Download as PDF, PPTX








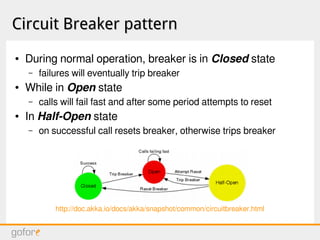




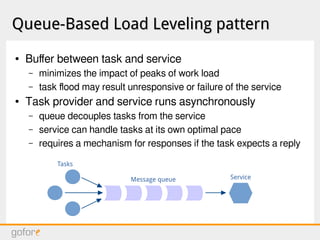



















The document discusses software architecture principles for cloud infrastructure, including microservices, distributed computing fallacies, designing for failure, and new design patterns like cache-aside, circuit breaker, and event sourcing. It also covers topics like autoscaling, asynchronous messaging, reactive streams, configuration management, and challenges like software erosion and failures cascading in distributed systems. The overall message is that building distributed systems on cloud infrastructure requires adopting new architectural patterns to deal with failures and improve scalability, performance and resilience.

















































































