文献
B. Efron, T.Hastie, I. Johnstone, R. Tibshirani (2004). LEAST
ANGLE REGRESSION
H. Zou and T. Hastie (2005). Regularization and variable selection
via the elastic net
H. Zou, T. Hastie, and R. Tibshirani (2006). Sparse principal
component analysis.
R. Tibshirani (1996). Regression Shrinkage and Selection via the
Lasso
T. Hastie, R. Tibshirani, J. Friedman (2009). The Elements of
Statistical Learning 2nd Edition
G. James, D. Witten, T. Hastie R. Tibshirani (2014). An
Introduction to Statistical Learning
3 / 87
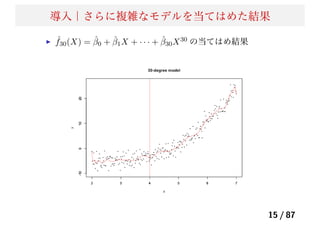
縮小推定法|リッジ回帰
リッジ回帰の主成分分析的な解釈
X の特異値分解 X= UDV T
を考える.
U : N × p, V : p × p の直交行列.D : p × p の対角行列.
X ˆβols = X(XT
X)−1
XT
y
= UUT
y
=
p
j=1
ujuT
j y
X ˆβridge = X(XT
X + λI)−1
XT
y
= UD(D2
+ λI)DUT
y
=
p
j=1
uj
d2
j
d2
j + λ
uT
j y
30 / 87
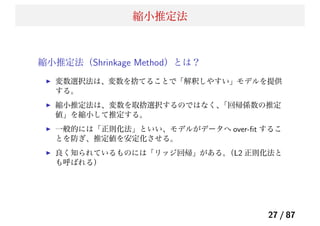
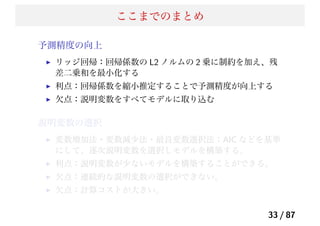
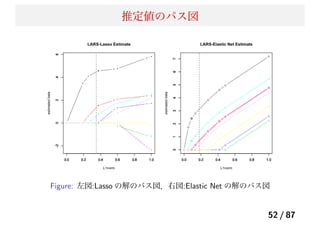
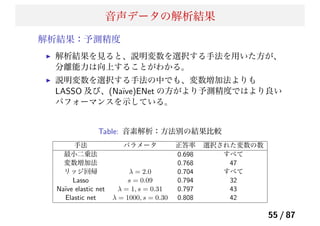
Lasso の課題
Lasso の問題点
p≫ n 問題 (West et al. 2001):p ≫ n の状況において、説明
変数が p 個あった場合でも、Lasso が選択できる説明変数の個
数は n 個である(分散共分散行列のランクが n になるため)。
グループ化効果がない:Lasso は変数間の相関を考慮できな
い。高い相関を持ついくつかの変数があるとき、それらをグ
ループ化された変数とよび、Lasso は、その中から 1 つしか
モデルに取り込むことはできない。
n > p での問題:説明変数間の相関が高い場合には、グルー
プ化変数を無視する性質によってリッジ回帰よりも予測精度
が悪くなることがある。
42 / 87
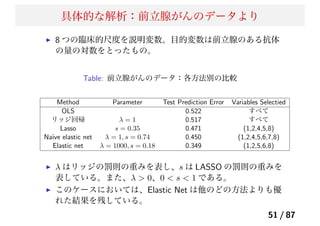
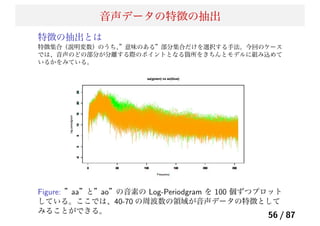
45.
Lasso の課題
Lasso が課題になる具体的な例
白血病の人の遺伝子データ,Golub et al. Science(1999)。
データのサンプル数 72 個, 説明変数の数 7129 個.(p ≫ n
問題)
遺伝子データでは、一般的に p ≈ 10000 で、サンプル数
n < 100 である。
遺伝子データでは、一般的に遺伝子同士の結合 (”Pathway”)
が似通っていることから、説明変数同士の相関が高いことが
多く、グループ化された変数が存在する。
