Downloaded 28 times

























![[2019] 바르게, 빠르게! Reactive를 품은 Spring Kafka](https://image.slidesharecdn.com/nhnforward20198-200121085520/85/2019-Reactive-Spring-Kafka-72-320.jpg)
![[2019] 바르게, 빠르게! Reactive를 품은 Spring Kafka](https://image.slidesharecdn.com/nhnforward20198-200121085520/85/2019-Reactive-Spring-Kafka-73-320.jpg)

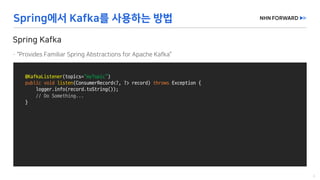
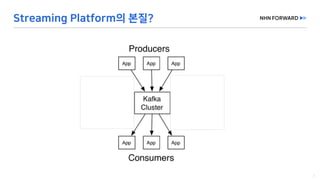
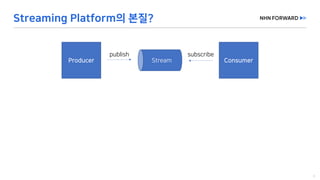
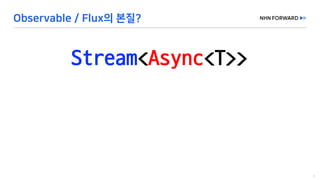
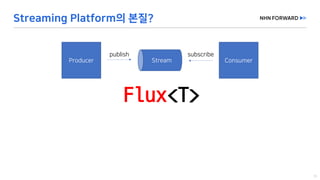
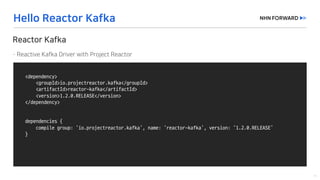
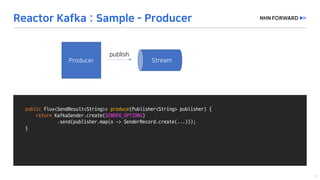
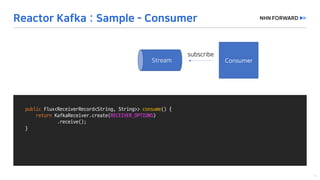
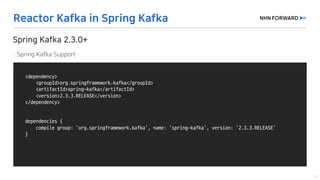
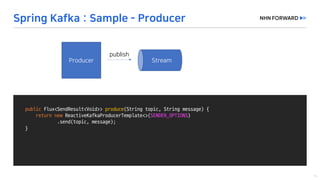
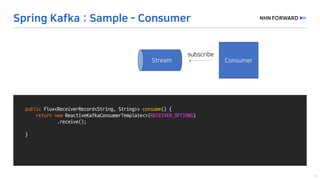
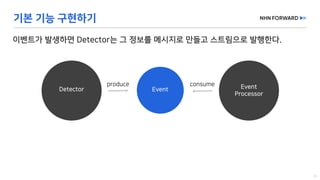
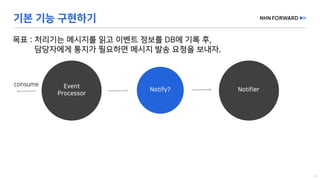
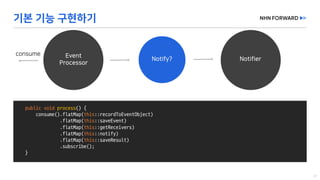
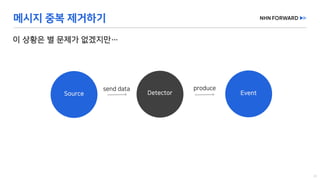
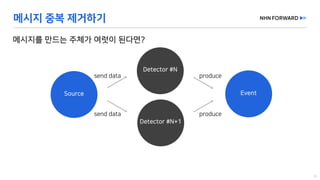
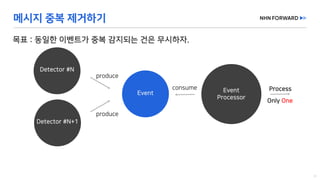
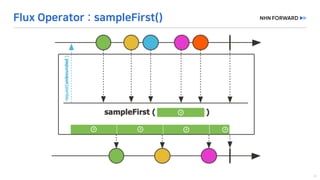
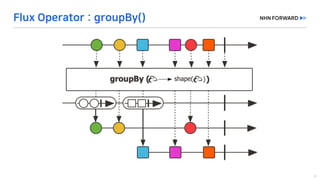
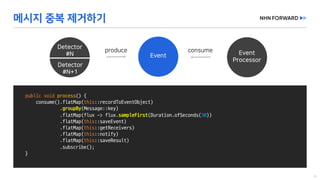
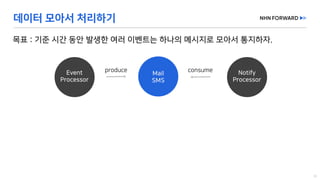
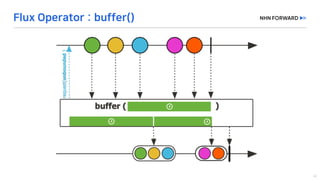
