Download to read offline



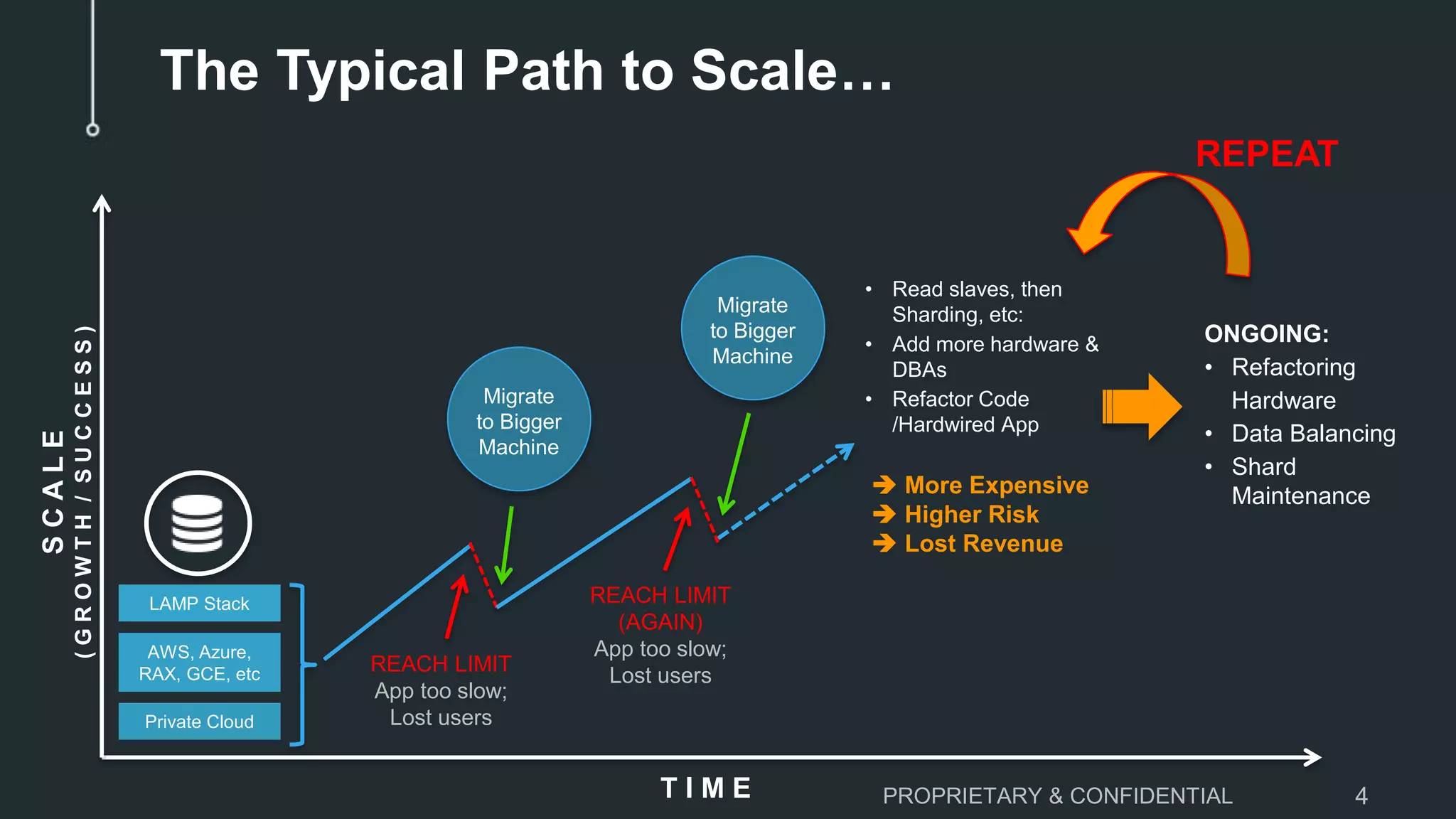

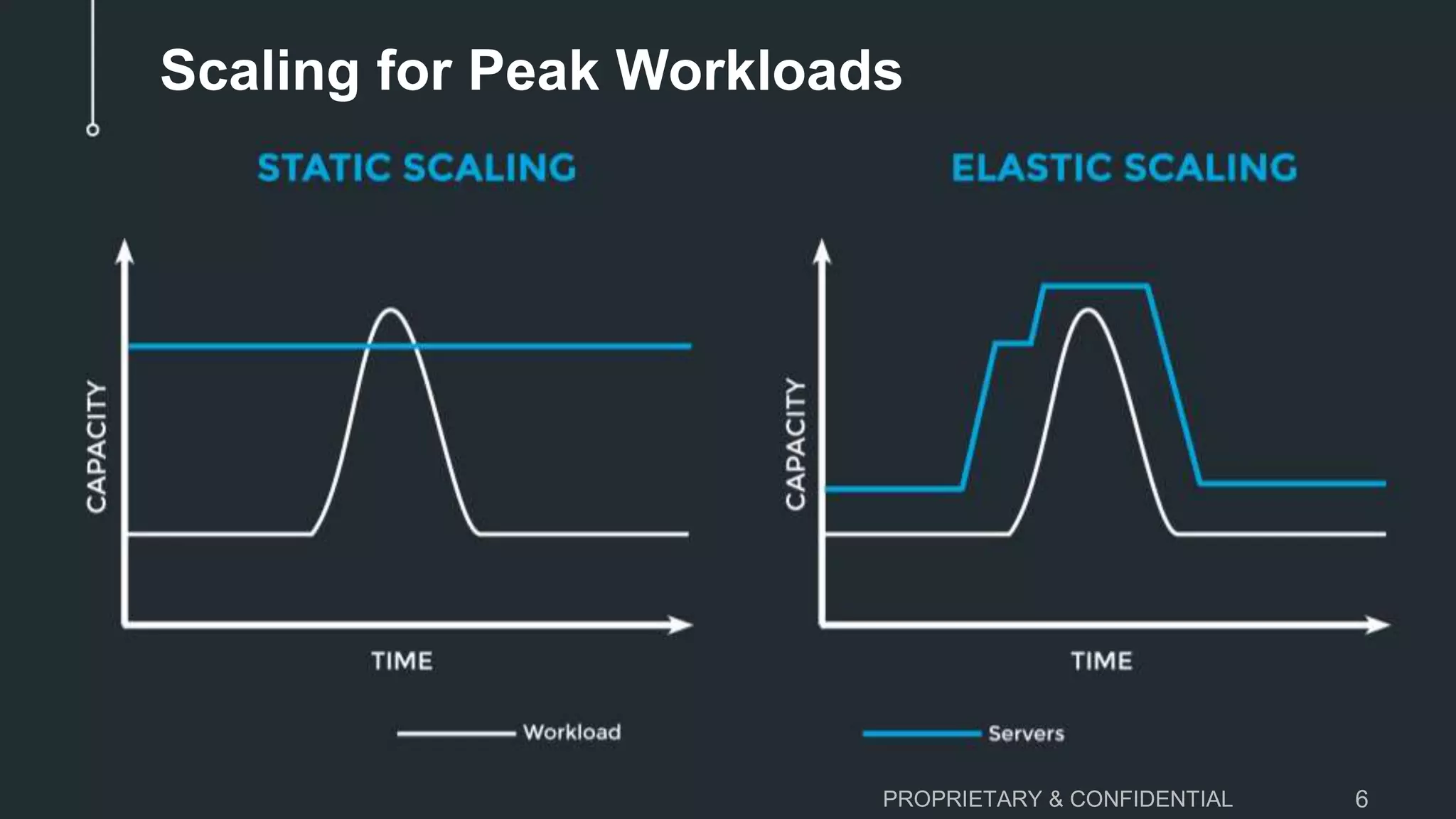





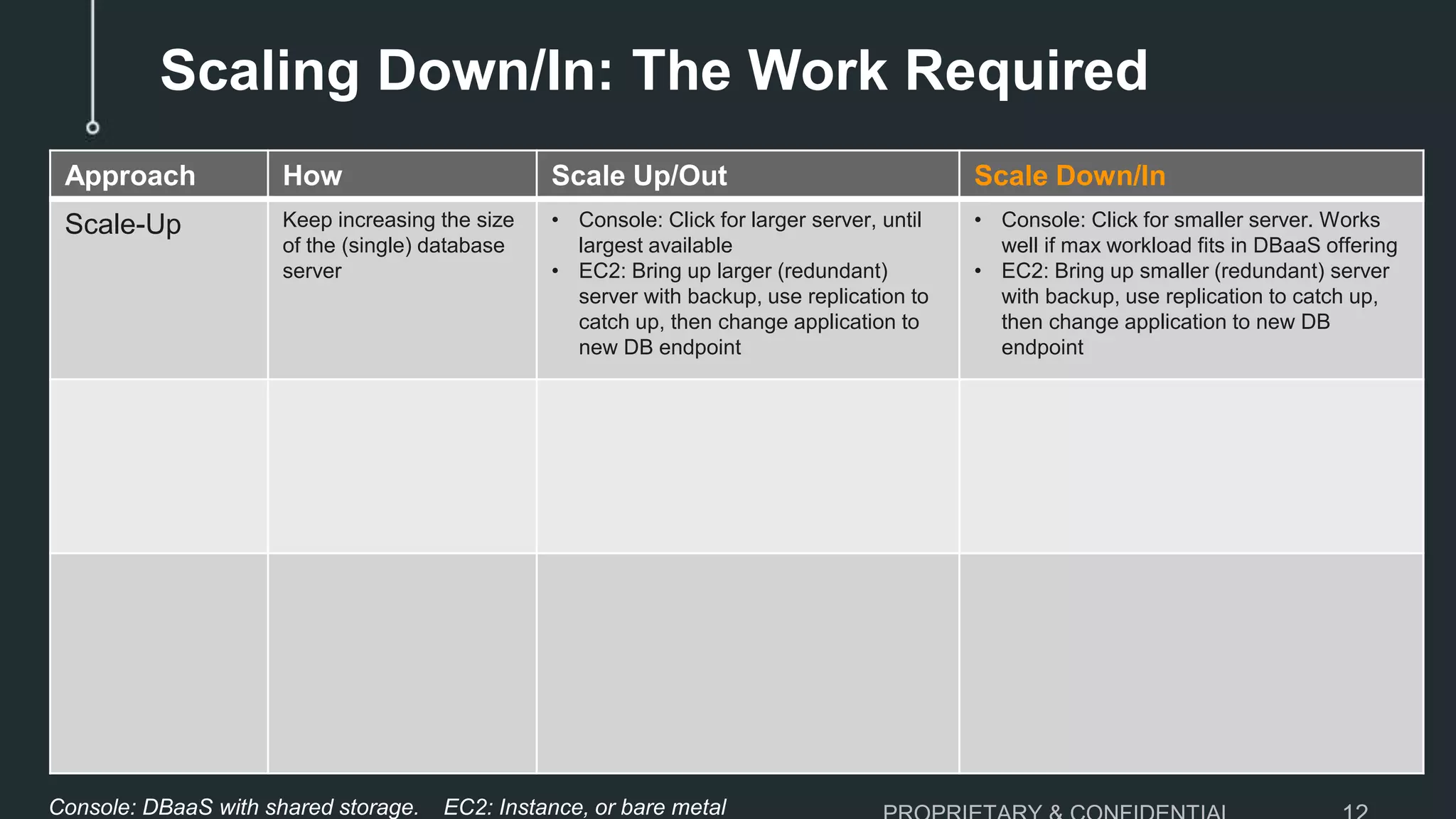


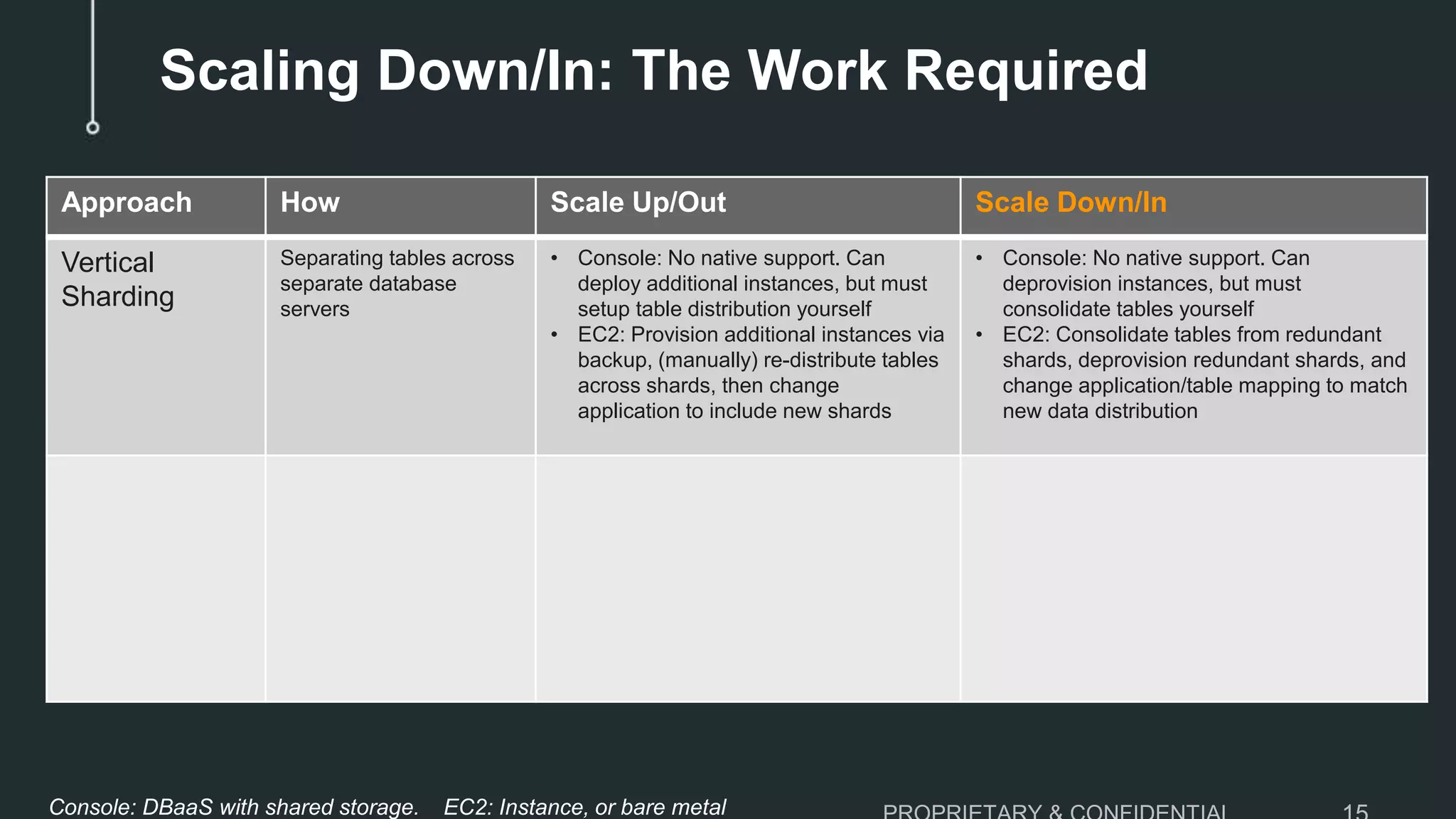














The document discusses the challenges of scaling down MySQL databases and emphasizes the importance of managing resources efficiently to avoid unnecessary costs, particularly during peak workloads. It outlines various scaling strategies and the implications of overprovisioning on budgets and operational efficiency. The advantages of ClustrixDB for flexible scaling compared to traditional MySQL solutions are highlighted, particularly in handling dynamic workloads and scaling requirements.

































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)








![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)



