Recommended
PPTX
PDF
PDF
PDF
PDF
PDF
PDF
東京都市大学 データ解析入門 6 回帰分析とモデル選択 1
PDF
PDF
PDF
東京都市大学 データ解析入門 8 クラスタリングと分類分析 1
PDF
PDF
PPTX
PDF
東京都市大学 データ解析入門 7 回帰分析とモデル選択 2
PDF
東京都市大学 データ解析入門 9 クラスタリングと分類分析 2
PDF
MLaPP 9章 「一般化線形モデルと指数型分布族」
PDF
PDF
PDF
PDF
PDF
東京都市大学 データ解析入門 10 ニューラルネットワークと深層学習 1
PPTX
KEY
PDF
正則化つき線形モデル(「入門機械学習第6章」より)
PDF
PDF
PPT
PDF
PDF
PDF
More Related Content
PPTX
PDF
PDF
PDF
PDF
PDF
PDF
東京都市大学 データ解析入門 6 回帰分析とモデル選択 1
PDF
What's hot
PDF
PDF
東京都市大学 データ解析入門 8 クラスタリングと分類分析 1
PDF
PDF
PPTX
PDF
東京都市大学 データ解析入門 7 回帰分析とモデル選択 2
PDF
東京都市大学 データ解析入門 9 クラスタリングと分類分析 2
PDF
MLaPP 9章 「一般化線形モデルと指数型分布族」
PDF
PDF
PDF
PDF
PDF
東京都市大学 データ解析入門 10 ニューラルネットワークと深層学習 1
PPTX
KEY
PDF
正則化つき線形モデル(「入門機械学習第6章」より)
PDF
PDF
PPT
PDF
Similar to ラビットチャレンジレポート 応用数学
PDF
PDF
PDF
PDF
PDF
PDF
PDF
Math in Machine Learning / PCA and SVD with Applications
PPTX
【招待講演】パラメータ制約付き行列分解のベイズ汎化誤差解析【StatsML若手シンポ2020】
PDF
PDF
PDF
PDF
PDF
PDF
PDF
Rabitt challenge mathematics
PDF
PDF
PDF
PDF
PDF
ラビットチャレンジレポート 応用数学 1. 2. 3. 4. 5. 6. 7. 逆行列
𝐴 を正方行列とし, I を同じ大きさの単位行列とする。
このとき、
𝐴𝐴−1
= 𝐴−1
𝐴= I
が成り立つような正方行列𝐴−1が存在するとき,これを𝐴の逆行列と
いう。
• 行列的に積が1になるイメージ
• 両辺に逆行列をかけることで式変形するようなときに便利
• 例: AB = C ⇒ B = 𝐴−1C ※ 行列の場合はA で割らない
1.1.逆行列(2/2)
8. 逆行列を持つには
定義の通り正方行列であること
行列式 ≠ 0
⇔ det (A) ≠ 0
⇔ |A| ≠ 0
※以下は2次正方行列の場合
⇔
𝑎 𝑏
𝑐 𝑑
とすると a : b ≠ c : d
⇔ ad – bc ≠ 0
⇔ 𝑣1 = (a b) , 𝑣2 = (c d)のとき 𝑣1, 𝑣2が1次独立
ちなみに逆行列は
1
𝑎𝑑−𝑏𝑐
𝑑 −𝑏
−𝑐 𝑎
1.2.行列式(1/2)
9. 10. 固有値・固有ベクトル
𝐴𝑥 = 𝜆𝑥 となるx (ベクトルの矢印が面倒なので太字)とλが存在
このときxを固有ベクトル、λを固有値と呼ぶ。
なお、Aは正方行列。 x ≠0
意味としては、xを行列Aで変換すると、 xはそのままにλ倍(スカ
ラー倍)になるイメージ
1.3.固有値分解(1/7)
11. 固有値分解
Ax = λx
⇔ 一旦行列表現をして AX = XΛ
⇔ 右からX−1をかけて A = XΛX−1
