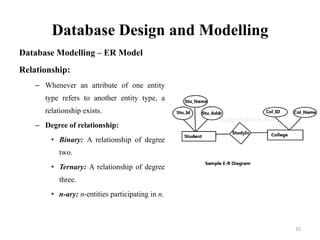
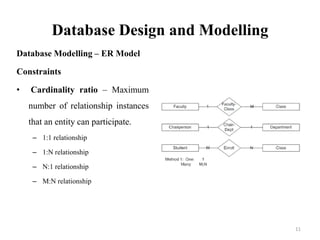
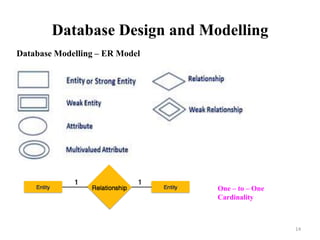
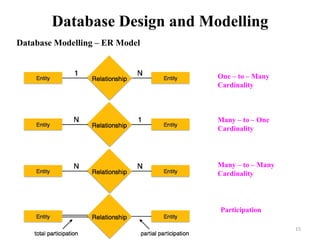
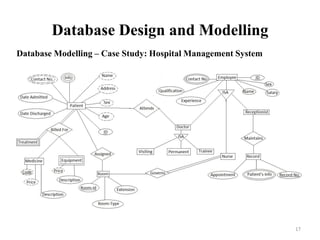
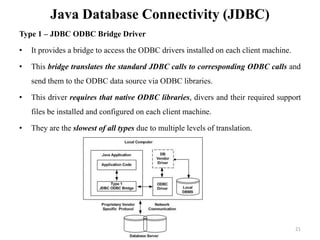
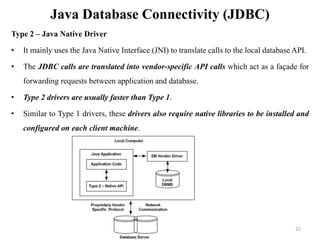
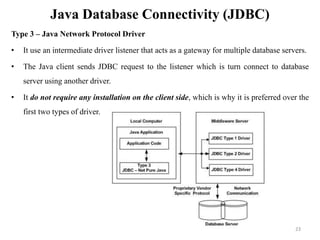
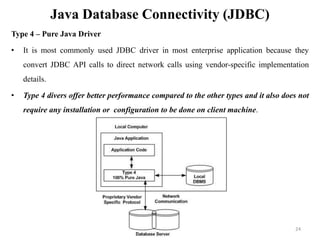
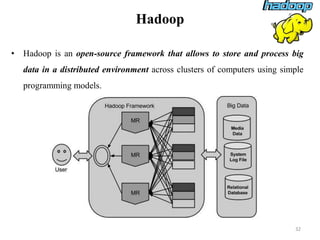
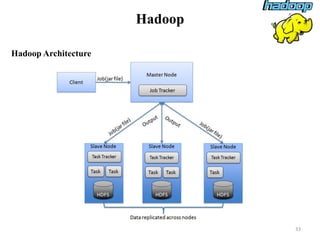
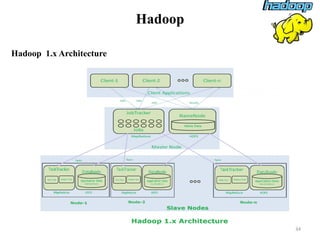
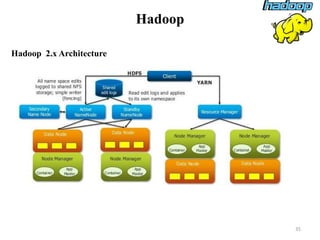
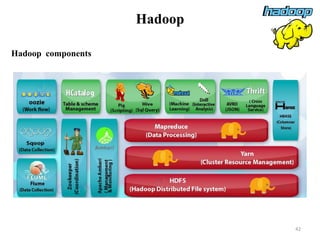
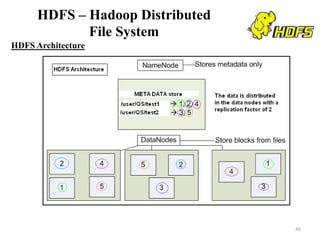
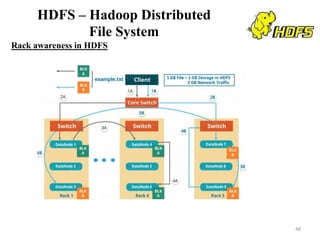
The document discusses database modeling, management, and development. It covers database design and modeling including conceptual, logical, and physical database design. It also discusses entity-relationship modeling including entities, attributes, relationships, keys, and constraints. Additionally, it covers Java database connectivity (JDBC) including the different types of JDBC drivers and how to access a database using JDBC.

















![Stored Procedure – PL/SQL
Example
Function
CREATE [OR REPLACE] FUNCTION function_name
[(parameter_name [IN | OUT | IN OUT] type [, ...])]
RETURN return_datatype
{IS | AS}
BEGIN
< function_body >
END [function_name];
Procedure
CREATE [OR REPLACE] PROCEDURE procedure_name
[(parameter_name [IN | OUT | IN OUT] type [, ...])]
{IS | AS}
BEGIN
< procedure_body >
END procedure_name;
29](https://image.slidesharecdn.com/uniti-databasemodellingmanagementanddevelopment-190812041046/85/IT6701-Information-Management-Unit-I-29-320.jpg)


















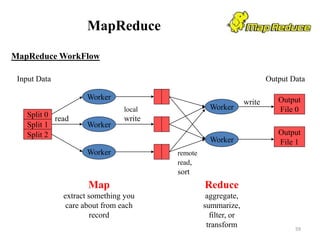
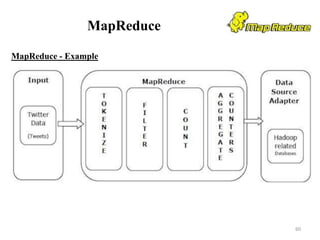
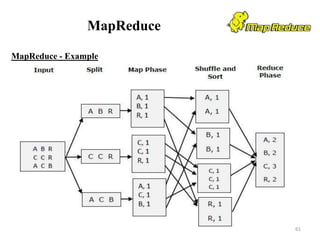
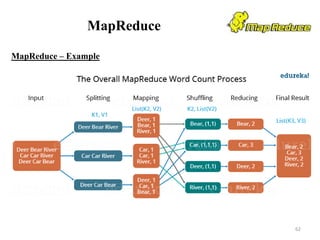



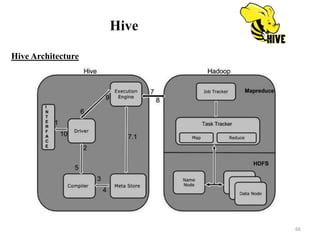

![Hive
Create Database Statement
– CREATE DATABASE [IF NOT EXISTS] <database name> ;
Drop Database Statement
– DROP DATABASE IF EXISTS <database name>;
Create Table Statement
– CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]
table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[ROW FORMAT row_format]
[STORED AS file_format]
68](https://image.slidesharecdn.com/uniti-databasemodellingmanagementanddevelopment-190812041046/85/IT6701-Information-Management-Unit-I-68-320.jpg)