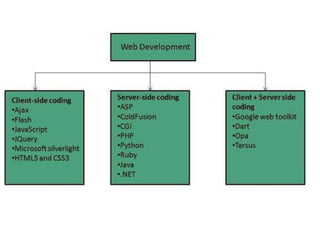
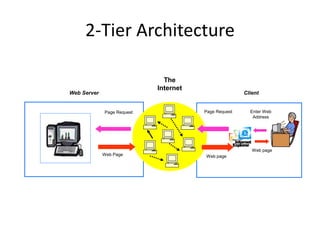
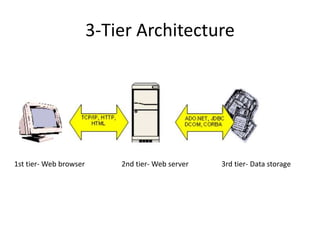
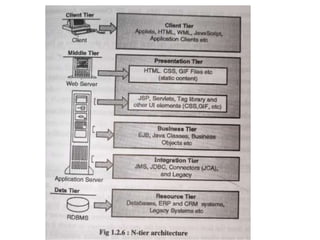
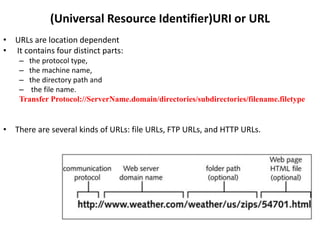
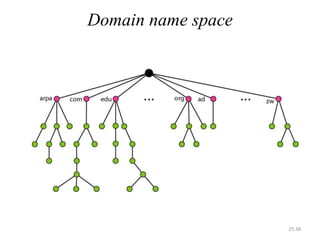
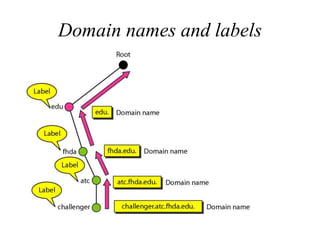
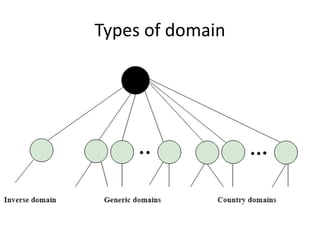
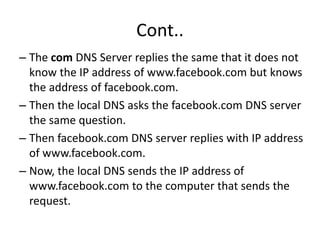
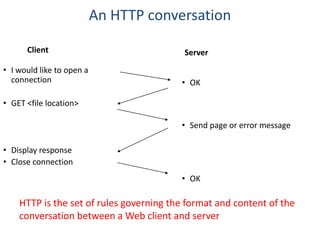
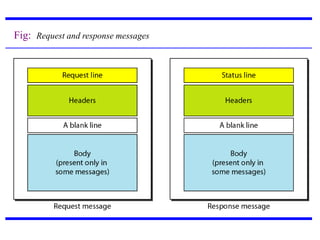
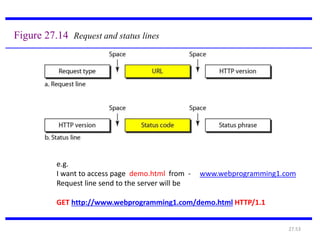
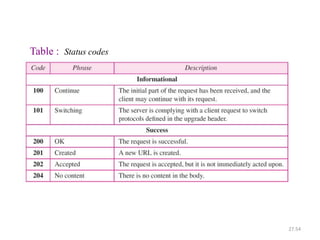
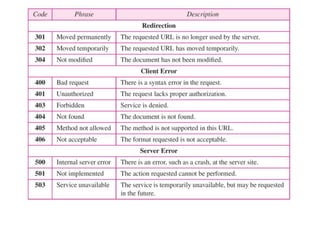
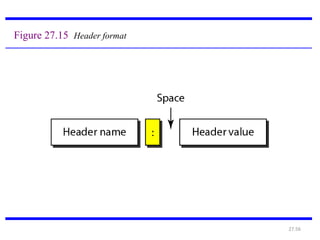
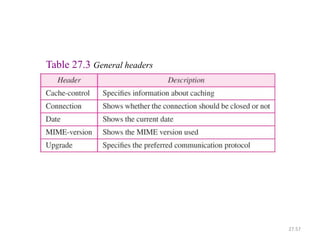
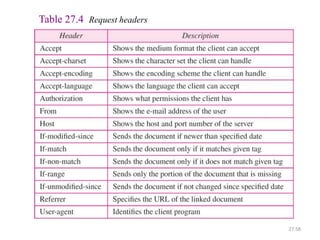
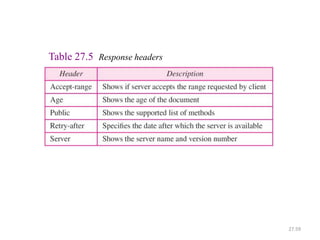
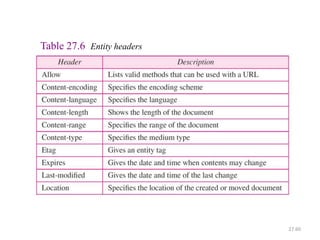
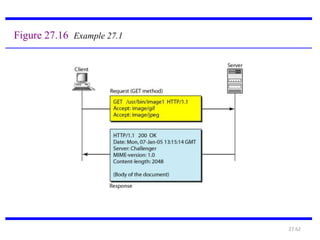
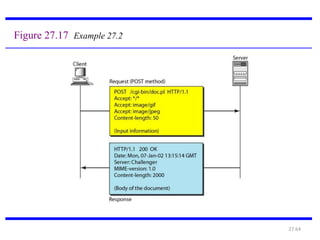
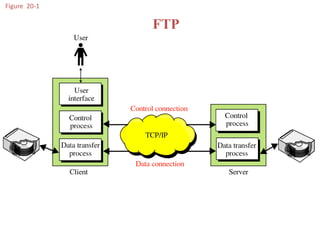
The document provides an introduction to web technology and programming, detailing the differences between client-side and server-side programming, as well as various architectures like single-tier, two-tier, three-tier, and n-tier. It explains essential components of the web, including URLs, IP addresses, DNS, and HTTP protocols, while discussing their functionalities and interrelationships. Overall, it outlines the infrastructure of web applications and the principles of web development.