→ 解決策の1つとして、(Na¨ıve) Elastic Net がある。
43 / 87
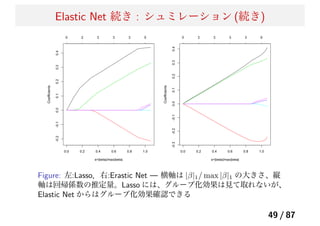
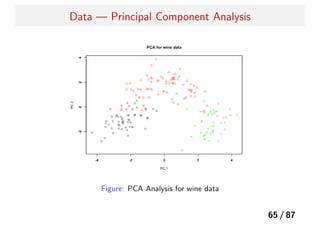
Problem — PrincipalComponent Analysis
Is it interpretable?? , unn...it’s difficult
結果の解釈をする際には、主成分ベクトルをスパース化したい!
しかし、主成分分析は「回帰」ではないが...
主成分分析は、「リッジ回帰の問題」として定式化できる。
よって、L1 正則化項によって elastic net の問題へ帰着.
67 / 87
70.
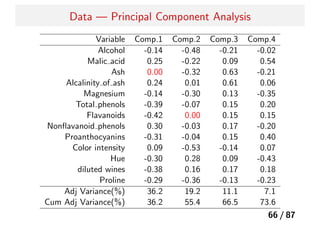
Theory — PrincipalComponent Analysis
X ∈ Rn×p
として、X の特異値分解を X = UDV T
とする。
このとき、UD を主成分、V を主成分に対応する”loadings”と呼ぶ。
PCA は、情報のロスが最小になるように主成分を構成する.
主成分同士は無相関であり、”loadings”同士は直交する.
別の定式化は...
ak = arg max aT
k (XT
X)ak (22)
subject to aT
k ak = 1 and aT
h ak = 0(j ̸= k) (23)
ここに追加で、以下の罰則をかけると SCoTLASS という方法にな
る.(計算量が爆発する)
p
j=1
|akj| ≤ t (24)
68 / 87
71.
Rewrite — PrincipalComponent Analysis
実は、PCA は Zi = UiDii としてリッジ回帰で書き直すことがで
きる。
ˆβridge = arg min
β
||Zi − Xβ||2
2 + λ||β||2
2 (25)
この解は
ˆβridge = (XT
X + λI)−1
XT
(XVi) = Vi
Dii
D2
ii + λ
(26)
となるので、
ˆvi = ˆβridge/||ˆβridge|| = Vi (27)
これによって、PCA とリッジ回帰と対応させることができた。
69 / 87
72.
Why Ridge Fomura?— Principal Component Analysis
リッジ回帰にしている理由は?
n > p で、X がフルランクの場合には、λ = 0 としても問題はない。
n < p の場合が問題で、回帰の解が一意に定まらなくなる。
(XT
X) の逆行列が存在しない。
一方で、n < p の場合に PCA の解は一意に定まるのでここの対応
を考える必要がある。
よって、リッジ回帰にするのが妥当.
70 / 87
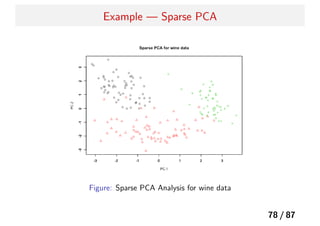
Sparse Principal Componentsbased on the SPCA
Criterion2
ここで、以下の等式に注意すると、
n
i=1
||xi − ABT
xi||2
= ||X − XBAT
||2
F (30)
A は直交行列なので、シュミットの直交化で正規直交基底行列 A⊥
を取り、直交行列 [A; A⊥]p×p を作ることができる。
すると、上記の右辺は次のように変形できる。
||X − XBAT
||2
F = ||XA⊥||2
F + ||XA − XB||2
F
= ||XA⊥||2
F +
k
j=1
||Xαj − Xβj||2
F
よって、次の式を最小化すれば解を得る
73 / 87
