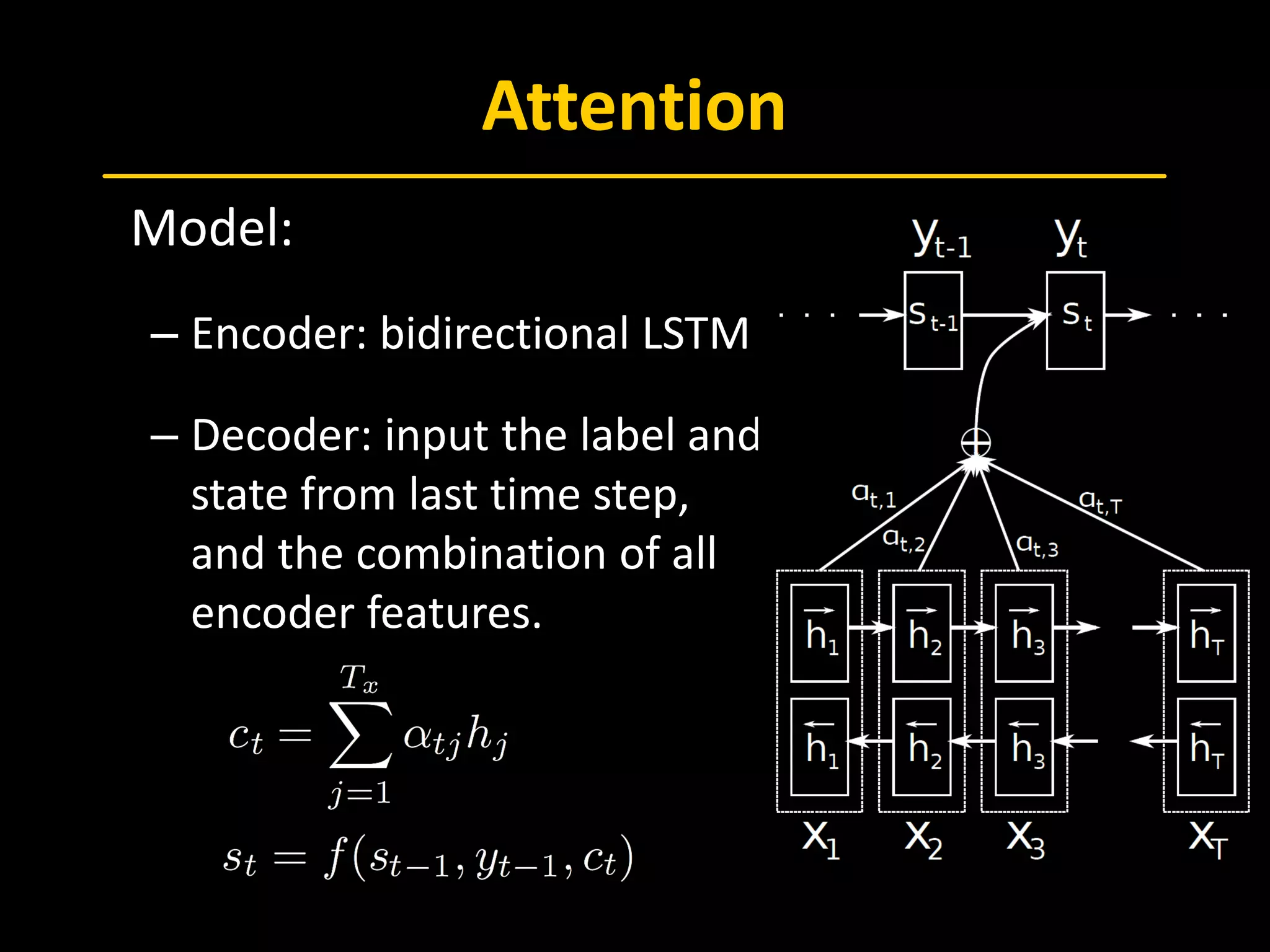
The document discusses Recurrent Neural Networks (RNN), emphasizing Long Short-Term Memory (LSTM) architectures and their applications in sequence-to-sequence learning and image captioning. It outlines the backpropagation through time (BPTT) methodology, attention mechanisms, and the usage of LSTMs in various contexts, including language translation and video classification. The document also touches on advances in neural machine translation and image caption generation, providing references to key studies in the field.































![References
[Goodfellow, 2016] Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep le
arning. MIT press.
[Sutskever, 2014] Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to se
quence learning with neural networks. In Advances in neural information pr
ocessing systems (pp. 3104-3112).
[Bahdanau, 2014] Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machin
e translation by jointly learning to align and translate. arXiv preprint arXiv:1
409.0473. ICLR 2015
[Yao, 2016] Yao, Ting, Pan, Yingwei, Li, Yehao, Qiu, Zhaofan, & Mei, Tao. (201
6). Boosting image captioning with attributes. ICLR 2017
[Xu, 2015] Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., & Salakhutdinov, R., e
t al. (2015). Show, attend and tell: neural image caption generation with vis
ual attention. Computer Science, 2048-2057.
[Yao, 2015] Yao L, Torabi A, Cho K, et al. Describing Videos by Exploiting Tem
poral Structure[J]. Eprint Arxiv, 2015, 53:199-211.](https://image.slidesharecdn.com/paperreading170707-lstmandsequencetosequenceprocessing-181111235621/75/RNN-and-sequence-to-sequence-processing-36-2048.jpg)
![References
[Chollet, 2016] Chollet, F. (2016). Xception: Deep Learning with Depthwise S
eparable Convolutions. arXiv preprint arXiv:1610.02357.
[Gehring, 2017] Gehring, J., Auli, M., Grangier, D., Yarats, D., & Dauphin, Y. N.
(2017). Convolutional Sequence to Sequence Learning. arXiv preprint arXiv:
1705.03122.
[Vaswani, 2017] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L.,
Gomez, A. N., ... & Polosukhin, I. (2017). Attention Is All You Need. arXiv pre
print arXiv:1706.03762.
[Kaiser, 2017] Kaiser, L., Gomez, A. N., Shazeer, N., Vaswani, A., Parmar, N., J
ones, L., & Uszkoreit, J. (2017). One Model To Learn Them All. arXiv preprint
arXiv:1706.05137.](https://image.slidesharecdn.com/paperreading170707-lstmandsequencetosequenceprocessing-181111235621/75/RNN-and-sequence-to-sequence-processing-37-2048.jpg)
















![Digital Signal Processing[ECEG-3171]-Ch1_L04](https://cdn.slidesharecdn.com/ss_thumbnails/dspl4-180427094424-thumbnail.jpg?width=640&height=640&fit=bounds)

![Digital Signal Processing[ECEG-3171]-Ch1_L03](https://cdn.slidesharecdn.com/ss_thumbnails/dspl3-180427094423-thumbnail.jpg?width=640&height=640&fit=bounds)






![Digital Signal Processing[ECEG-3171]-Ch1_L05](https://cdn.slidesharecdn.com/ss_thumbnails/dspl5ch2-180427094424-thumbnail.jpg?width=640&height=640&fit=bounds)

![Digital Signal Processing[ECEG-3171]-Ch1_L02](https://cdn.slidesharecdn.com/ss_thumbnails/dspl2-180427094423-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)



![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)







