Download as PDF, PPTX






![Why understand internals?
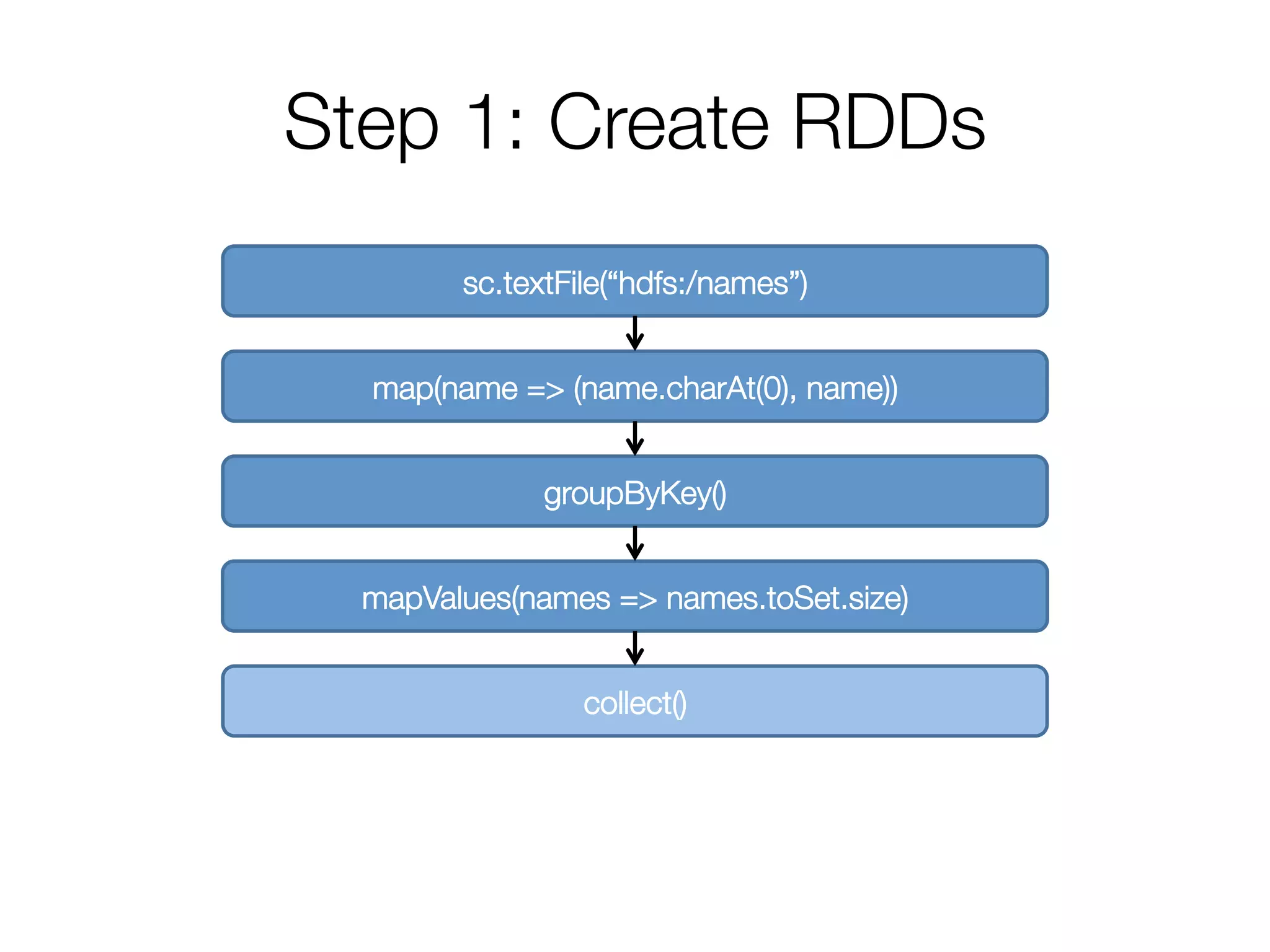
Goal: Find number of distinct names per “first letter”
sc.textFile(“hdfs:/names”)
.map(name => (name.charAt(0), name))
.groupByKey()
.mapValues(names => names.toSet.size)
.collect()
Andy
Pat
Ahir
(A, [Ahir, Andy])
(P, [Pat])
(A, Andy)
(P, Pat)
(A, Ahir)](https://image.slidesharecdn.com/a-deeper-understanding-of-spark-internals-aaron-davidson-150713152728-lva1-app6892/75/A-deeper-understanding-of-spark-internals-aaron-davidson-7-2048.jpg)
![Why understand internals?
Goal: Find number of distinct names per “first letter”
sc.textFile(“hdfs:/names”)
.map(name => (name.charAt(0), name))
.groupByKey()
.mapValues(names => names.toSet.size)
.collect()
Andy
Pat
Ahir
(A, [Ahir, Andy])
(P, [Pat])
(A, Andy)
(P, Pat)
(A, Ahir)](https://image.slidesharecdn.com/a-deeper-understanding-of-spark-internals-aaron-davidson-150713152728-lva1-app6892/75/A-deeper-understanding-of-spark-internals-aaron-davidson-8-2048.jpg)
![Why understand internals?
Goal: Find number of distinct names per “first letter”
sc.textFile(“hdfs:/names”)
.map(name => (name.charAt(0), name))
.groupByKey()
.mapValues(names => names.toSet.size)
.collect()
Andy
Pat
Ahir
(A, [Ahir, Andy])
(P, [Pat])
(A, Set(Ahir, Andy))
(P, Set(Pat))
(A, Andy)
(P, Pat)
(A, Ahir)](https://image.slidesharecdn.com/a-deeper-understanding-of-spark-internals-aaron-davidson-150713152728-lva1-app6892/75/A-deeper-understanding-of-spark-internals-aaron-davidson-9-2048.jpg)
![Why understand internals?
Goal: Find number of distinct names per “first letter”
sc.textFile(“hdfs:/names”)
.map(name => (name.charAt(0), name))
.groupByKey()
.mapValues(names => names.toSet.size)
.collect()
Andy
Pat
Ahir
(A, [Ahir, Andy])
(P, [Pat])
(A, 2)
(P, 1)
(A, Andy)
(P, Pat)
(A, Ahir)](https://image.slidesharecdn.com/a-deeper-understanding-of-spark-internals-aaron-davidson-150713152728-lva1-app6892/75/A-deeper-understanding-of-spark-internals-aaron-davidson-10-2048.jpg)
![Why understand internals?
