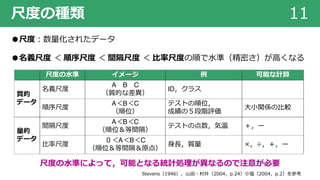
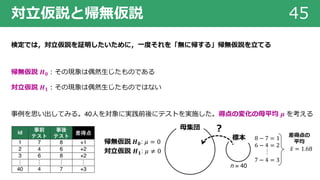
検定の⼿順 48
検定の⼿順
① 帰無仮説と対⽴仮説を設定する
②検定統計量を選択する
③ 有意⽔準を設定する
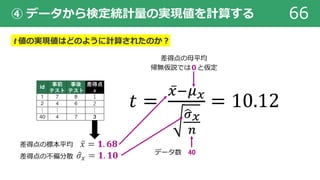
④ データから検定統計量の実現値を計算する
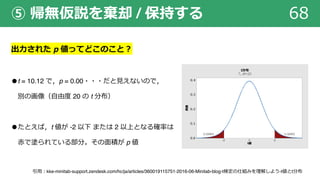
⑤ 帰無仮説を棄却 / 保持する
⼭⽥・村井(2004,p.122)を⼀部改
例. 対応のある t 検定(指導前後の得点の変化)
① 𝑯 𝟎: 𝜇 = 0,𝑯 𝟏: 𝜇 ≠ 0
② t 値
③ 5%
④ t = ○○.○○
⑤ p = .○○・・・,
p 値が 0.05(5%)以下なら
帰無仮説を棄却する
49.
対応のある t 検定の⼝語訳49
帰無仮説 𝑯 𝟎: 𝜇 = 0,対⽴仮説 𝑯 𝟏: 𝜇 ≠ 0
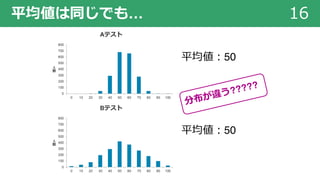
● 得点の変化の⺟平均が 0 であると仮定します(ホントは 0 じゃなさそうだけど)。
● データから t 値を計算しました。
● この t 値は t 分布にしたがうことがわかっています。
● 計算したt 値を取りうる p 値を計算してみると,とてもレアな確率になりました。
● ⺟平均が 0 という仮定がおかしかったのです。偶然とは思えません。
● そうだ︕ 実施した指導が得点の変化に影響を及ぼしたのではないでしょうか︕
50.
初学者にありがちな検定の⼿順 50
① 統計ソフトを⽴ち上げる
②統計ソフトのマニュアル本の⽬次から,
同じようなデータセットで分析している章を⾒つける
③ マニュアル本に書かれた⼿順に沿ってマウスをカチカチして,
有意差があることを祈りながら,p 値を出⼒する
④ 有意差があれば終了する。
なかったら,有意差がある組み合わせが⾒つかるまで検定を繰り返す
t 検定について 57
●t 検定は,⺟平均に対する検定である
● t 検定はデータに対応があるかどうかで計算式が変わる
ー対応なし(例.1組と2組のテストの平均点を⽐べる)
ー1つの平均値の検定
ー独⽴な 2 群の t 検定
ー対応あり(例.事前テストと事後テストの平均点を⽐べる)
ー対応のある t 検定
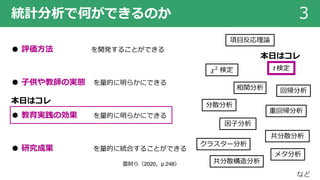
本⽇はコレ
p 値についての最近の議論 その174
●P値の誤⽤の蔓延に⽶国統計学会が警告(2016年3⽉10⽇)
https://doi.org/10.1038/ndigest.2016.160612
75.
p 値についての最近の議論 その275
●「“統計的に有意差なし”もうやめませんか」Natureに科学者800⼈超が
署名して投稿(2019年03⽉26⽇)
https://www.itmedia.co.jp/news/articles/1903/26/news112.html
76.
問題となる研究態度や⾏為 76
●p-hacking
有意な p値になるまでデータ分析を繰り返して,有意な値がでたら,
それを⽤いて論⽂を書こうとする態度
●HARKing(Hypothesizing After the Results are Known)
データを分析してみて結果を⾒てから,それにフィットするように仮説を作り,
あたかもその仮説がデータ収集よりも先に存在していたかのように論⽂化する⾏為
(参考︓https://tomsekiguchi.hatenablog.com/entry/20170727/1501136241)
引⽤・参考⽂献 85
南⾵原頼和(2002)『⼼理統計学の基礎 統合的理解のために』有斐閣
池⽥功毅・平⽯界(2016)「⼼理学における再現可能性危機︓問題の構造と解決策」『⼼理学研究』59(1),3-14.
川端⼀光・荘島宏⼆郎(2014)『⼼理学のための統計学1 ⼼理学のための統計学⼊⾨ ココロのデータ分析』誠信書房.
栗原伸⼀(2012)『⼊⾨統計学―検定から多変量解析・実験計画法』オーム社
⼩宮あすか・布井雅⼈(2018)『Excelで今すぐはじめる⼼理統計 簡単ツールHADで基本を⾝につける』講談社.
皆本昇弥(2015)『スッキリわかる確率統計―定理の詳しい証明つき―』近代科学社
Open Science Collaboration. (2015). Estimating the reproducibility of psychological science. Science, 349(6251). https://doi.org/10.1126/science.
aac4716
⼤久保街亜・岡⽥謙介(2012)『伝えるための⼼理統計 効果量 信頼区間 検定⼒』勁草書房
清⽔裕⼠ (2016 )「フリーの統計分析ソフトHAD︓機能の紹介と統計学習・教育,研究実践における利⽤⽅法の提案」『 メディア・情報・コ
ミュニケーション研究』 1, 59-73.
Stevens, S. S. (1946). On the Theory of Scales of Measurement. Science, 103(2684), 677–680.
雲財寛・⼭根悠平・⻄内舞・中村⼤輝(2020)「教科教育学における量的研究―分類と留意点―」『⽇本体育⼤学⼤学院教育学研究科紀要』
3(2), 245-252.
Wasserstein, R. L., & Lazar, N. A. (2016). The ASA Statement on p-Values: Context, Process, and Purpose. The American Statistician, 70(2),
129–133.
⼭⽥剛史・村井潤⼀郎(2004)『よくわかる⼼理統計』ミネルヴァ書房.


















































































![[DL輪読会]Deep Learning based Recommender System: A Survey and New Perspectives](https://cdn.slidesharecdn.com/ss_thumbnails/180907dldeeplearningbasedrecommendersystem-180928005638-thumbnail.jpg?width=640&height=640&fit=bounds)































