Downloaded 58 times








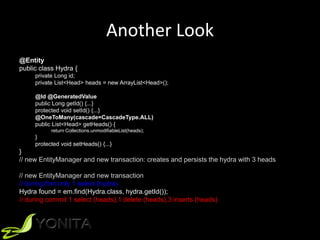















![ReporUng AnU-PaVerns
ProjecUon (3)
Query query = em.createQuery(
"SELECT e.salary, e.address.country
FROM Employee e”);
List<Object[]> list = query.getResultList();
// calculate sum of salaries by country
// map: country->sum
Map<String, BigDecimal> results = new HashMap<>();
for (Object[] e : list) {
String country = (String) e[1];
BigDecimal total = results.get(country);
if (total == null) total = BigDecimal.ZERO;
total = total.add((BigDecimal) e[0]);
results.put(country, total);
}](https://image.slidesharecdn.com/javadaykiev2015-jpa-151109062357-lva1-app6892/85/Lazy-vs-Eager-Loading-Strategies-in-JPA-2-1-25-320.jpg)
![ReporUng AnU-PaVerns
AggregaUon JPQL (4)
Query query = em.createQuery(
"SELECT SUM(e.salary), e.address.country
FROM Employee e
GROUP BY e.address.country”);
List<Object[]> list = query.getResultList();
// already calculated!](https://image.slidesharecdn.com/javadaykiev2015-jpa-151109062357-lva1-app6892/85/Lazy-vs-Eager-Loading-Strategies-in-JPA-2-1-26-320.jpg)

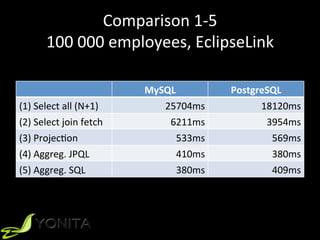







































The document discusses strategies for loading data in JPA, specifically lazy vs eager loading. It provides examples of when each strategy would be preferred, noting that eager loading is generally better for loading a small amount of related data to avoid additional database queries, while lazy loading is preferred when the related data is large or its needed fields are unknown. It also discusses using lazy loading for large objects like blobs and clobs.























































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)