このように、3つの行列の積に分解できる。
つまり、固有値と固有ベクトルを求めれば、Aを分解できる
1.3.固有値分解(2/7)
12. 固有値・固有ベクトル導出
1 4
2 3
Ax = λx
⇔ Ax – λx = 0
⇔ ( A – λI )x = 0 ← Aは行列なので引き算するにはλI
⇔ 定義よりx ≠ 0 である。また、 A – λI が逆行列を持ってしまうと
両辺に左から A – λIの逆行列をかけることで、x = 0 と
なってしまうので、これはx ≠ 0 に矛盾するため、
A – λIは逆行列を持たない
⇔ | A – λI | = 0 ← 行列式が0となると逆行列を持たない、だった
1.3.固有値分解(3/7)
13. 固有値・固有ベクトル導出(続き)
1 4
2 3
⇔ |
1 4
2 3
–
λ 0
0 λ
| = 0
⇔ |
1 − λ 4
2 3 − λ
| = 0
⇔ (1 – λ)(3 – λ) – 8 = 0
⇔ 3 – λ – 3λ + 𝜆2 - 8 = 0
⇔ 𝜆2
- 4λ - 5 = 0
⇔ (λ – 5)(λ + 1) = 0 ∴ λ = 5, -1
1.3.固有値分解(4/7)
14. 固有値・固有ベクトル導出(続き)
1 4
2 3
( A – λI ) x = 0 だったため、これに代入
(1) λ = 5のとき
1 − 5 4
2 3 − 5
𝑥
𝑦 = 0
⇔
−4 4
2 −2
𝑥
𝑦 = 0 ⇔ 2x – 2y = 0 ⇔ x = y
⇔ x = y = C(Cは任意の定数) とすると、
𝑥
𝑦 = C
1
1
つまり、固有ベクトルの1つは
1
1
※C=2として
2
2
でもよい
1.3.固有値分解(5/7)
15. 固有値・固有ベクトル導出(続き)
1 4
2 3
同様に、
(2) λ = -1のとき
2 4
2 4
𝑥
𝑦 = 0
⇔2x + 4y = 0 ⇔ x =-2 y
⇔ y = C(Cは任意の定数) とすると、
𝑥
𝑦 = C
−2
1
つまり、固有ベクトルの1つは
−2
1
1.3.固有値分解(6/7)
16. 固有値・固有ベクトル導出(最後)
1 4
2 3
A = XΛX−1
だったので
A =
1 −2
1 1
5 0
0 −1
1 −2
1 1
−1
← Xは固有ベクトルを並べたもの
=
1 −2
1 1
5 0
0 −1
1/3 2/3
−1/3 1/3
1.3.固有値分解(7/7)
17. 18. 19. 特異値・特異ベクトル(続き)
一旦、行列表現をして、
AV = UΣ ※V, Uは直行行列
⇔ A = UΣ𝑉−1
⇔ A = UΣ𝑉T
← 直行行列のため 𝑉−1
= 𝑉T
⇔ 𝐴T
= (UΣ𝑉T
)T
= VΣT
𝑈T
← (AB)
T
= 𝐵T
𝐴T
ここで、
𝐴𝐴T = UΣ𝑉TVΣT𝑈T = UΣ ΣT𝑈T ← 𝑉TV = 𝑉−1V = I
𝐴T
𝐴 = VΣT
𝑈T
UΣ𝑉T
= VΣT
Σ𝑉T
𝐴𝐴T
= A´と見てみると、A´は正方行列であり
、 固有値・固有ベクトルの式(A´ = VΛ𝑉−1
)と同じ。
固有値・固有ベクトルを求めることができる。(𝐴T
𝐴も同様)
1.4.特異値分解(3/10)
20. 特異値・特異ベクトル導出(続き)
1 2 3
3 2 1
𝐴𝐴T = UΣ ΣT𝑈T
⇔ 𝐴𝐴TU = UΣ ΣT
⇔ ( A´ – Σ´)U = 0 ← 一旦 A´ = 𝐴𝐴T, Σ´ = Σ ΣT とみなす
⇔ |
1 2 3
3 2 1
1 3
2 2
3 1
-
σ´ 0
0 σ´
| = 0
⇔ |
14 − σ´ 10
10 14 − σ´
| = 0
⇔ (14 – σ´)(14 – σ´) – 100 = 0
⇔ (σ ´ – 24)(λ´ - 4) = 0
