Download to read offline
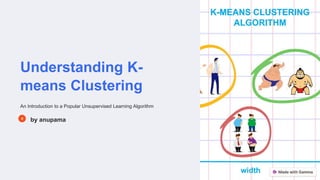
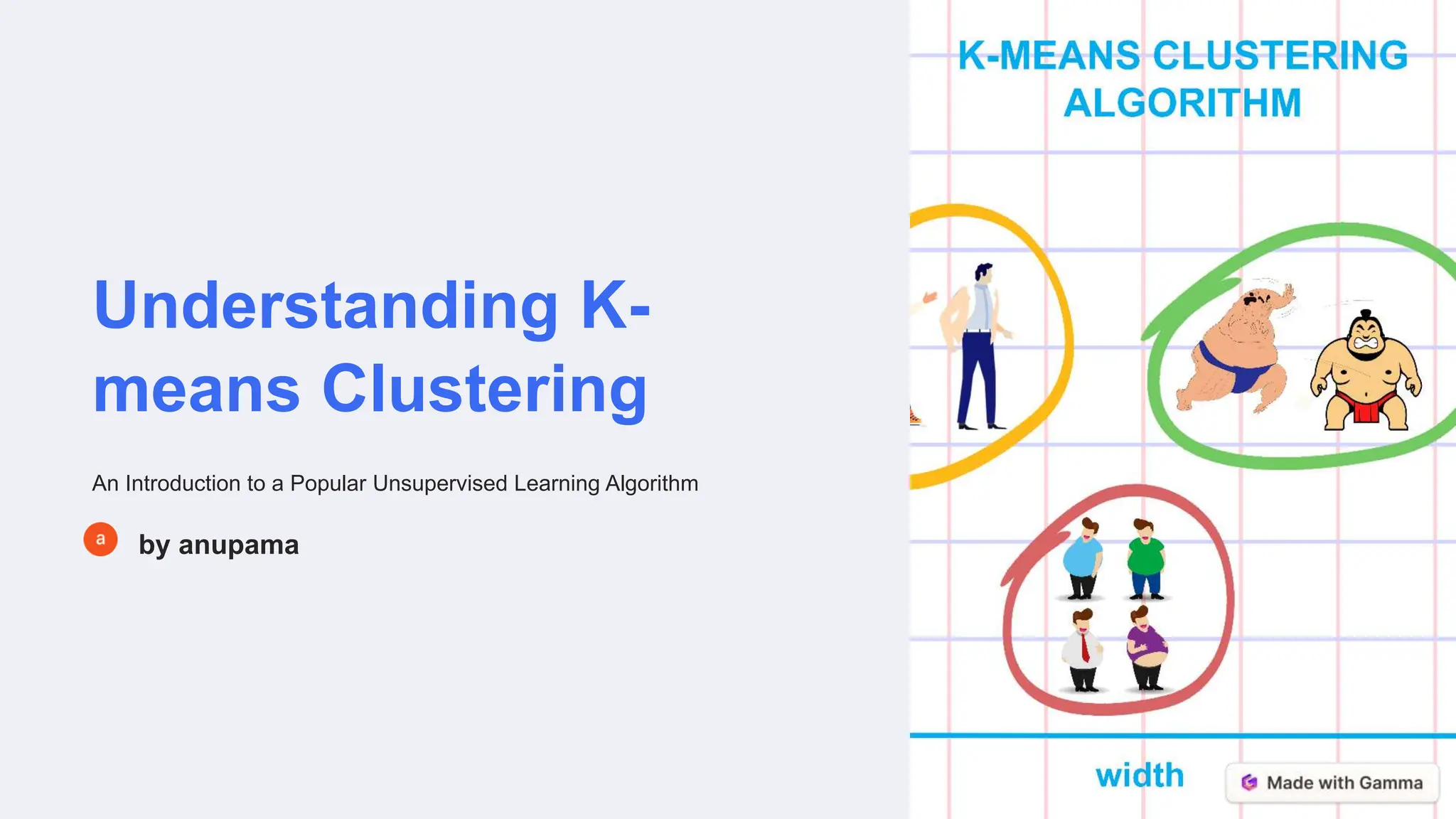








The document discusses K-means clustering, an unsupervised learning algorithm that partitions data into K clusters by minimizing variance. It works by iteratively assigning data points to the nearest centroid and updating centroid positions based on cluster means until convergence. The example shows initializing random centroids, assigning points to the closest centroid to form initial clusters, then recalculating centroids as the means of points in each cluster. This iterative process refines clusters with each update.















































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)



![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)














