Download to read offline





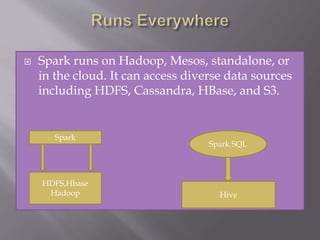






Apache Spark is an open source cluster computing framework that provides fast data processing capabilities. It can run programs up to 100x faster than Hadoop in memory or 10x faster on disk. Spark also provides high-level APIs in Java, Scala, Python and R for building parallel apps. It supports a wide range of applications including ETL, machine learning, streaming, and graph analytics through libraries like SQL, DataFrames, MLlib, GraphX, and Spark Streaming.























































