⇔ σ ´ = 4, 24
1.4.特異値分解(4/10)
21. 特異値・特異ベクトル導出(続き)
1 2 3
3 2 1
(1)σ ´ = 24のとき
⇔
14 − 24 10
10 14 − 24
𝑥
𝑦 = 0
⇔ -x + y = 0
⇔ y = C(Cは定数)とすると x = C なので、
𝑥
𝑦 = C
1
1
(2)σ ´ = 4のとき
x + y = 0 ⇔ y = Cとするとx = -Cなので、
𝑥
𝑦 = C
−1
1
1.4.特異値分解(5/10)
22. 特異値・特異ベクトル導出(続き)
1 2 3
3 2 1
∴ U =
1/√2 −1/√2
1/√2 1/√2
← 単位ベクトルのため大きさ1
したがって、A = UΣ𝑉T
=
1/√2 −1/√2
1/√2 1/√2
√24 0
0 √4
𝑉T
※ ΣΣT
=
𝜎1 0 0
0 𝜎2 0
𝜎1 0
0 𝜎2
0 0
=
𝜎1
2
0
0 𝜎2
2 のため、
固有値は√記号をとって、√24、√4となっている。
なお、𝜎1> 𝜎2 (特異値分解では対角線の左上が大きくなる)
1.4.特異値分解(6/10)
23. 特異値・特異ベクトル導出(続き)
1 2 3
3 2 1
A = UΣ𝑉T
, 𝐴T
= VΣT
𝑈T
だったので
𝐴T𝐴= VΣT𝑈TUΣ𝑉T = VΣTΣ𝑉T としてVも同じく求められる
𝐴T
𝐴 =
10 8 6
8 8 8
6 8 10
また、Aは2行3列のため、 A = UΣ𝑉T
からUは2行2列、Σは2行3列、 𝑉T
は3行3列。し
たがって、以下となり3番目の固有値を示す3行3列目が0のため、
3つ目の固有値は 0 となる。
ΣT
Σ =
𝜎1 0
0 𝜎2
0 0
𝜎1 0 0
0 𝜎2 0
=
𝜎1
2
0 0
0 𝜎2
2
0
0 0 0
1.4.特異値分解(7/10)
24. 特異値・特異ベクトル導出(続き)
1 2 3
3 2 1
λ = 24, 4, 0でそれぞれ固有ベクトルを求めて
V =
1/√3 1/√2 1/√6
1/√3 0 −2/√6
1/√3 −1/√2 1/√6
となるため、
𝑉T =
1/√3 1/√3 1/√3
1/√2 0 −1/√2
1/√6 −2/√6 1/√6
1.4.特異値分解(8/10)
25. 特異値・特異ベクトル導出(続き)
1 2 3
3 2 1
λ = 24, 4, 0でそれぞれ固有ベクトルを求めて
V =
1/√3 1/√2 1/√6
1/√3 0 −2/√6
1/√3 −1/√2 1/√6
のため、
𝑉T =
1/√3 1/√3 1/√3
1/√2 0 −1/√2
1/√6 −2/√6 1/√6
1.4.特異値分解(9/10)
26. 特異値・特異ベクトル導出(最後)
1 2 3
3 2 1
A = UΣ𝑉T より
A =
1/√2 −1/√2
1/√2 1/√2
√24 0 0
0 √4 0
1/√3 1/√3 1/√3
1/√2 0 −1/√2
1/√6 −2/√6 1/√6
1.4.特異値分解(10/10)
27. 特異値・特異ベクトル導出(最後)
A =
1/√2 −1/√2
1/√2 1/√2
√24 0 0
0 √4 0
1/√3 1/√3 1/√3
1/√2 0 −1/√2
1/√6 −2/√6 1/√6
A = ①×③×⑤ + ②×④×⑥ + ・・・・とすると
(1) k = 2
A = ①×③×⑤ + ②×④×⑥
(2) k = 1
A = ①×③×⑤
(3) これにより、元の行列Aの情報を徐々に削減することが可能。
1.5.次元削減
① ② ③
④
⑤
⑥
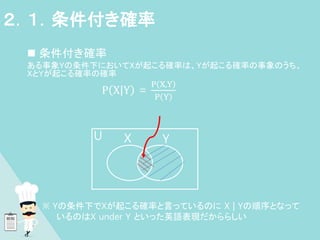
