The document discusses artificial neural networks (ANNs) and the evolution of recurrent neural networks (RNNs) to long short-term memory (LSTM) networks. LSTMs address the vanishing gradient problem and allow for better memory retention and long-range dependencies in sequential data processing. Key features of LSTM include gates for information flow control, enabling improved accuracy in predictions for large datasets.
The presentation introduces the topic of Long Short-Term Memory (LSTM), a special type of neural network, along with academic details of the author.
Discusses the foundation of ANNs, including their structure, forward propagation, and the training process involving back propagation.
Explains traditional Recurrent Neural Networks (RNN) and issues like memory limitations and Back Propagation Through Time (BPTT) in managing long sequences.
Describes the vanishing gradient problem in multilayered ANNs, impacting the ability to learn from long-term dependencies.
Introduces LSTM networks as a solution to RNN issues, detailing architecture, memory cells, and gate mechanisms controlling information flow.
LSTMs address vanishing gradients, offer better accuracy, and can learn long-term dependencies from large data, enhancing prediction capabilities.
Lists references used in the presentation and concludes with gratitude from the presenter.
LONG SHORT-
TERM MEMORY
SsenjovuEmmanuel Joster
Student-No: 2001200052
Bsc. Information Technology
Faculty of Technoscience
Dept. Computer Science & Electrical Engineering
Muni University || P.O.Box 725, Arua(UG)
2.
Artificial neurons areinspired by and modeled
after the biological structure of the human brain
ANNs are capable of learning to solve problems
in a way our brains can do naturally.
Artificial Neurons
First things first...
Connected neurons then form a network, hence
the name neural network consisting of : input
layer, hidden layer, and output layer
3.
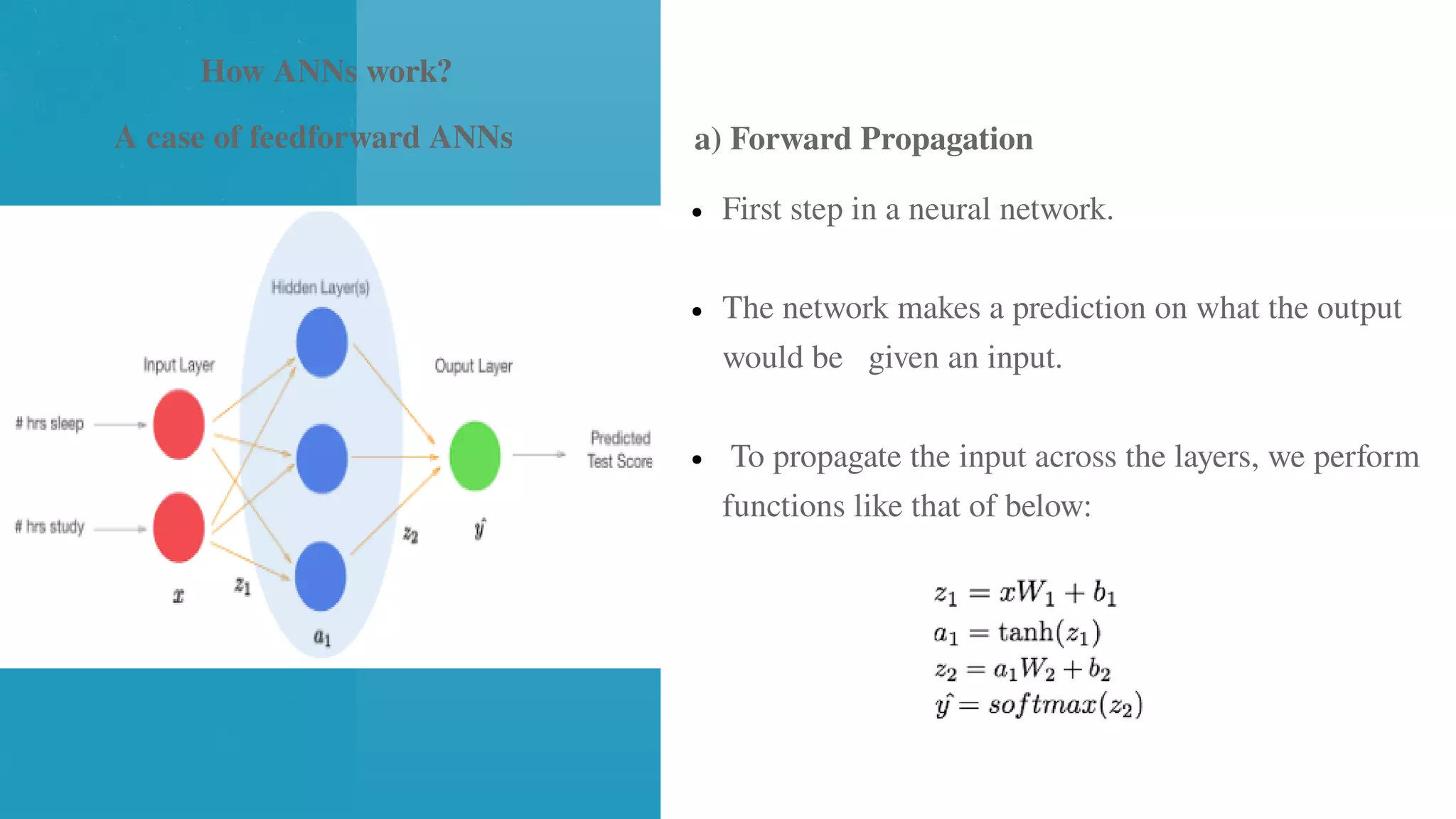
● First stepin a neural network.
