Download as PDF, PPTX















![Sum
of
Salaries
by
Country
Projection
(3)
Query query = em.createQuery(
"SELECT e.salary, e.address.country
FROM Employee e");
List<Object[]> list = (List<Object[]>) query.getResultList();
// calculate sum of salaries by country
// map: country->sum
Map<String, BigDecimal> results = new HashMap<>();
for (Object[] e : list) {
String country = (String) e[1];
BigDecimal total = results.get(country);
if (total == null) total = BigDecimal.ZERO;
total = total.add((BigDecimal) e[0]);
results.put(country, total);
}
17](https://image.slidesharecdn.com/javaone2016-jpa-2nd-lvl-cache-160920210015/85/Second-Level-Cache-in-JPA-Explained-17-320.jpg)
![Sum
of
Salaries
by
Country
Aggregation
JPQL
(4)
Query query = em.createQuery(
"SELECT SUM(e.salary), e.address.country
FROM Employee e
GROUP BY e.address.country");
List<Object[]> list = (List<Object[]>) query.getResultList();
// already calculated!
18](https://image.slidesharecdn.com/javaone2016-jpa-2nd-lvl-cache-160920210015/85/Second-Level-Cache-in-JPA-Explained-18-320.jpg)







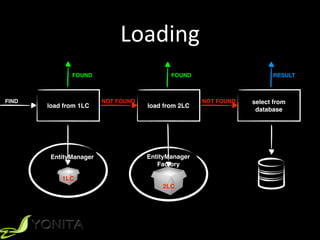






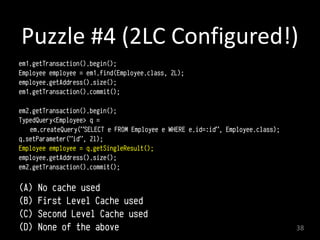
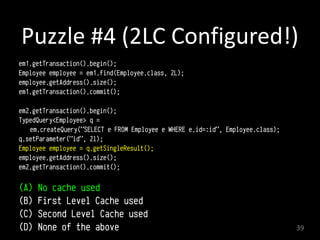
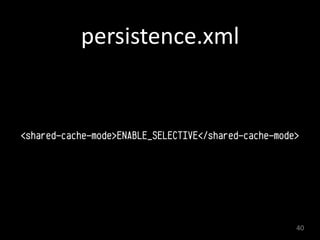



















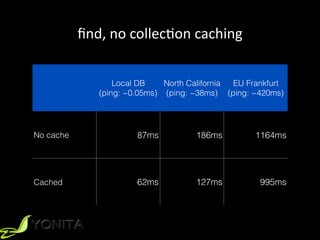
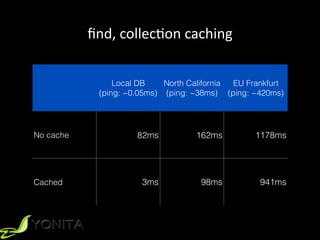











This document discusses second-level caching in Java Persistence API (JPA). It begins with an introduction to the speaker's background and experience. The presentation agenda is then outlined, covering why caching is important, the differences between first-level and second-level caches in JPA, JPA configuration parameters and API for caching, and specifics of Hibernate and EclipseLink second-level caching implementations. Examples are provided that demonstrate performance improvements when utilizing caching strategies like fetching relationships, projections, and aggregation queries.