Downloaded 16 times






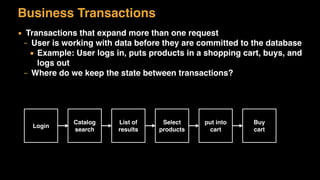
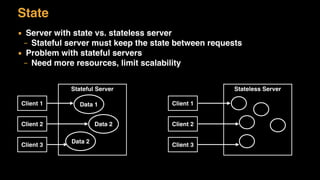




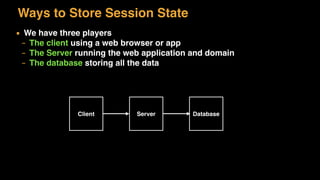
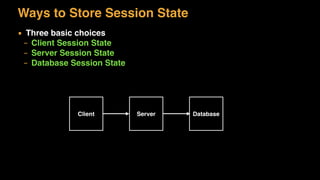











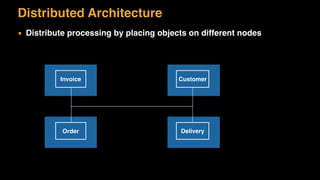





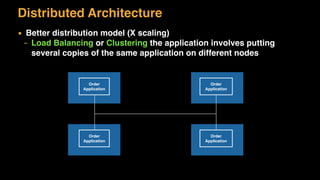







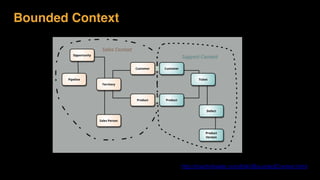



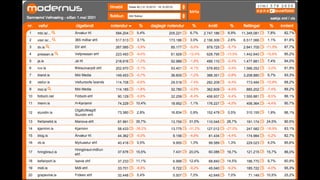



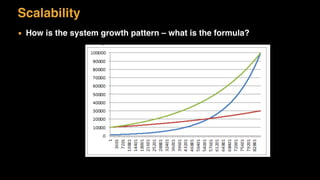
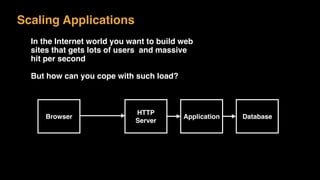



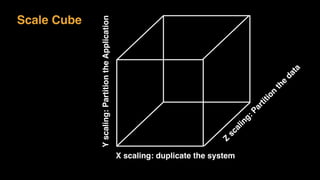
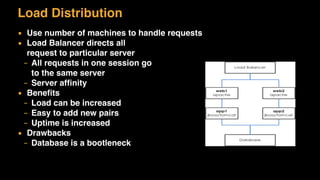
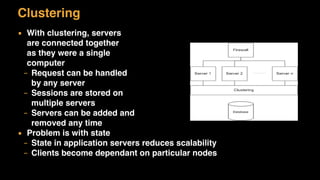

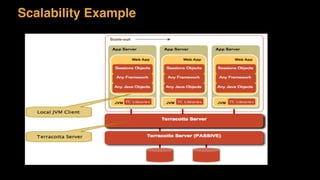
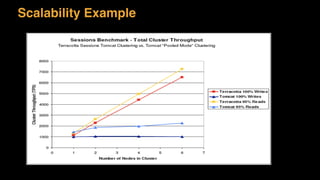



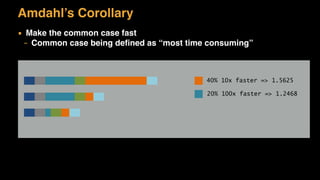









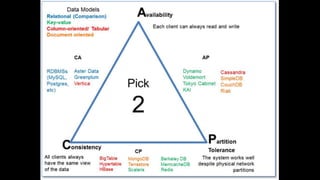






The document discusses session state in distributed web applications. It describes how session state can be stored on the client, server, or database. Storing state on the client limits scalability but is simplest, while storing in a database improves scalability but can become a bottleneck. The document also discusses design patterns for microservices including loose coupling, high cohesion, and bounded contexts. Services should be loosely coupled and have high cohesion to group related functionality together.





































































