● The network makes a prediction on what the output
would be given an input.
● To propagate the input across the layers, we perform
functions like that of below:
a) Forward Propagation
How ANNs work?
A case of feedforward ANNs
4.
● Comes intoplay in training phase of a neural
network.
● Involves adjusting the weights until network can
produce desired outputs.
● We calculate error and its gradients with respect to
each weight at each layer & subsequently adjust
weights:
b) Back Propagation
How ANNs work?
5.
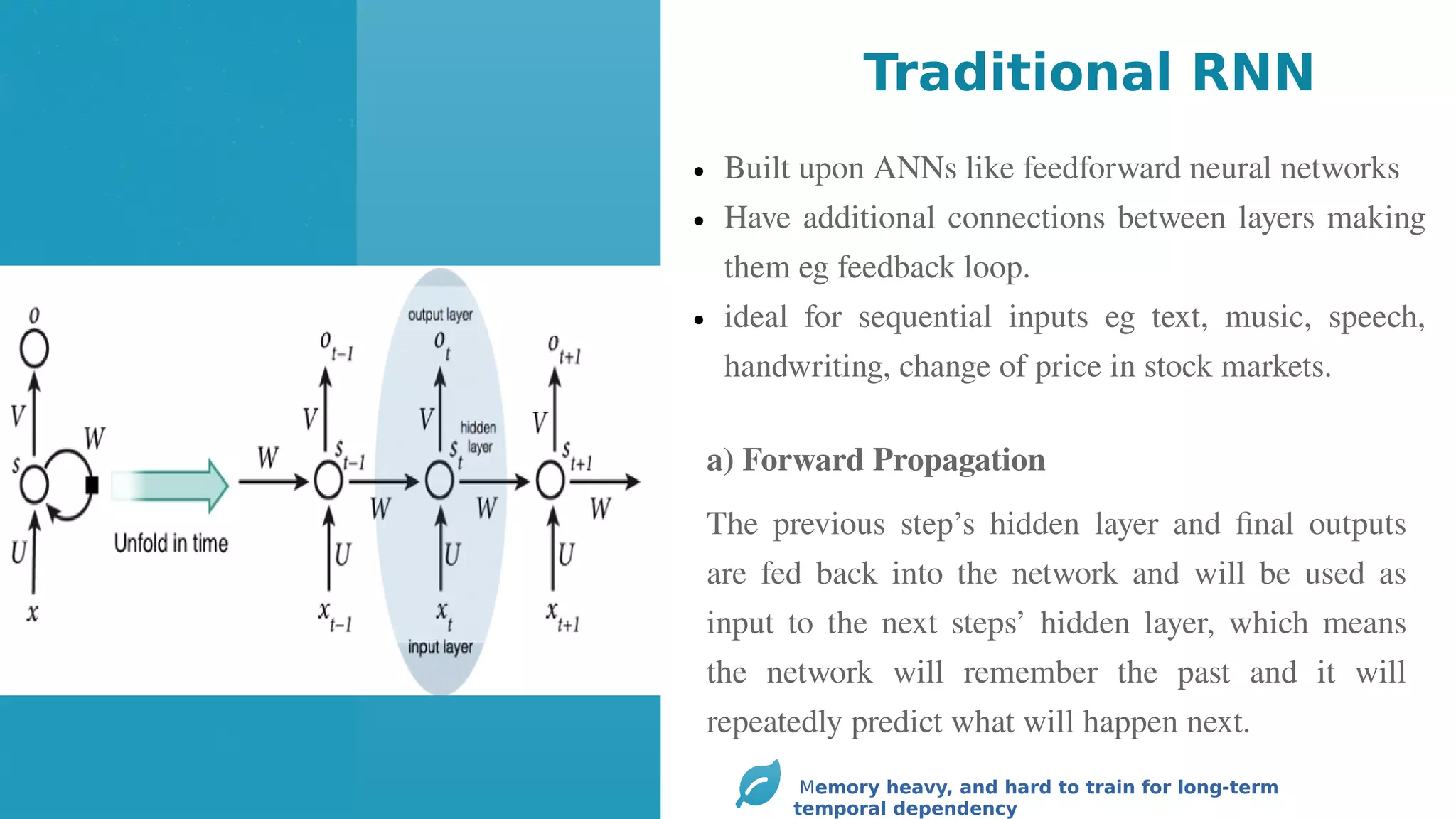
● Built uponANNs like feedforward neural networks
● Have additional connections between layers making
them eg feedback loop.
