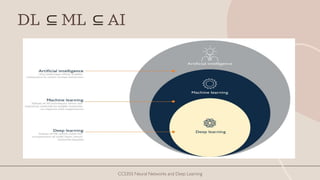
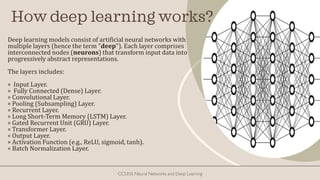
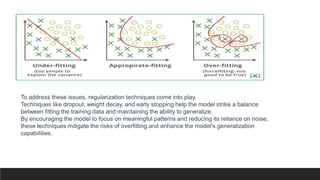
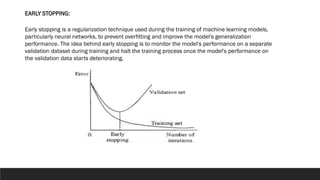
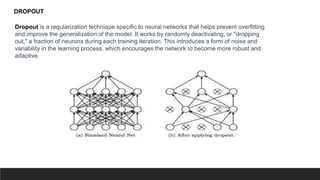
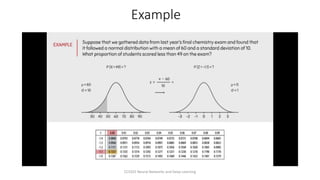
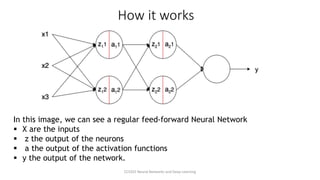
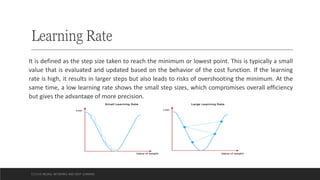
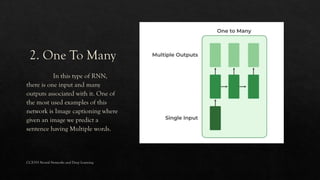
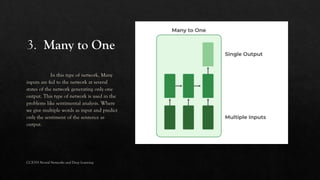
The document explores the history and fundamentals of deep learning, a subset of machine learning that utilizes artificial neural networks with multiple layers for automatic feature learning and complex data processing. It outlines the evolution of deep learning, key architectures used (like CNNs, LSTMs, and GANs), and addresses challenges such as overfitting, interpretability, and computational costs, while highlighting regularization techniques like dropout and bagging to improve model robustness. Furthermore, it emphasizes the significance of techniques like data augmentation and early stopping to enhance noise robustness and optimize performance in neural networks.