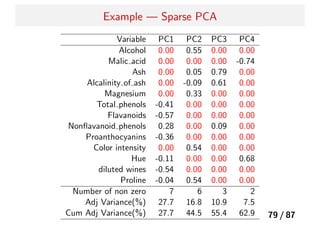
76.
Sparse Principal Componentsbased on the SPCA
Criterion3
A が与えられたもとで、最適な B は、次を最小化することで得ら
れる。
arg min
B
k
j=1
||Xαj − Xβj||2
+ λ||βj||2
つまり、k 個の独立したリッジ回帰の問題を解くことと同じである。
そして、この式に AT
A = Ik の条件の下で、L1 正則化を行った結
果がスパース主成分分析の解になる。
( ˆA, ˆB) = arg min
A,B
n
i=1
||xi − ABT
xi||2
+ λ
k
j=1
||βj||2
+
k
j=1
λ1,j||βj||1
(31)
74 / 87
77.
Numerical Solution1
A が与えられたもとでのB の最小化
各 j に対して、Y ∗
j = Xαj とする。このとき、 ˆB は elastic net の推
定量となる。
ˆβj = arg min
βj
||Y ∗
j − Xβj||2
+ λ||βj||2
+ λ1,j||βj||1 (32)
B が与えられたもとでの A の最小化
B が与えられているとき罰則項は無視することができる。
AT
A = Ik×k のもとで次式を最小化すればよい。
n
i=1
||xi − ABT
xi||2
= ||X − XBAT
||2
(33)
この解は、Procrustes rotation によって与えられる。
(XT
X)B = UDV T
と特異値分解を行うと、 ˆA = UV T
となる。
75 / 87
78.
アルゴリズム — NumericalSolution2
1. A に初期値 V [, 1 : k](k 個の主成分)を与える.
2. A を固定して、B について elastic net の問題を j = 1, 2, · · · , p につ
いて解く.
ˆβj = arg min
βj
||Y ∗
j − Xβj||2
+ λ||βj||2
+ λ1,j||βj||1 (34)
3. B を固定して、XT
XB を特異値分解して、UDV T
を求めて、
A = UV T
で更新する.
4. 2 と 3 のステップを収束するまで繰り返す。
5. ˆVj =
βj
||βj || (j = 1, · · · , k) を計算し、主成分ベクトルを求める。
76 / 87
参考文献
B. Efron, T.Hastie, I. Johnstone, R. Tibshirani (2004).
LEAST ANGLE REGRESSION
H. Zou and T. Hastie (2005). Regularization and variable
selection via the elastic net
H. Zou, T. Hastie, and R. Tibshirani (2006). Sparse principal
component analysis.
R. Tibshirani (1996). Regression Shrinkage and Selection via
the Lasso
T. Hastie, R. Tibshirani, J. Friedman (2009). The Elements
of Statistical Learning 2nd Edition
G. James, D. Witten, T. Hastie R. Tibshirani (2014). An
Introduction to Statistical Learning
85 / 87