● ideal for sequential inputs eg text, music, speech,
handwriting, change of price in stock markets.
The previous step’s hidden layer and final outputs
are fed back into the network and will be used as
input to the next steps’ hidden layer, which means
the network will remember the past and it will
repeatedly predict what will happen next.
Traditional RNN
a) Forward Propagation
Memory heavy, and hard to train for long-term
temporal dependency
6.
● We calculatethe error the weight matrices W
generate, and then adjust their weights until the
error cannot go any lower.
● To compute the gradient for the current , we
𝑊
need to perform the chain rule through a series of
previous time steps. Because of this, we call the
process back propagation through time (BPTT). If
the sequences are quite long, the BPTT can take a
long time;
Traditional RNN
ln practice many people truncate the backpropagation
to a few steps instead of all the way to the beginning.
a) Back Propagation Through Time(BPTT)
7.
The
Vanishing Gradient
In multilayeredANNs eg RNN the vanishing gradient problem refers to
the situation where the gradients(derivatives) of the loss function with
respect to weights of early layers in a deep neural network become
extremely too small to allow training for activities which require long-
term dependency. For-example if we are predicting the next word in
longer multi-sentence paragraph, it is less likely that that the model will
be able to remember the first words in the beginning of the paragraph.
8.
LONG SHORT-TERM MEMORY
●LSTM is an implementation of improved RNN
architecture to address the issues of general RNN
● Enables long-range dependencies.
● Has better memory through linear memory cells
surrounded by a set of gate units used to control
the flow of information.
● It uses no activation function within its recurrent
components, thus the gradient term does not
vanish with back propagation.
9.
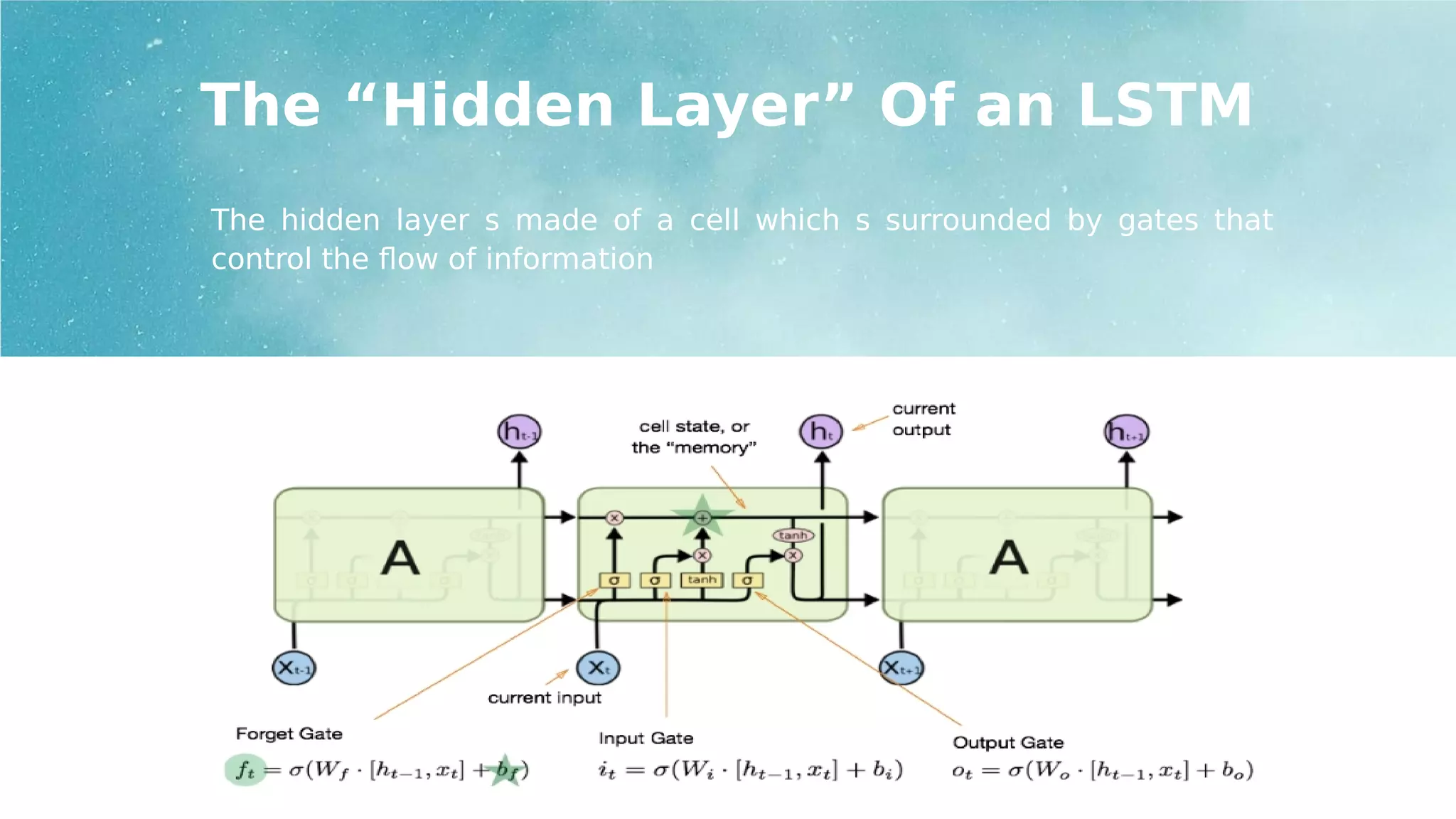
The “Hidden Layer”Of an LSTM
The hidden layer s made of a cell which s surrounded by gates that
control the flow of information
10.
1.Forget Gate
● Firststep in which the sigmoid
function outputs a value ranging from
0 to 1 to
