Download as PDF, PPTX





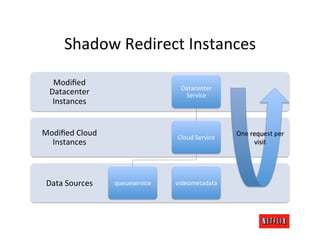



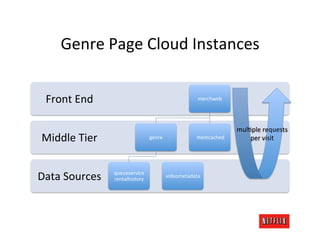




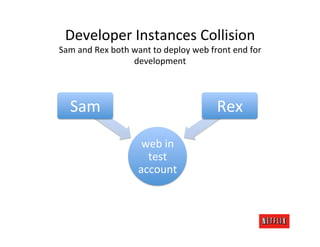













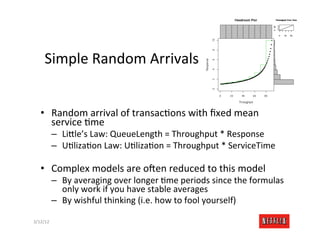














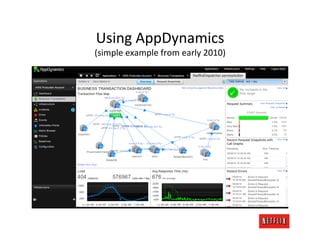
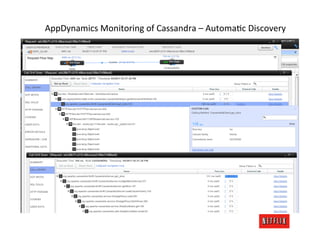


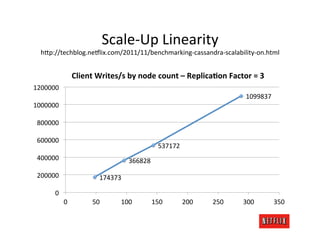
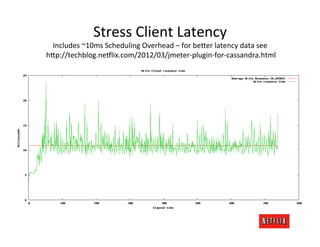
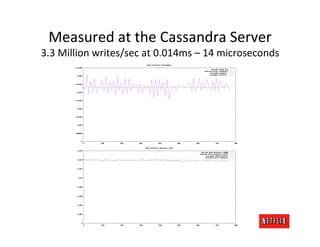
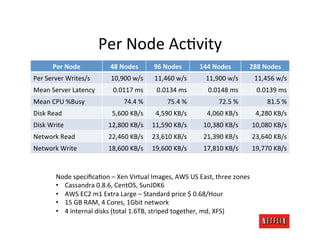
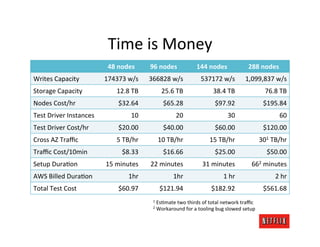



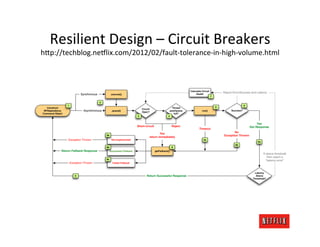






The document discusses cloud architecture and deployment strategies utilized by Netflix, detailing their capacity planning, cloud testing, and workload management. It emphasizes the importance of monitoring scalability, availability, and resilience while transitioning services from on-premises to cloud platforms. Additionally, the complexities of managing varying workloads and the optimizations made in their use of Cassandra for data management are highlighted.



















































![UNIT I -Introduction to CLOUD COMPUTING [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uniti-introductiontocloudcomputingautosaved-250128091123-f66abd14-thumbnail.jpg?width=640&height=640&fit=bounds)



