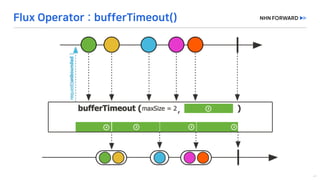
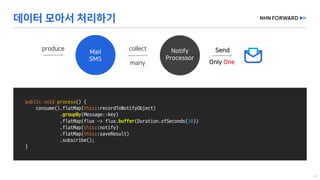
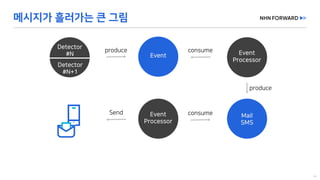
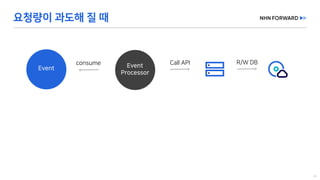
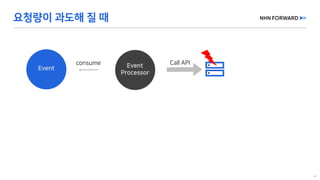
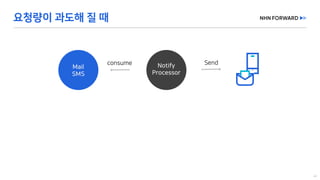
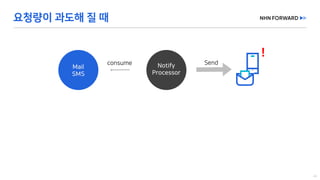
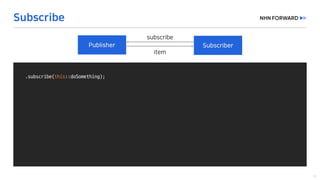
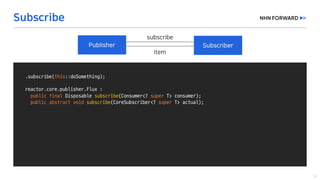
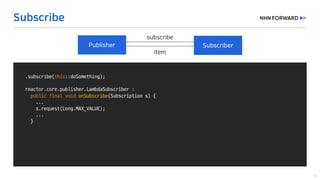
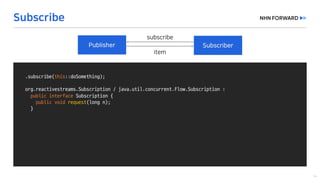
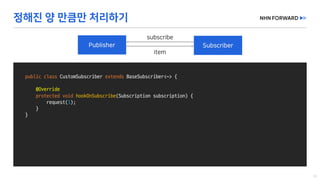
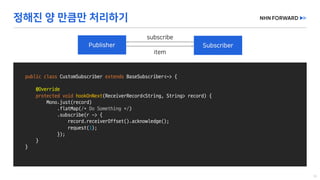
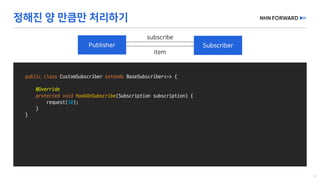
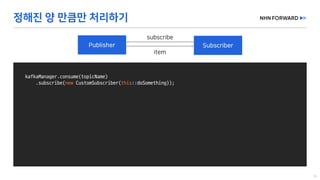
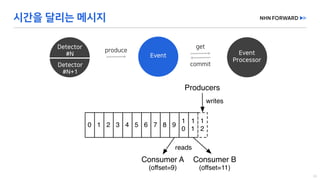
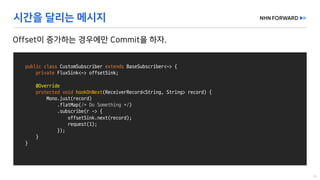
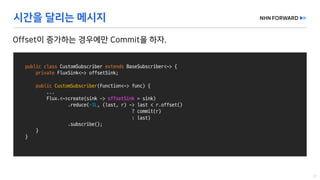
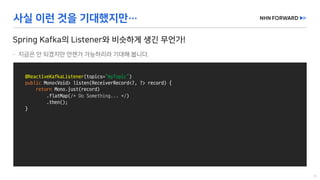
This document provides a code overview of a reactive Kafka consumer and producer using Reactor Kafka and Spring Kafka dependencies. It includes methods for producing and consuming messages, processing records into events, and handling offsets in a reactive manner. The code snippets demonstrate subscribing to topics, processing messages with backpressure, and using custom subscribers for specific processing requirements.




