● Determines how much information of
the previous hidden state and current
input it should retain.
● LSTM does not necessarily need to
remember everything that has
happened in the past.
2.Input Gate 3.Output Gate
The gates of an LSTM
The gates perform the following functions to control the flow of
information
Next step and involves two parts;
● First, the input gate determines what
new information to store in the
memory cell.
● Next, a tanh layer creates a vector of
new candidate values to be added to
the state.
● To determine what to output from the
memory cell, we again apply the
sigmoid function to the previous
hidden state and current input, then
multiply that with tanh applied to the
new memory cell(this will make the
values between -1 and 1)
11.
Memory
LSTM has anactual memory
built into the architecture that
lacks in RNN
Vanshng/ Exploding
gradients
LSTMs can deal with these
problems
Accuracy
More accurate predictions
for larger sequential data
Long-term
dependency
Able to capture complex
patterns n huge datasets
WHY LSTMs?
12.
[1] Mastering MachineLearning with Python in Six Steps By Manohar
Swamynathan Bangalore
[2] Long Short-Term Memory By Sepp Hochreiter, Fakultät für Informatik,
Technische Universität München, 80290 München, Germany
[3] Long Short-Term Memory-Networks for Machine Reading, Jianpeng Cheng, Li
Dong and Mirella Lapata , School of Informatics, University of Edinburgh
[4] Long Short-Term Memory, M. Stanley Fujimoto, CS778–Winter2016,30 Jan
2016
References:








![[1] Mastering Machine Learning with Python in Six Steps By Manohar
Swamynathan Bangalore
[2] Long Short-Term Memory By Sepp Hochreiter, Fakultät für Informatik,
Technische Universität München, 80290 München, Germany
[3] Long Short-Term Memory-Networks for Machine Reading, Jianpeng Cheng, Li
Dong and Mirella Lapata , School of Informatics, University of Edinburgh
[4] Long Short-Term Memory, M. Stanley Fujimoto, CS778–Winter2016,30 Jan
2016
References:](https://image.slidesharecdn.com/lstmpresent-230528054623-1521ad5f/75/An-Introduction-to-Long-Short-term-Memory-LSTMs-12-2048.jpg)


















![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)

















































