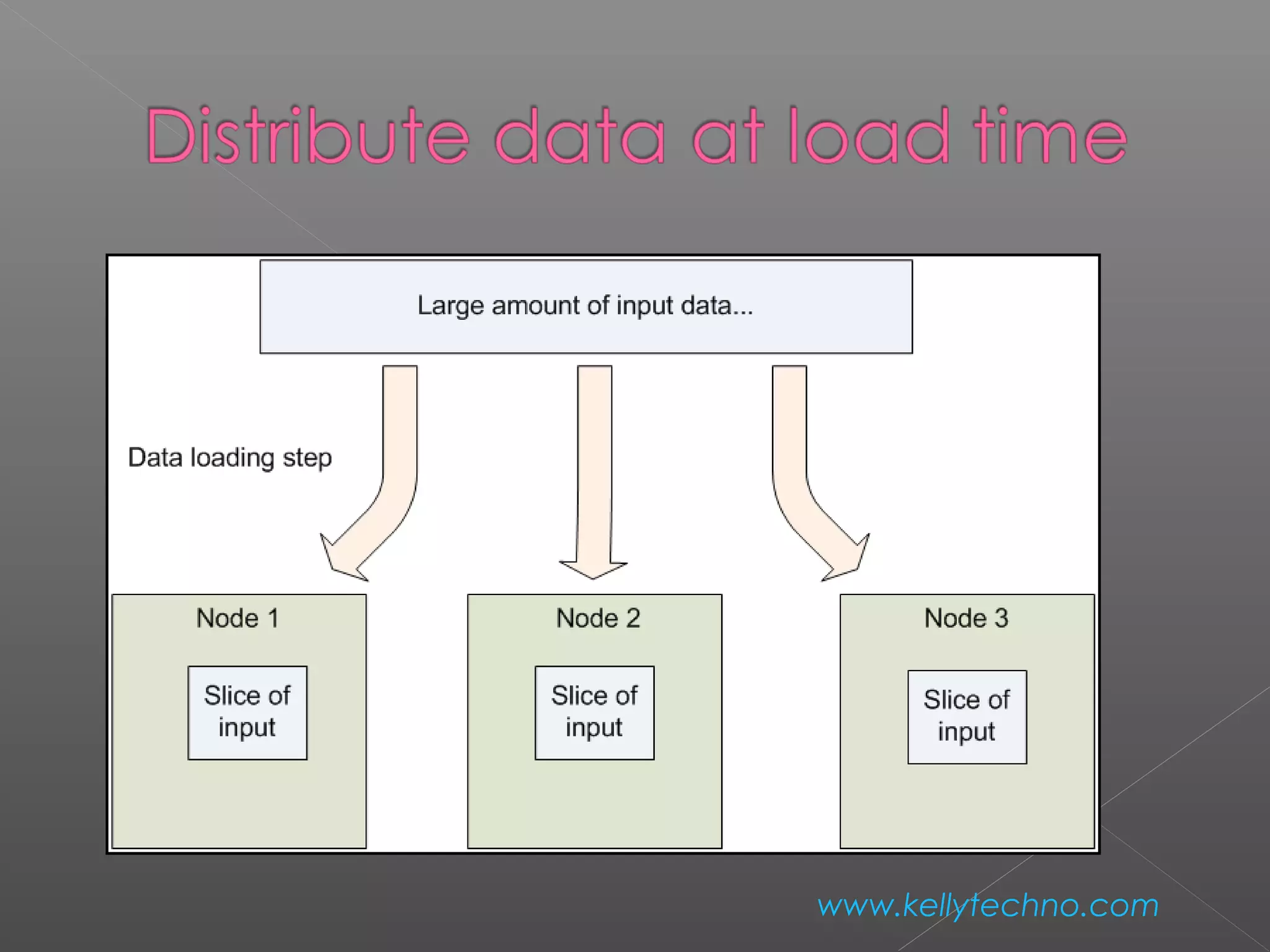
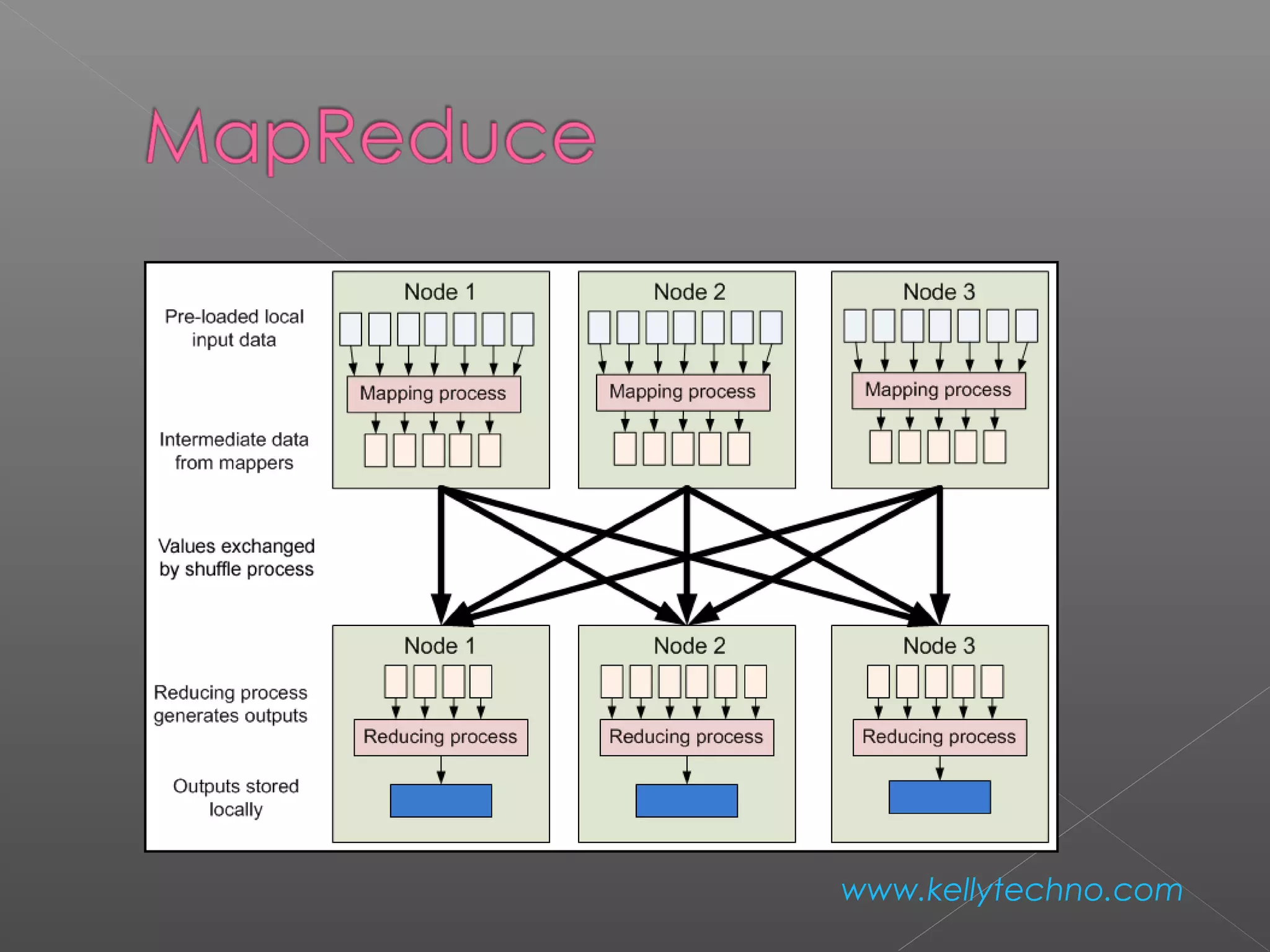
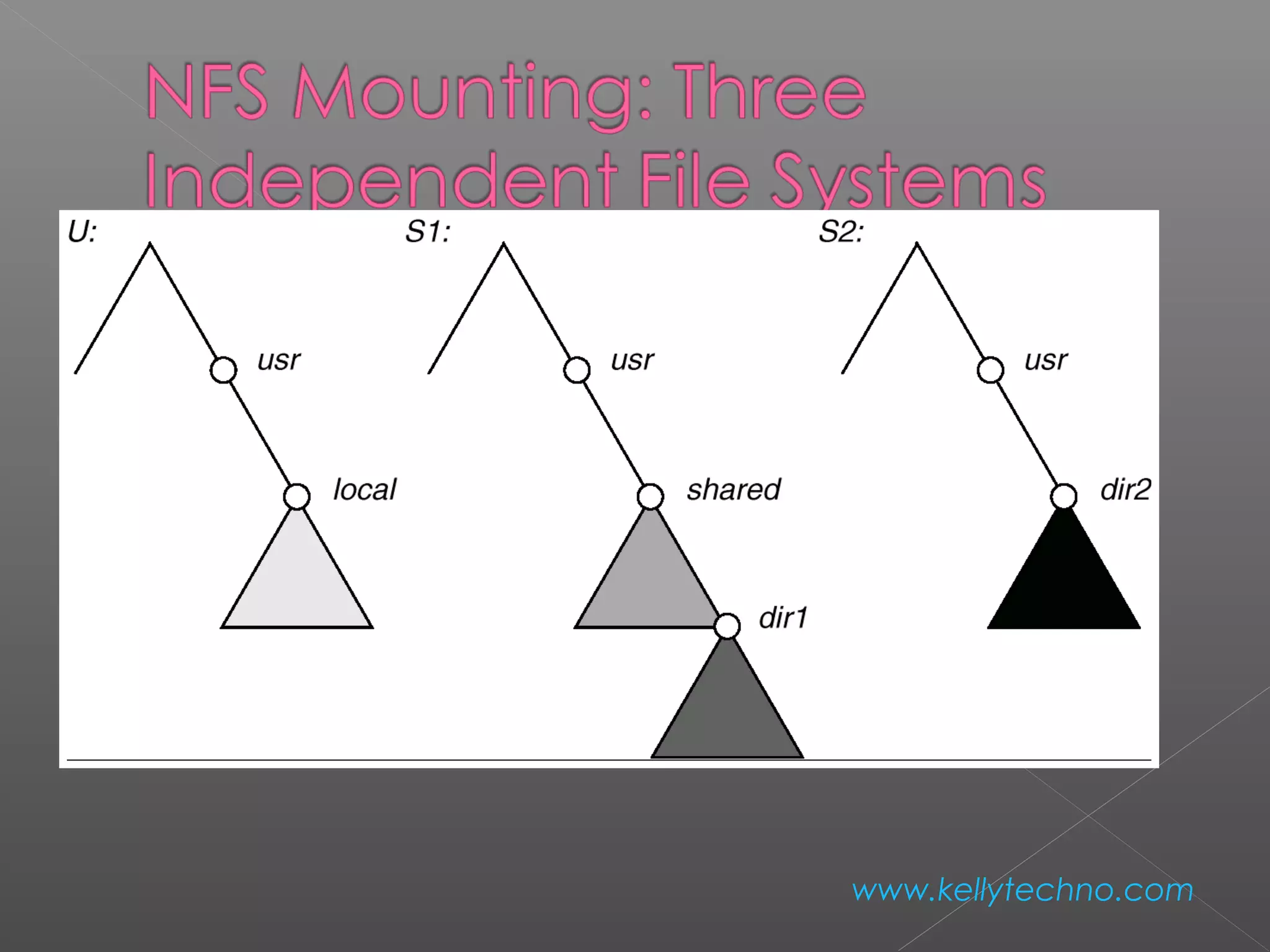
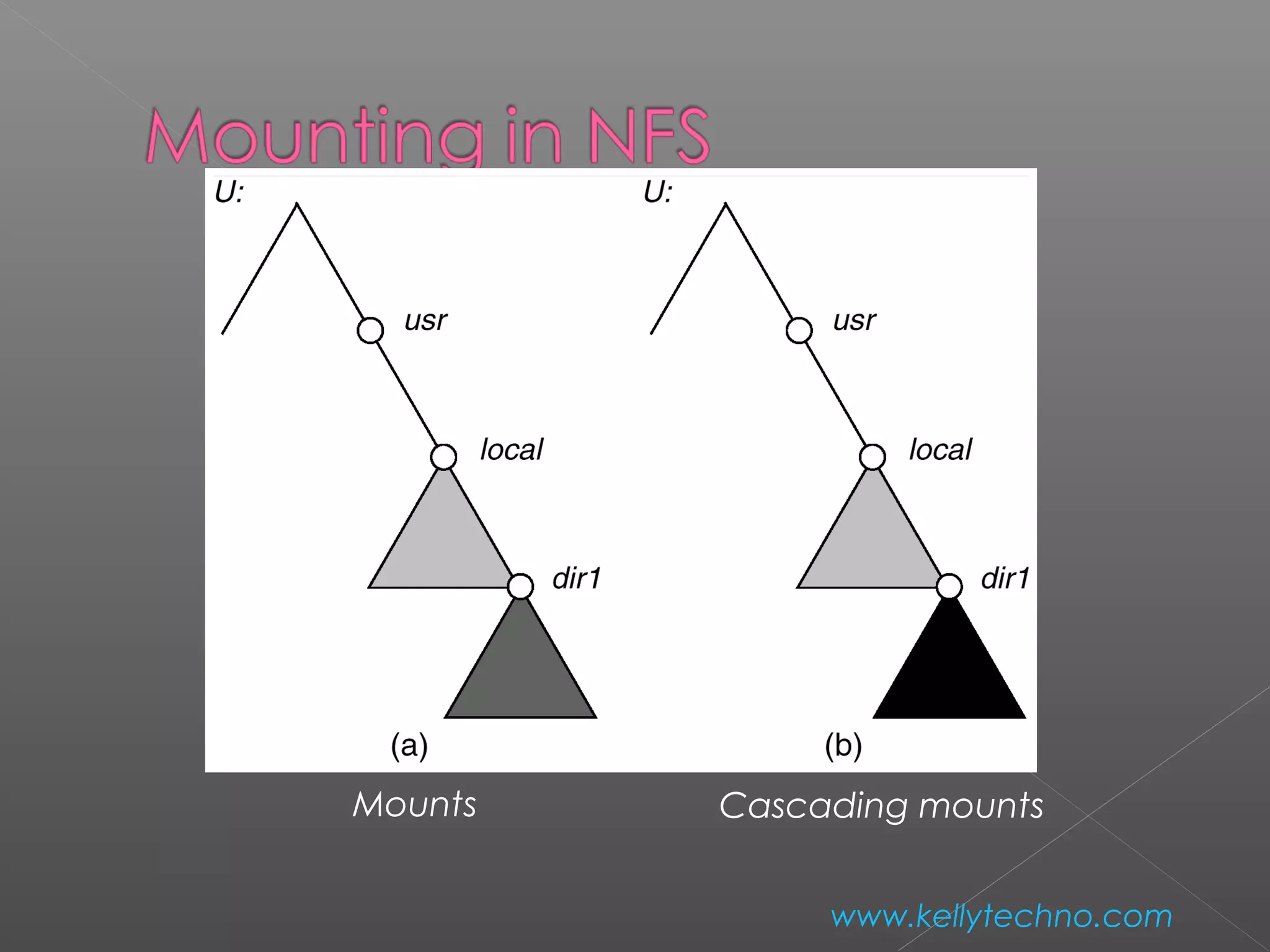
The document provides an overview of Hadoop and HDFS, highlighting their capabilities in managing large data across distributed systems, with an emphasis on their programming model and data replication features. It contrasts Hadoop's approach to communication and data handling with traditional MPI and grid computing models, while also discussing NFS's function as a network file system. Advantages and disadvantages of HDFS, including support for large file sizes and reliable data storage, are detailed, along with configuration instructions for setting up a Hadoop environment.