Goal: Find number of distinct names per “first letter”
sc.textFile(“hdfs:/names”)
.map(name => (name.charAt(0), name))
.groupByKey()
.mapValues(names => names.toSet.size)
.collect()
Andy
Pat
Ahir
(A, [Ahir, Andy])
(P, [Pat])
(A, 2)
(P, 1)
(A, Andy)
(P, Pat)
(A, Ahir)
res0 = [(A, 2), (P, 1)]](https://image.slidesharecdn.com/a-deeper-understanding-of-spark-internals-aaron-davidson-150713152728-lva1-app6892/75/A-deeper-understanding-of-spark-internals-aaron-davidson-11-2048.jpg)

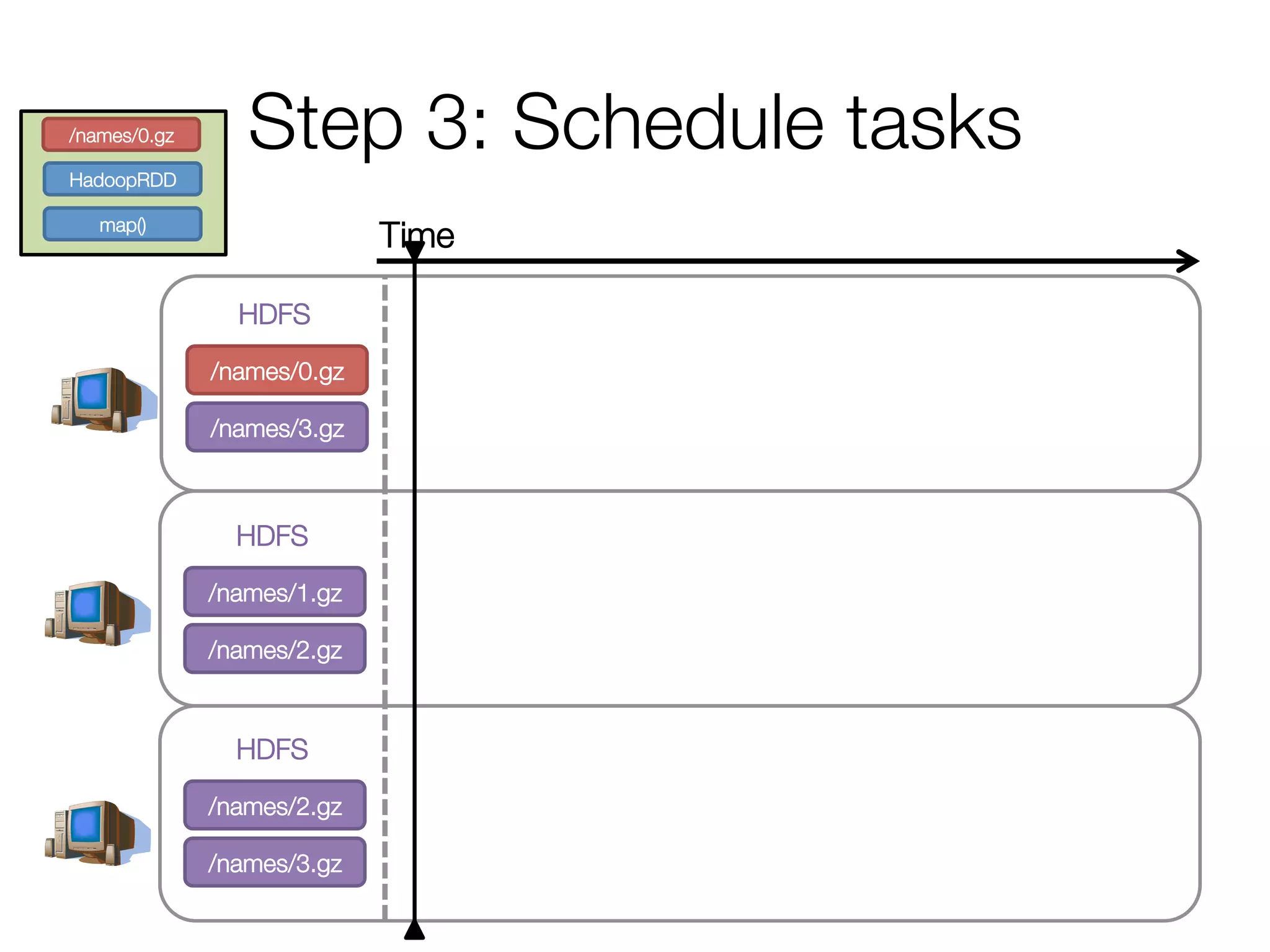
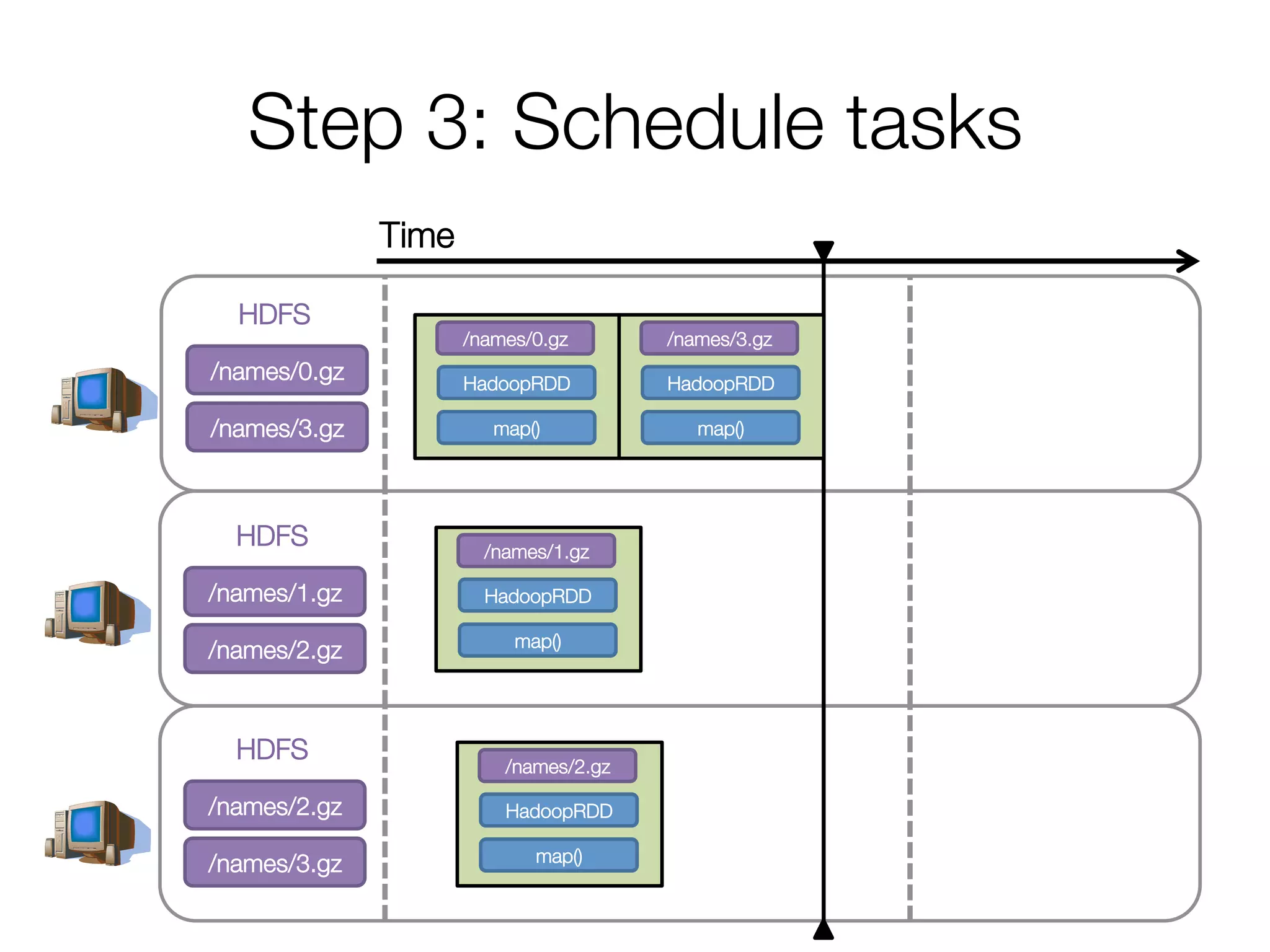
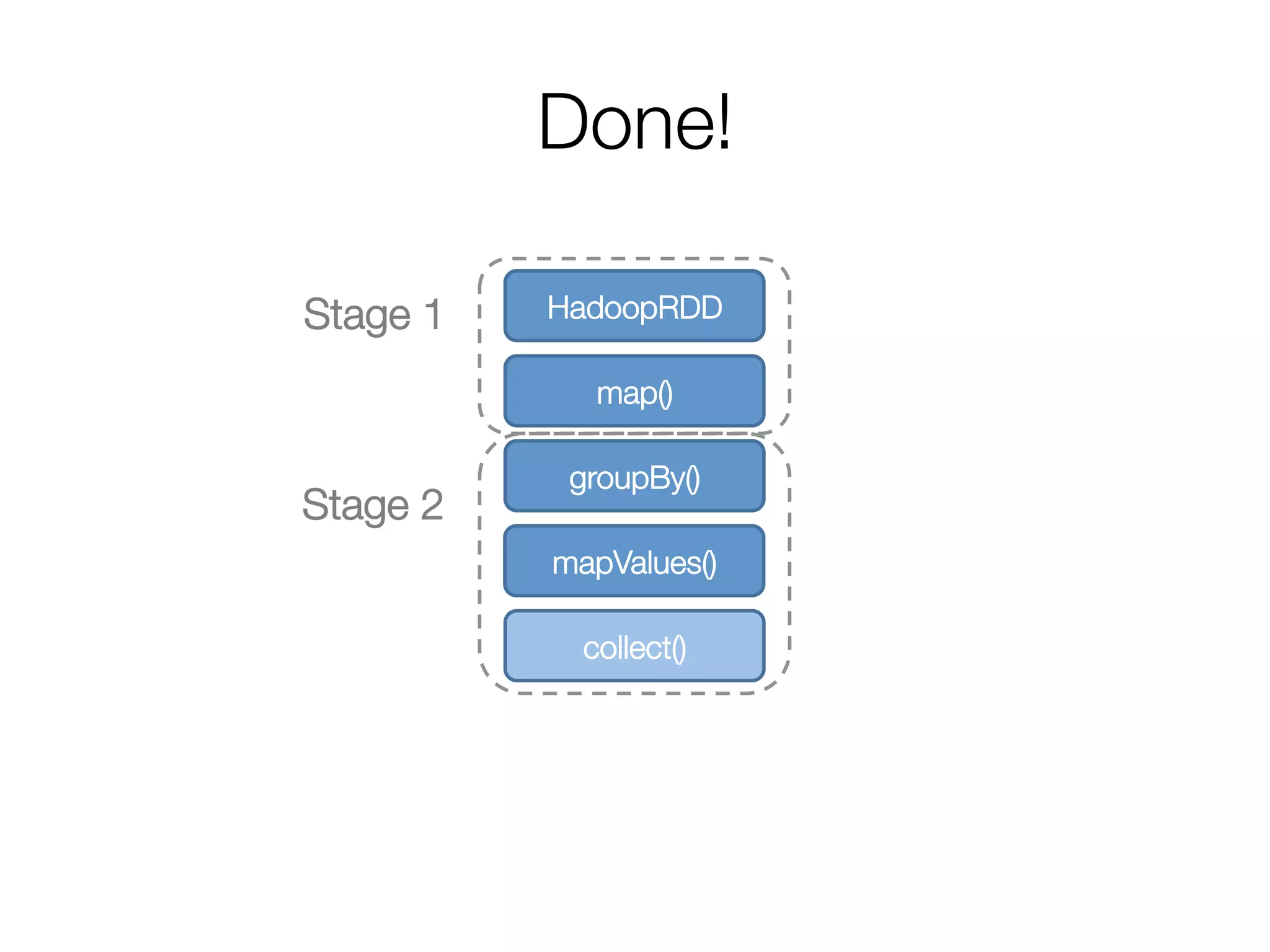
![Step 2: Create execution plan
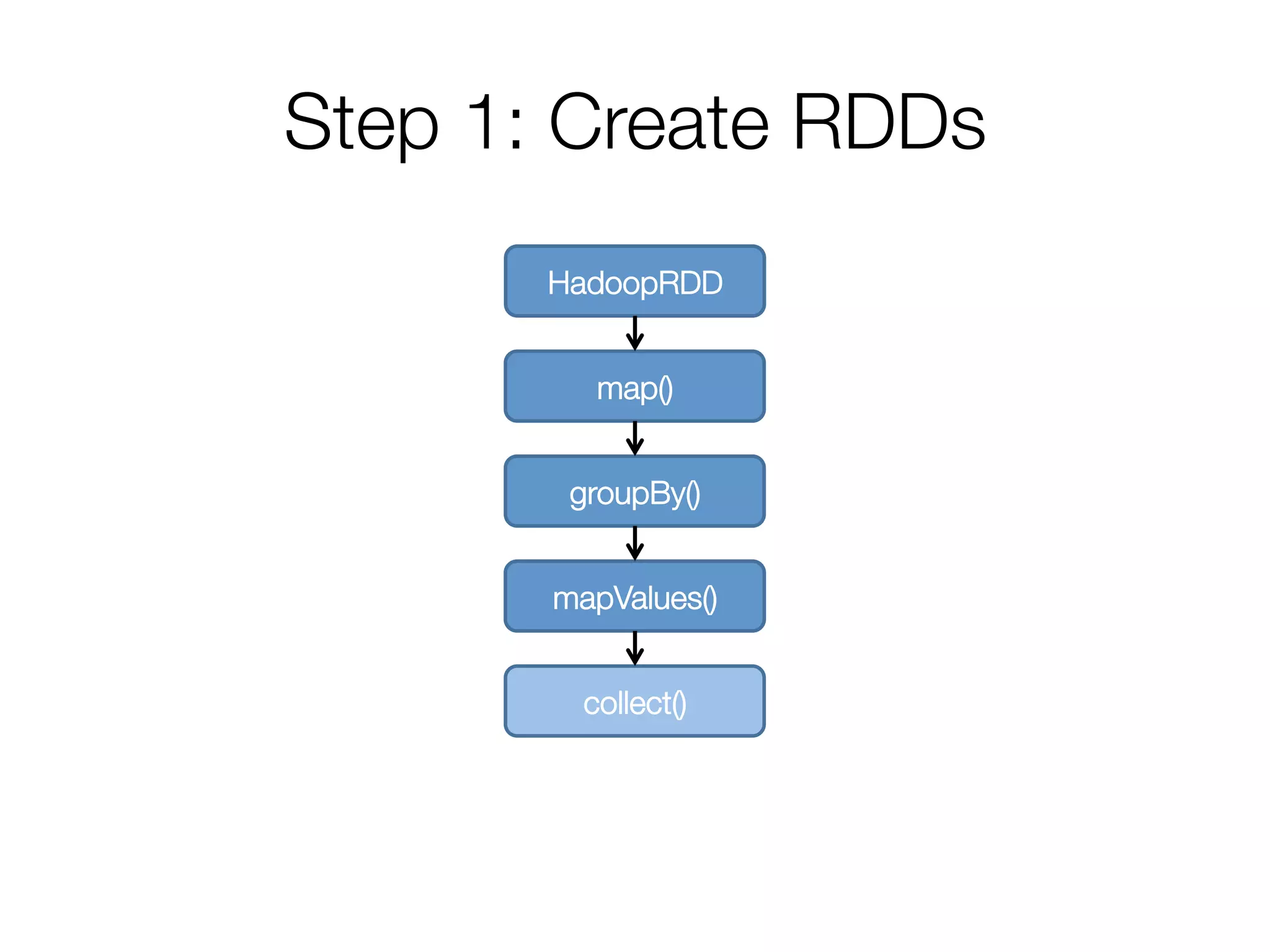
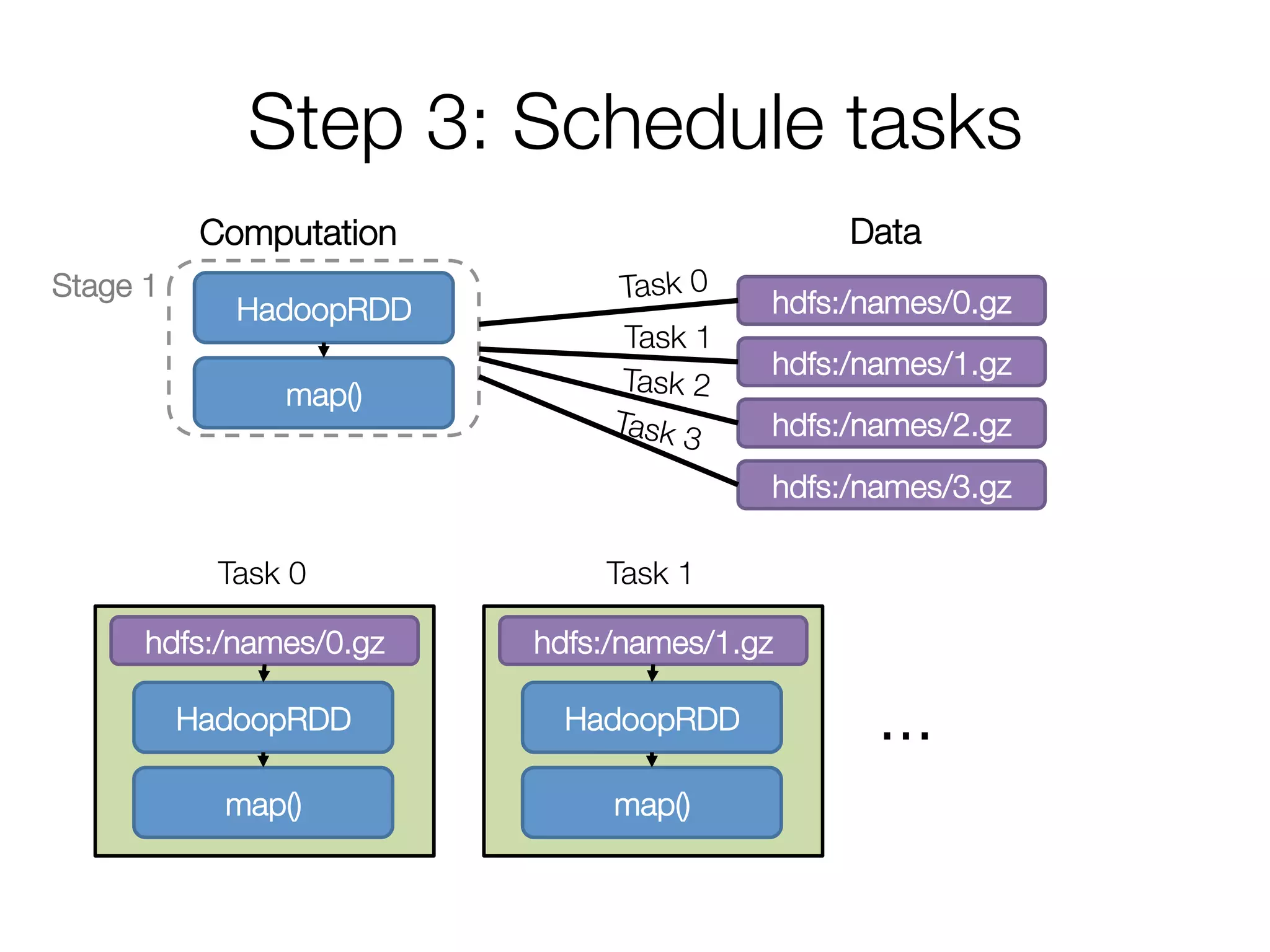
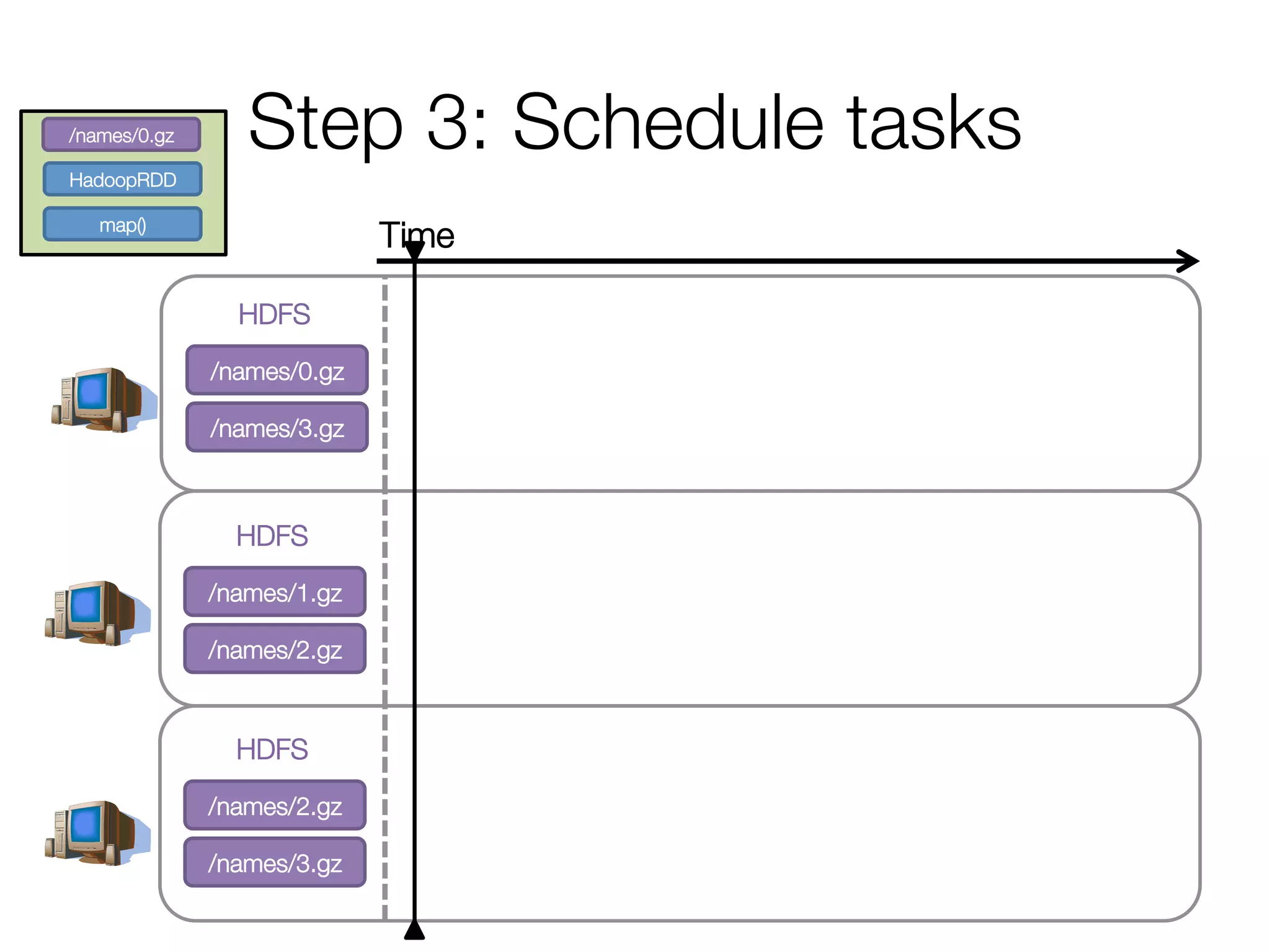
• Pipeline as much as possible
• Split into “stages” based on need to
reorganize data
Stage 1
HadoopRDD
map()
groupBy()
mapValues()
collect()
Andy
Pat