![[MeetUp][1st] 오리뎅이의_쿠버네티스_네트워킹](https://cdn.slidesharecdn.com/ss_thumbnails/3-191024235922-thumbnail.jpg?width=640&height=640&fit=bounds)







![[2019] 패션 시소러스 기반 상품 특징 분석 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201900-200123073101-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 스몰 스텝: Android 렛츠기릿!](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201935-200123072807-thumbnail.jpg?width=640&height=640&fit=bounds)


![[2019] GIF 스티커 만들기: 스파인 2D를 이용한 움직이는 스티커 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201934-200123071121-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 전기 먹는 하마의 다이어트 성공기 클라우드 데이터 센터의 에너지 절감 노력과 사례](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201919-200123023945-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 스몰 스텝: Dooray!를 이용한 업무 효율화/자동화(고객문의 시스템 구축)](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201933-200122100333-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 아직도 돈 주고 DB 쓰나요? for Developer](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201932-200122100331-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 아직도 돈 주고 DB 쓰나요 for DBA](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201931-200122100329-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 비주얼 브랜딩: Basic system](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201930-200122100316-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] PAYCO 매거진 서버 Kotlin 적용기](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201929-200122100007-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 벅스 5.0 (feat. Kotlin, Jetpack)](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201928-200122095924-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] Java에서 Fiber를 이용하여 동시성concurrency 프로그래밍 쉽게 하기](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201927-200122095808-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] PAYCO 쇼핑 마이크로서비스 아키텍처(MSA) 전환기](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201926-200122093003-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 비식별 데이터로부터의 가치 창출과 수익화 사례](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201925-200122092831-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 게임 서버 대규모 부하 테스트와 모니터링 이렇게 해보자](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201924-200122092752-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 200만 동접 게임을 위한 MySQL 샤딩](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201923-200122092657-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 언리얼 엔진을 통해 살펴보는 리플렉션과 가비지 컬렉션](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201922-200122092627-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 글로벌 게임 서비스 노하우](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201921-200122092626-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2019] 배틀로얄 전장(map) 제작으로 알아보는 슈팅 게임 레벨 디자인](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201920-200122092612-thumbnail.jpg?width=640&height=640&fit=bounds)



