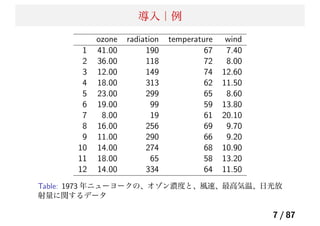

![導入|妥当な f(X) とは何か?
X が与えられたときの、f(X) の最適な値とは?
次の式を、最小にする g(X) を妥当なものだと考える。
arg min
g(X)
E[(Y − g(X))2
|X = x] (2)
最適な f(X) は、次のようになる(回帰関数と呼ぶ)。
f(X) = E(Y |X = x) (3)
10 / 87](https://image.slidesharecdn.com/present-140513080548-phpapp01/85/20140514_-_-10-320.jpg)
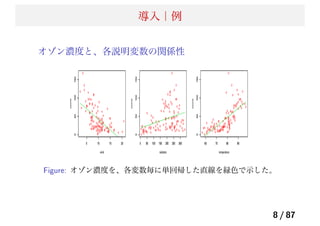
![導入| f(X) と誤差
f(X) と誤差
実際、Y が真のモデル f(X) から観測される際には、誤差が
ある。
ε = Y − f(x) を誤差という。
Y の観測値は真のモデルの値と誤差の和として観測される。
これは、X が与えられたときに観測される Y はある分布か
ら得られているため。
実際、全ての f(x) の推定量 ˆf(x) に対して、
E[(Y − ˆf(X))2
|X = x] = [f(x) − ˆf(x)]2
+ V ar(ε) (5)
1 項目は推定したモデルが真のモデルに近ければ小さくなる
2 項目は誤差分散で一定である。
12 / 87](https://image.slidesharecdn.com/present-140513080548-phpapp01/85/20140514_-_-12-320.jpg)
![導入|線形回帰モデル
線形回帰モデル
線形回帰モデルは、E[Y |X] に以下のモデルを仮定する。
fL(X) = β0 + β1X1 + · · · + βpXp (6)
線形回帰モデルは、p + 1 個のパラメータ β1, β2, · · · , βp に
よって特徴付けられるモデルである。
教師データに対して、モデルを当てはめることでパラメータ
β1, β2, · · · , βp を推定する
線形回帰モデルは(未知の)真のモデルの理解しやすい近似
としての役割を果たす。
ただし、真のモデルは(ほとんどの場合)与えない。
13 / 87](https://image.slidesharecdn.com/present-140513080548-phpapp01/85/20140514_-_-13-320.jpg)
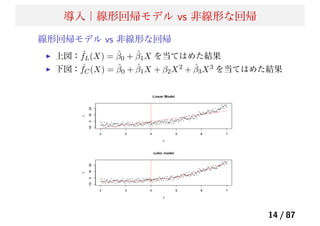

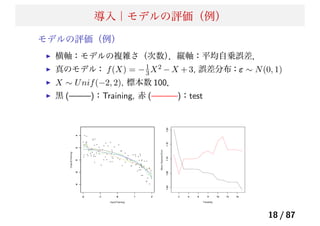
![導入|モデルの評価
モデルの評価:平均自乗誤差
1つの評価基準は「平均自乗誤差(MSE)」
教師データ Tr= {xi, yi}N
1 から、推定したモデル ˆf(x) に対して以
下を計算する。
MSET r = Avei∈T r[yi − ˆf(xi)]2
(7)
しかしながら、教師データなので、複雑なモデルの方が平均自乗誤
差は小さくなる
新たなテストデータ Te= {xi, yi}M
1 に対して、以下を計算する。
MSET e = Avei∈T e[yi − ˆf(xi)]2
(8)
17 / 87](https://image.slidesharecdn.com/present-140513080548-phpapp01/85/20140514_-_-17-320.jpg)





