Ahir
(A, [Ahir, Andy])
(P, [Pat])
(A, 2)
(A, Andy)
(P, Pat)
(A, Ahir)
res0 = [(A, 2), ...]](https://image.slidesharecdn.com/a-deeper-understanding-of-spark-internals-aaron-davidson-150713152728-lva1-app6892/75/A-deeper-understanding-of-spark-internals-aaron-davidson-15-2048.jpg)
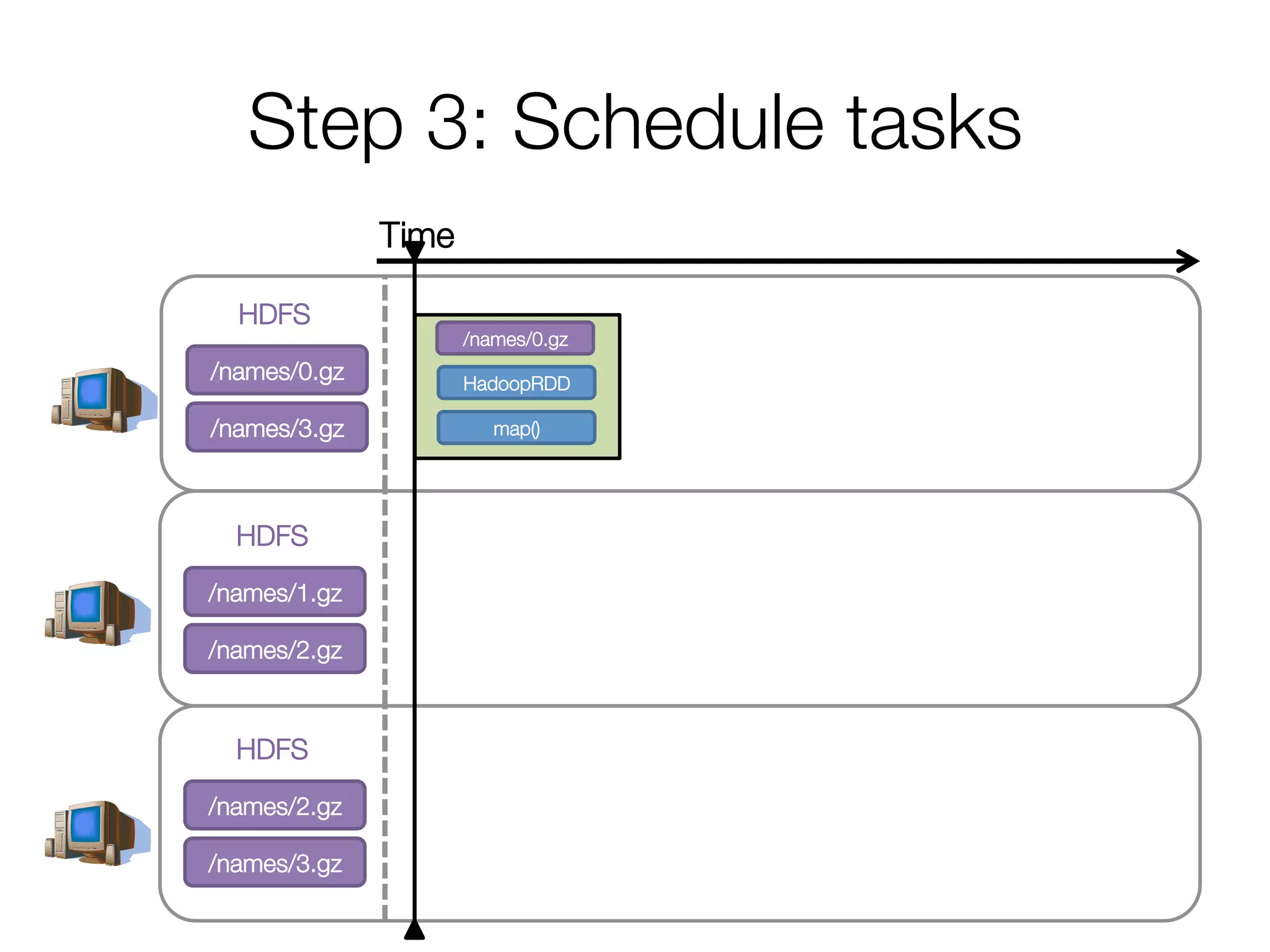
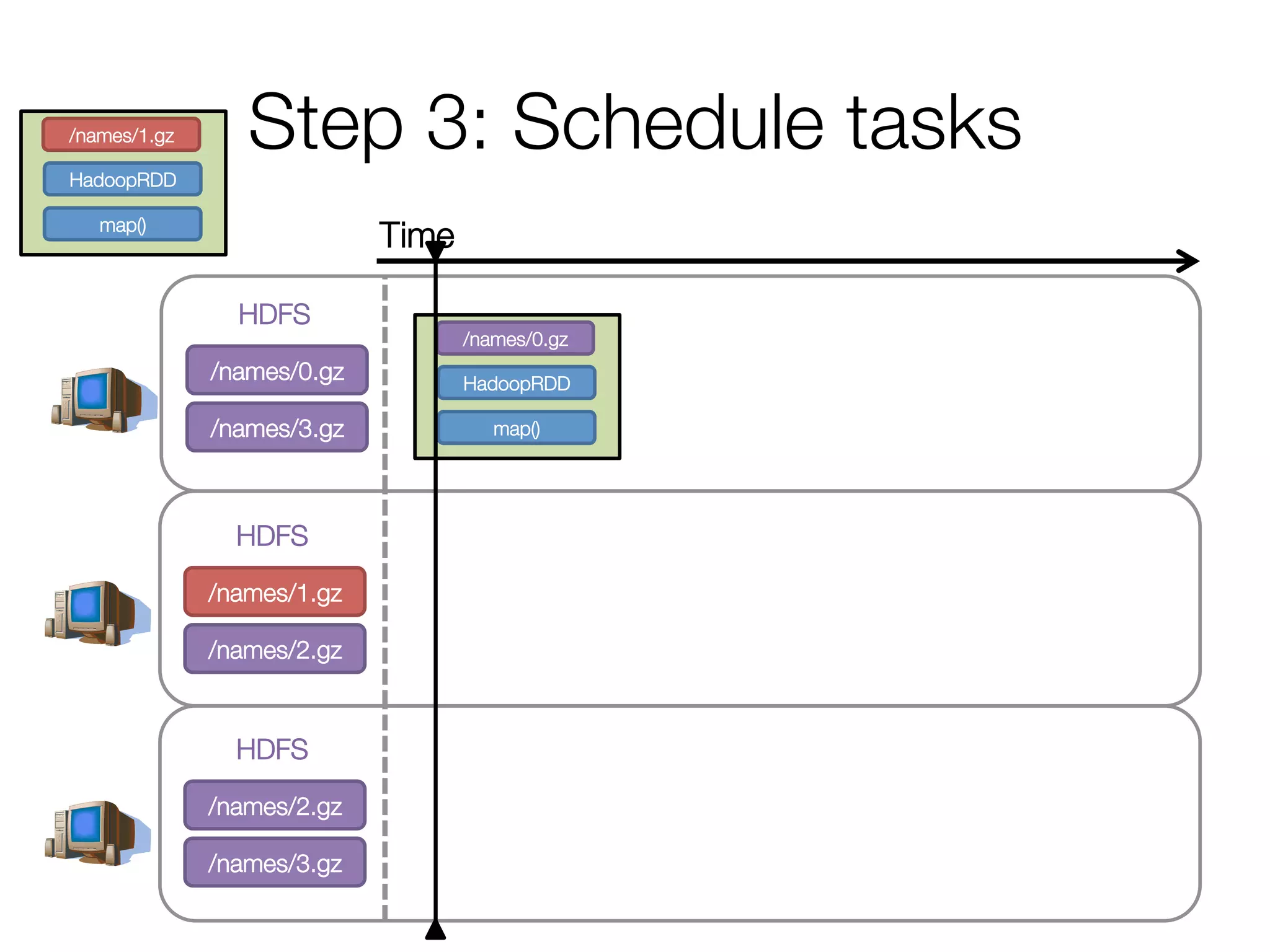
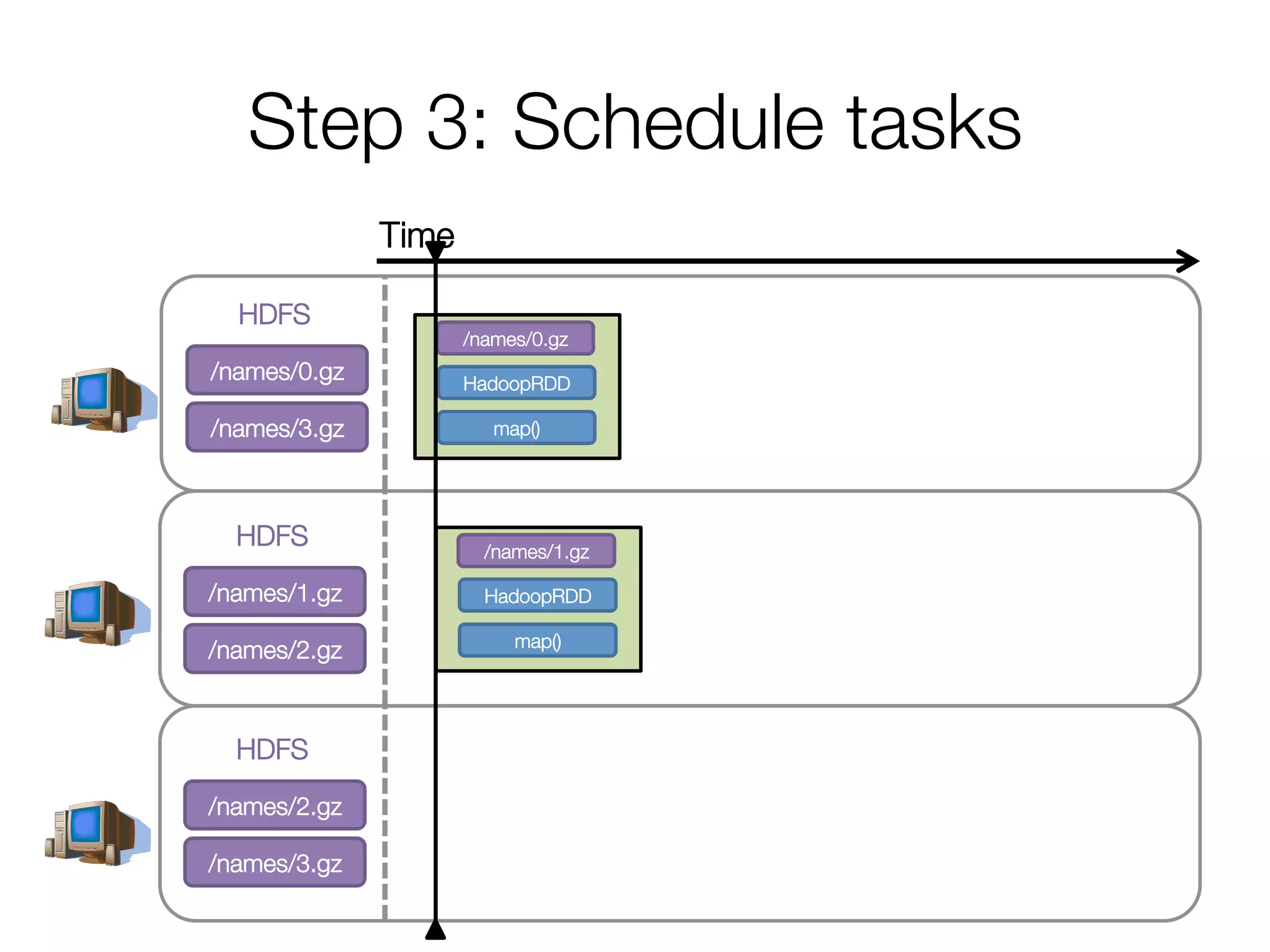
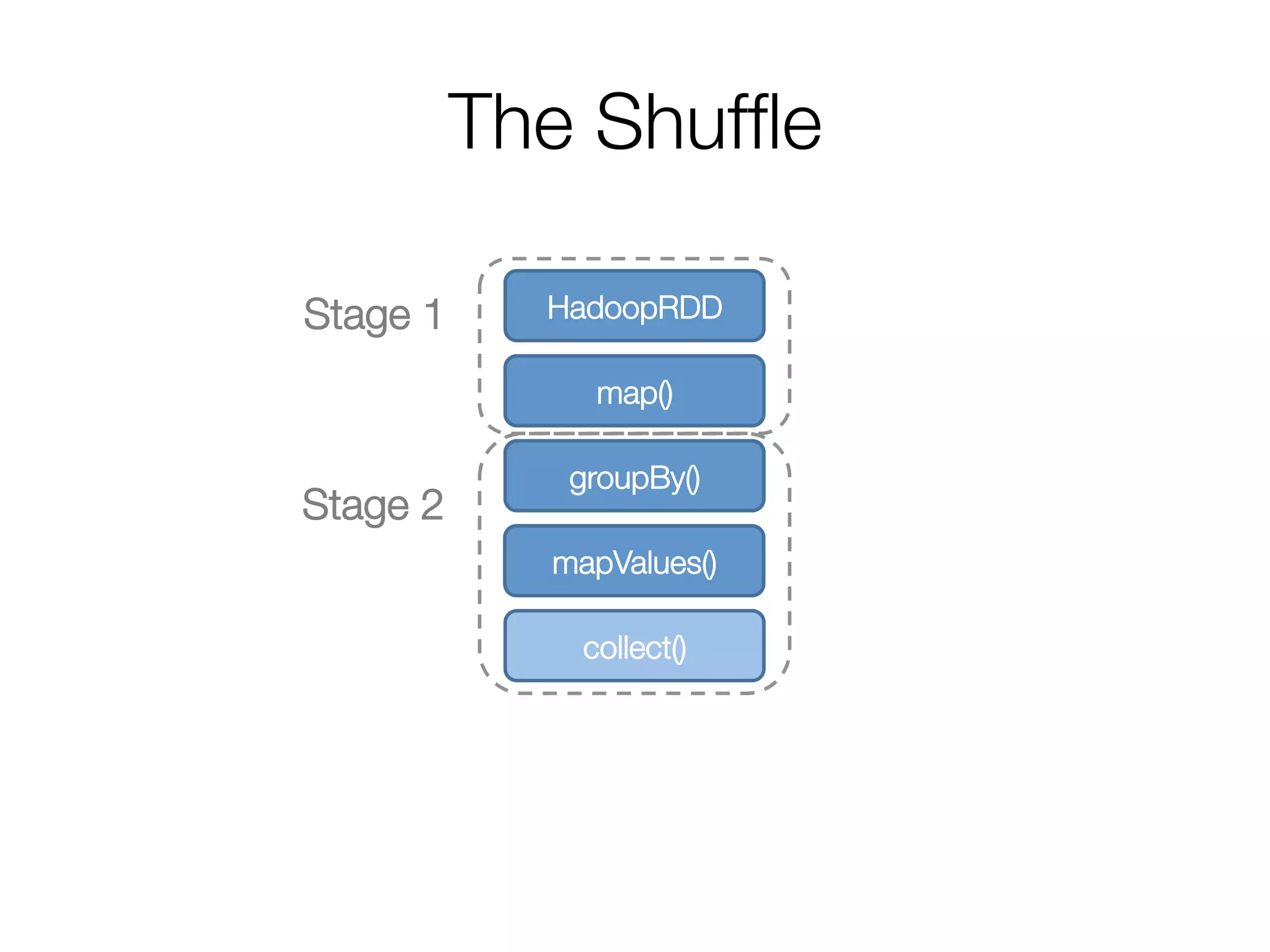