28. 29. 30. 31. ベイズの定例
因果関係を逆にできる
P |
X Y =
P X,Y
P Y
その逆は P |
Y X =
P X,Y
P X
でありP(X)を両辺にかけて
P |
Y X P(X) = P(X,Y)
したがって
P |
X Y =
P X,Y
P Y
=
P Y|X P(X)
P Y
このように、P(X|Y) が P(X), P(Y), P(Y|X)で表すことができる
、
2.2.ベイズの定例
32. 平均と期待値
X = 𝑥𝑖という値が観測される確率を𝑝𝑖、観測される回数を𝑁𝑖、とすると、
平均𝑥は 期待値μは
𝑥 = Σ 𝑥𝑖
𝑁𝑖
𝑁
μ = Σ 𝑥𝑖𝑝𝑖
N → ∞のとき、
𝑁𝑖
𝑁
= 𝑝𝑖
したがって、 𝑥 = μ。確率分布の期待値は母集団の平均値と一致する。
2.3.期待値/分散/共分散/標準偏差
33. 期待値
X = 𝑥𝑖という値が観測される確率を𝑝𝑖、観測される回数を𝑁𝑖、とすると、
平均𝑥は 期待値μは
𝑥 = Σ 𝑥𝑖
𝑁𝑖
𝑁
μ = Σ 𝑥𝑖𝑝𝑖
N → ∞のとき、
𝑁𝑖
𝑁
= 𝑝𝑖
したがって、 𝑥 = μ。確率分布の期待値は母集団の平均値と一致する。
※確率変数が連続する値の場合は期待値は、
∫P(x)f(x)dx
2.3.期待値/分散/共分散/標準偏差
34. 分散V(X)
一般的な定義より分散を期待値(平均値) E(X)で表す
期待値(平均値)をμとして(μ = E(X))
V(X) = Σ 𝑥𝑖 − μ 2
𝑝𝑖
= Σ(𝑥𝑖
2
𝑝𝑖 − 2μ𝑥𝑖𝑝𝑖 + 𝜇2𝑝𝑖 )
= Σ𝑥𝑖
2
𝑝𝑖 − 2μ × Σ𝑥𝑖𝑝𝑖 + 𝜇2Σ𝑝𝑖)
= E(𝑋2) – 2μ E(X) + 𝜇2𝑝𝑖
= E(𝑋2
) – 2E(X)×E(X) + 𝜇2
= E(𝑋2) – 2{E(X)}2 + {E(X)}2
= E(𝑋2
) – {E(X)}2
2.3.期待値/分散/共分散/標準偏差
35. 36. 共分散Cov(X, Y)
2つのデータ系列の傾向の違い
• 正の値を取れば似た傾向
• 負の値を取れば逆の傾向
• ゼロを取れば関係性に乏しい期待値
Cov(X, Y) = E{(X - μx)(Y − μy)}
= E(XY - Xμy- μxY +μxμy)
= E(XY) - E(X)μy - μxE(Y) + μxμy
= E(XY) – E(X)E(Y) – E(X)E(Y) + E(X)E(Y)
= E(XY) − E X E(Y)
2.3.期待値/分散/共分散
37. ベルヌーイ試行
コインの裏表のような二面事象
P(X = x) = 𝑝𝑥 1 − 𝑝 1−x x = 0, 1
• 期待値E(X)
E(X) = 1・ 𝑝 + 0 (1 – p)
= p
• 分散V(X)
V(X) = Σ 𝑥 − μ 2 p
= 1 − μ 2 p + 0 − μ 2 (1 – p)
μ = E(X) = pより
p - 𝑝3 - 𝑝2 + 𝑝3 = p - 𝑝2 = p(1 – p)
2.4.ベルヌーイ試行/二項分布/カテゴリカル分布/多項分布
38. 二項分布
ベルヌーイ試行の多試行版
P(X) = nCk 𝑝𝑘 1 − 𝑝 n−𝑘
• 期待値E(X)
1回1回は独立したベルヌーイ試行なので、1回の期待値はp
それがn回であるから
E(X) = np
• 分散V(X)
分散も同様に
V(X) = np(1 – p)
2.4.ベルヌーイ試行/二項分布/カテゴリカル分布/多項分布
39. 40. 多項分布
二項分布を多項に or カテゴリカル分布をn回に。
講義では問われていないようなので割愛。
期待値、分散は二項分布と同様。
2.4.ベルヌーイ試行/二項分布/カテゴリカル分布/多項分布
41. 42. 43. 44.