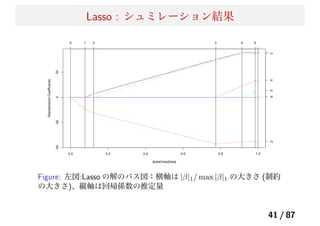





![Elastic Net 続き : グループ化効果
一般的に罰則付きの最小 2 乗推定量は、J(β) を罰則項として次のように表される。
ˆβ = arg min
β
|y − Xβ|2
+ λJ(β) (20)
ここで、β = (β1, · · · , βi, · · · , βj, · · · , βp)、β
′
= (β1, · · · , βj, · · · , βi, · · · , βp) とし
て、J(β) = J(β
′
) が成立することを仮定する。すると、次の補題が示せる。
補題
xi = xj (i, j ∈ 1, 2, · · · , p) であると仮定する。
(a) J(·) が狭義凸関数であるならば、 ˆβi = ˆβj が全ての λ > 0 に対して成り立つ。
(b) J(β) = |β|1 であるならば、ˆβi
ˆβj ≥ 0 かつ、 ˆβ∗ は方程式 (7) の異なる最小の値であ
り、全ての s ∈ [0, 1] に対して、以下が成立する。
ˆβ∗
k =
⎧
⎨
⎩
ˆβk if k ̸= i and k ̸= j,
(ˆβi + ˆβj) · (s) if k = i
(ˆβi + ˆβj) · (1 − s) if k = j
→ Lasso の罰則はグループ化効果を持たないことが示せる。一方の Elastic Net の罰則は
グループ化効果を持つことが示唆される。
47 / 87](https://image.slidesharecdn.com/present-140513080548-phpapp01/85/20140514_-_-49-320.jpg)
















![Sparse Principal Components based on the SPCA
Criterion1
しかしながら、先ほどの方法では主成分は PCA のまま UiDii であ
る。これを推定する方法を次に提案する。
2 段階の探索的な解析を行い、スパース PCs の近似を与える。
定理
第 1 主成分から、第 k 主成分までを考える。ここで、
Ap×k = [α1, · · · , αk]、Bp×k = [β1, · · · , βk] とすると、すべての λ > 0
に対して、AT
A = Ik×k の条件の下で、
( ˆA, ˆB) = arg min
A,B
n
i=1
||xi − ABT
xi||2
+ λ j = 1k
||βj||2
(29)
を解くと、ˆβj ∝ Vj (j = 1, · · · , p) となる。
72 / 87](https://image.slidesharecdn.com/present-140513080548-phpapp01/85/20140514_-_-74-320.jpg)
![Sparse Principal Components based on the SPCA
Criterion2
ここで、以下の等式に注意すると、
n
i=1
||xi − ABT
xi||2
= ||X − XBAT
||2
F (30)
A は直交行列なので、シュミットの直交化で正規直交基底行列 A⊥
を取り、直交行列 [A; A⊥]p×p を作ることができる。
すると、上記の右辺は次のように変形できる。
||X − XBAT
||2
F = ||XA⊥||2
F + ||XA − XB||2
F
= ||XA⊥||2
F +
k
j=1
||Xαj − Xβj||2
F
よって、次の式を最小化すれば解を得る
73 / 87](https://image.slidesharecdn.com/present-140513080548-phpapp01/85/20140514_-_-75-320.jpg)


を与える.
2. A を固定して、B について elastic net の問題を j = 1, 2, · · · , p につ
いて解く.
ˆβj = arg min
βj
||Y ∗
j − Xβj||2
+ λ||βj||2
+ λ1,j||βj||1 (34)
3. B を固定して、XT
XB を特異値分解して、UDV T
を求めて、
A = UV T
で更新する.
4. 2 と 3 のステップを収束するまで繰り返す。
5. ˆVj =
βj
||βj || (j = 1, · · · , k) を計算し、主成分ベクトルを求める。
76 / 87](https://image.slidesharecdn.com/present-140513080548-phpapp01/85/20140514_-_-78-320.jpg)












![[読会]A critical review of lasso and its derivatives for variable selection und...](https://cdn.slidesharecdn.com/ss_thumbnails/acriticalreviewoflassoanditsderivativesforvariableselectionunderdependenceamongcovariates-211229094859-thumbnail.jpg?width=640&height=640&fit=bounds)








































![[PRML] パターン認識と機械学習(第3章:線形回帰モデル)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter3-171003081954-thumbnail.jpg?width=640&height=640&fit=bounds)