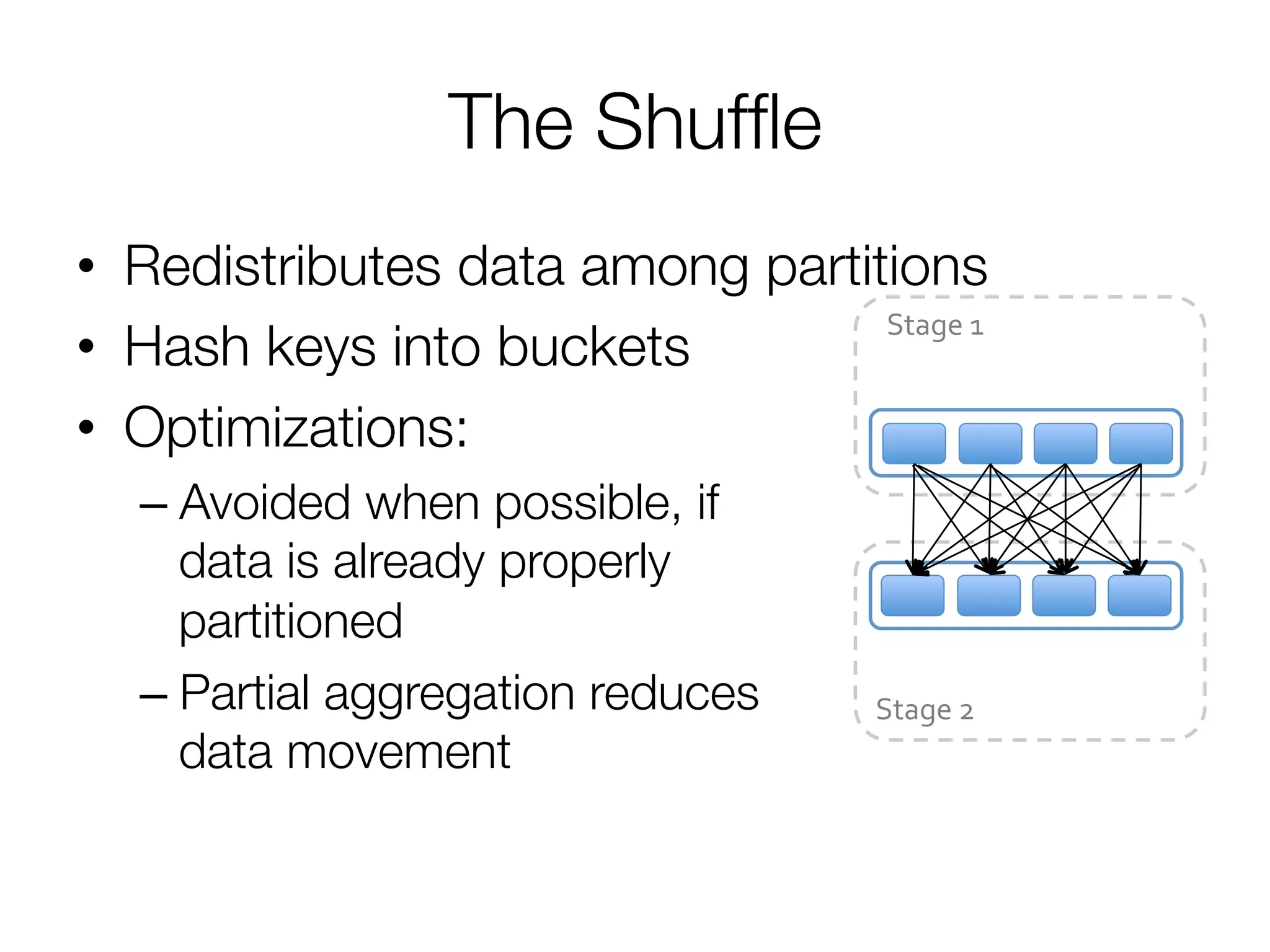
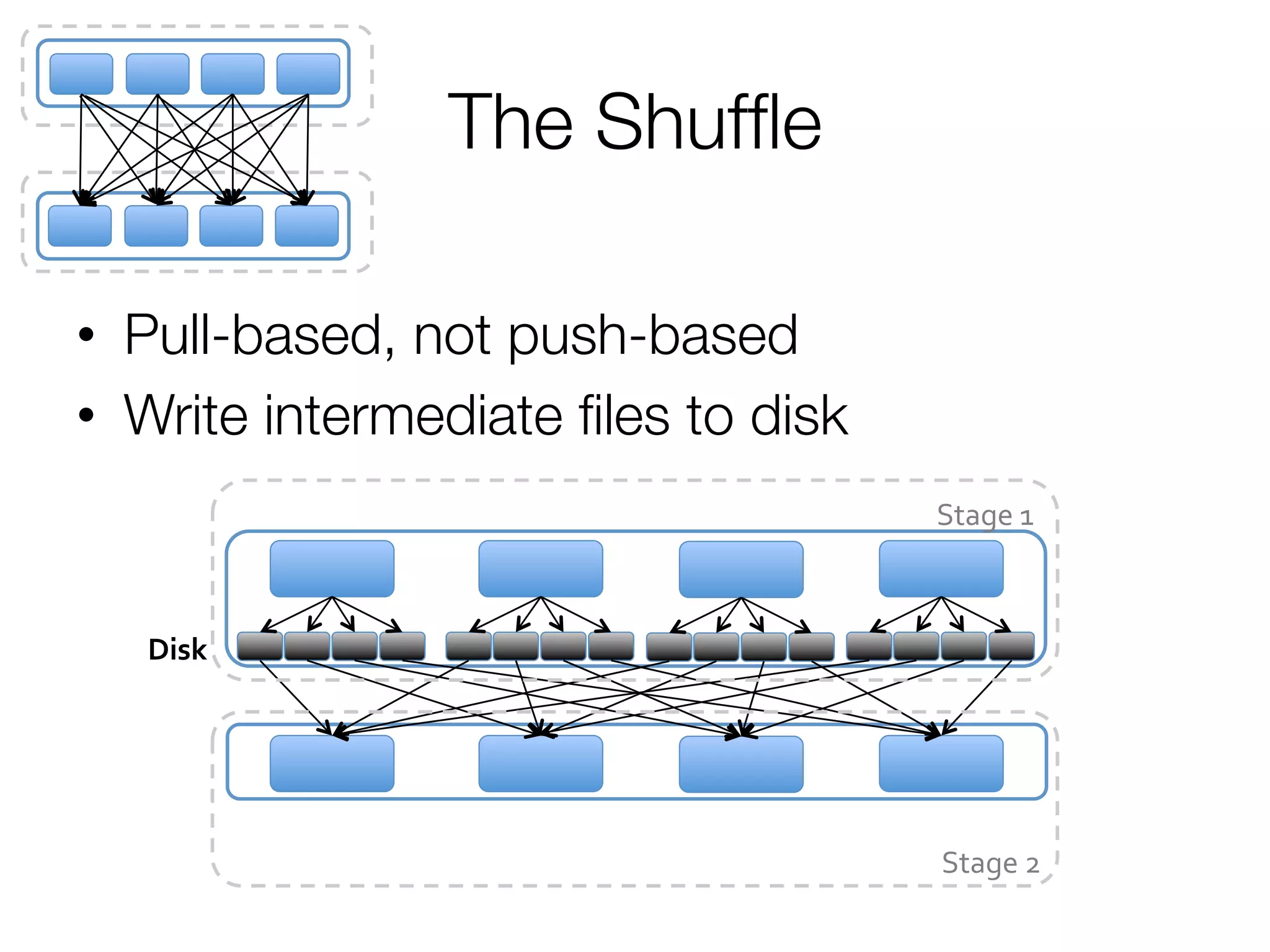
![Step 2: Create execution plan
• Pipeline as much as possible
• Split into “stages” based on need to
reorganize data
Stage 1
Stage 2
HadoopRDD
map()
groupBy()
mapValues()
collect()
Andy
Pat
Ahir
(A, [Ahir, Andy])
(P, [Pat])
(A, 2)
(P, 1)
(A, Andy)
(P, Pat)
(A, Ahir)
res0 = [(A, 2), (P, 1)]](https://image.slidesharecdn.com/a-deeper-understanding-of-spark-internals-aaron-davidson-150713152728-lva1-app6892/75/A-deeper-understanding-of-spark-internals-aaron-davidson-16-2048.jpg)

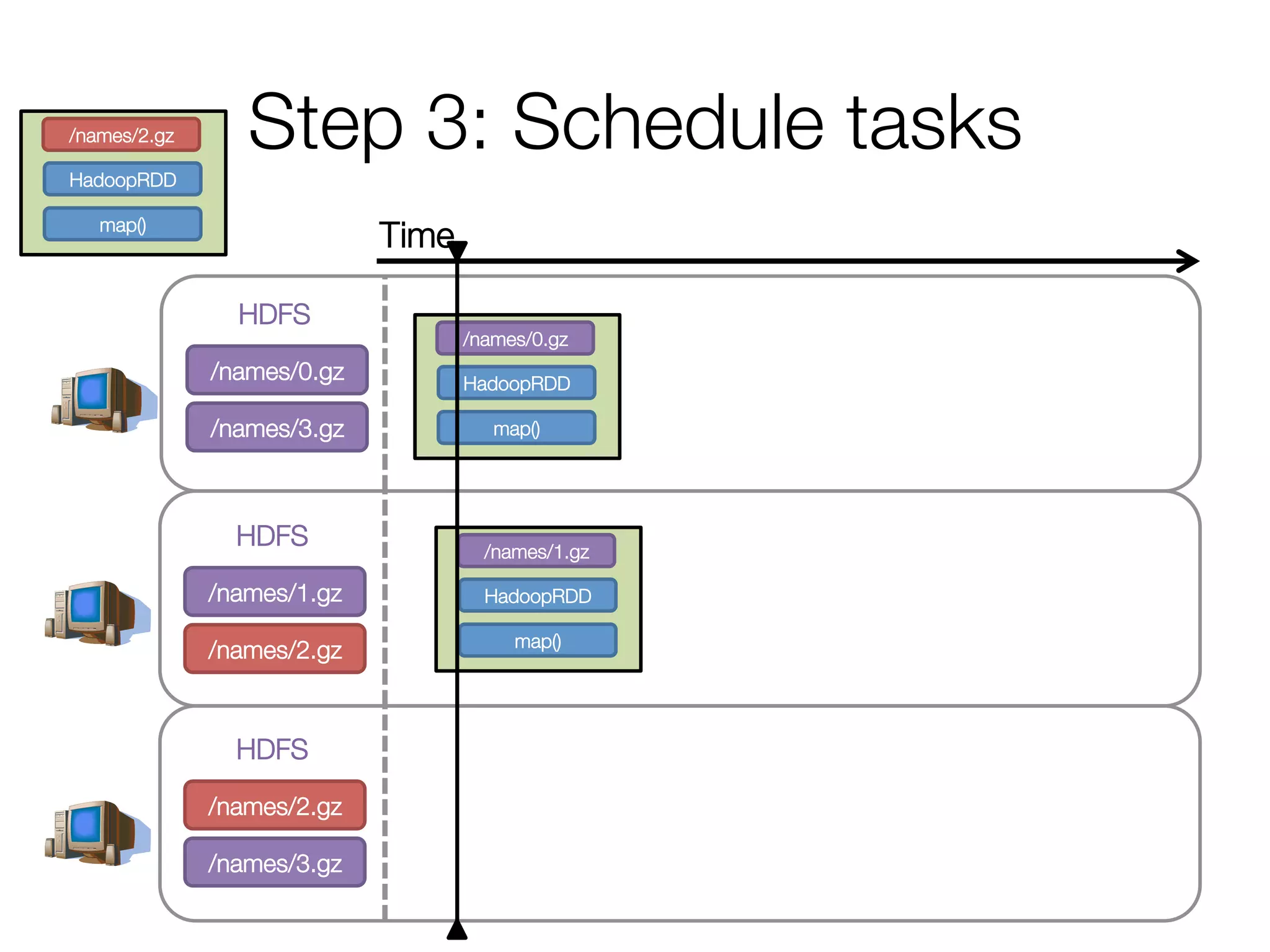
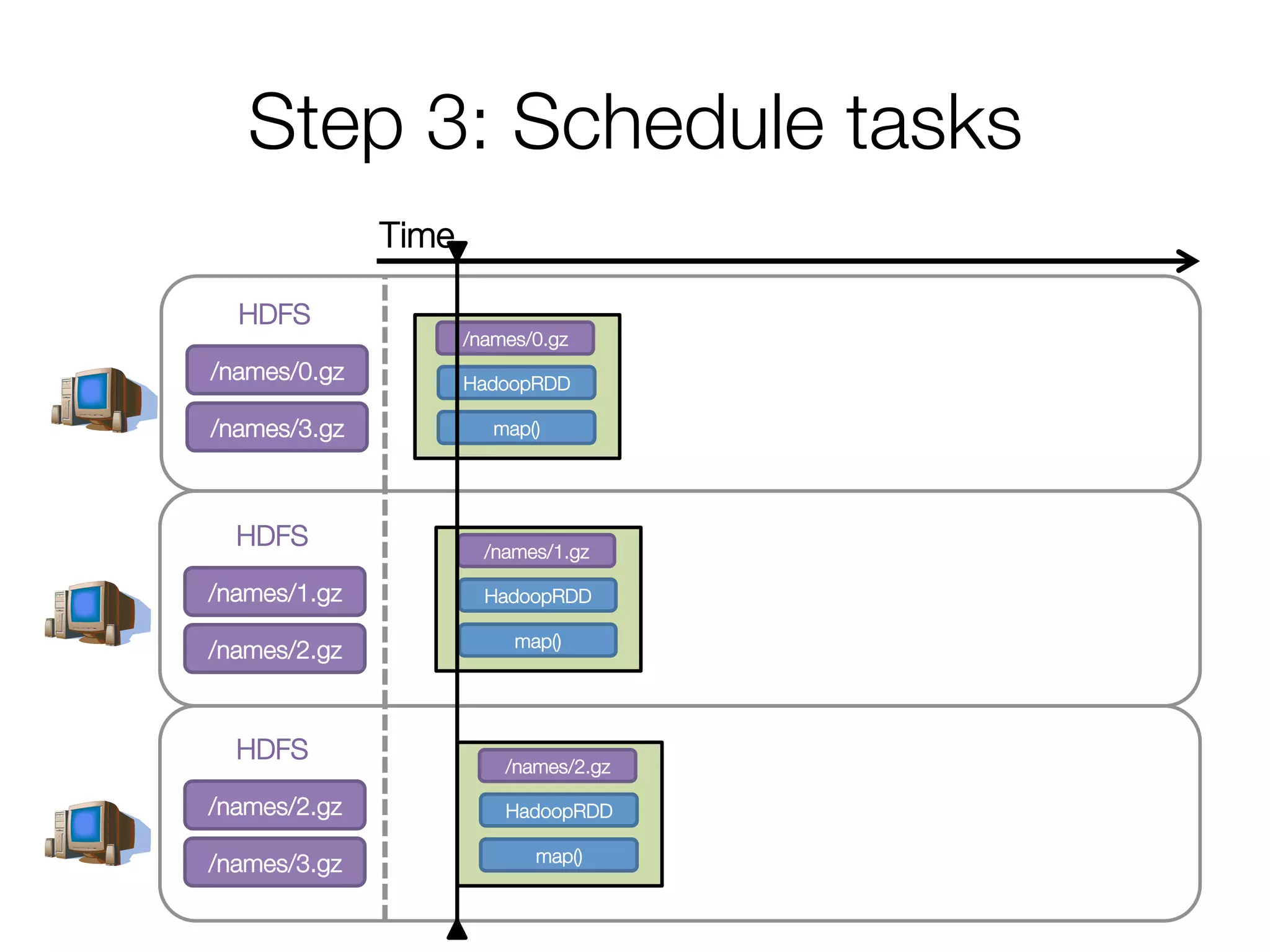
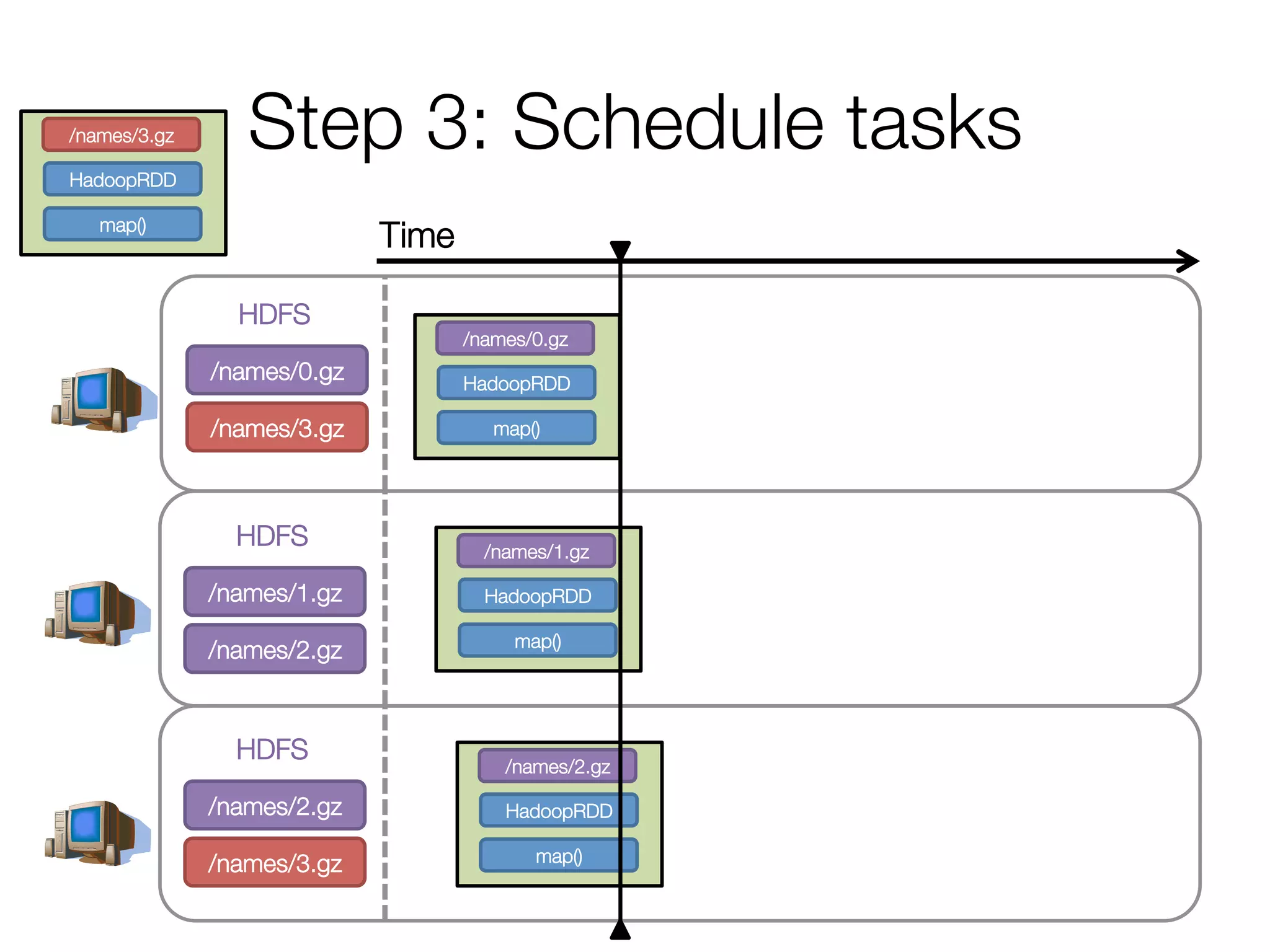
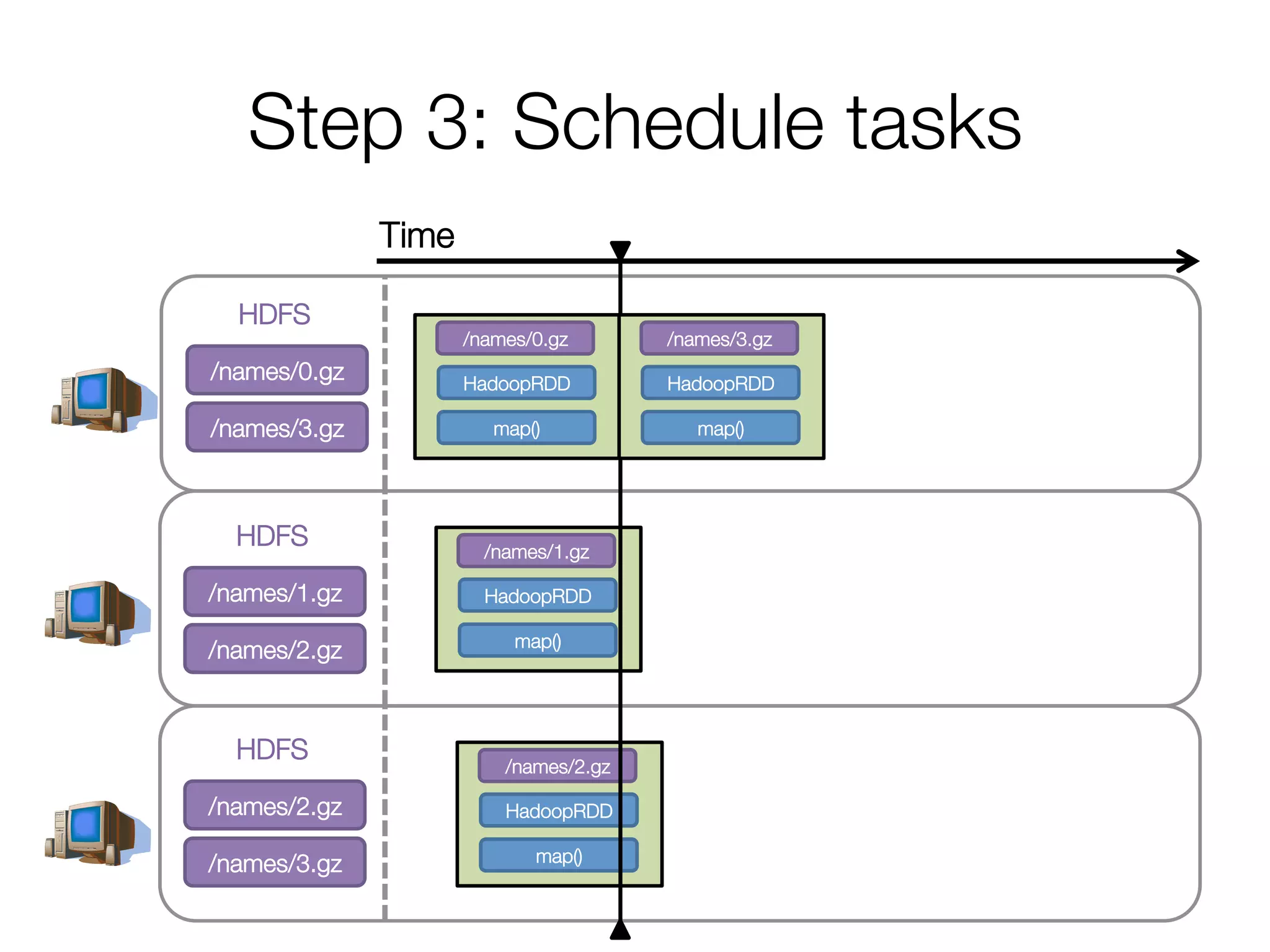
![Execution of a groupBy()
• Build hash map within each partition
• Note: Can spill across keys, but a single
key-value pair must fit in memory
A => [Arsalan, Aaron, Andrew, Andrew, Andy, Ahir, Ali, …],
E => [Erin, Earl, Ed, …]
…](https://image.slidesharecdn.com/a-deeper-understanding-of-spark-internals-aaron-davidson-150713152728-lva1-app6892/75/A-deeper-understanding-of-spark-internals-aaron-davidson-32-2048.jpg)













The document provides an overview of Spark's execution model and internals, focusing on performance. It discusses how Spark runs jobs by creating a DAG of RDDs, generating a logical execution plan, and scheduling and executing individual tasks across stages. Key components covered include the execution model, shuffling data between stages, and caching. The document uses an example job to count distinct names by first letter to demonstrate these concepts. It highlights potential performance issues like not having enough partitions and minimizing data shuffling and memory usage.




















































































