Download as PDF, PPTX








![Extracting topics from text
• Topic modelling (e.g. LDA – Latent Dirichlet Allocation) allows to extract a mix (distribution) of
topics from a given text
• Unfortunately topics are not automatically labeled, we only know the most important words in
each topic
• Given the text in a social profile, compute the most important topic(s)
• Uber Technologies Inc. is an American international transportation network company headquartered in San Francisco, California.
The company develops, markets and operates the Uber mobile app, which allows consumers with smartphones to submit a trip
request which is then routed to Uber drivers who use their own cars.[1][2] By May 28, 2015, the service was available in 58
countries and 300 cities worldwide => [taxi, transportation, ]
• Connectifier is a next-gen search platform specifically targeting hiring - one of the most fundamental pieces of our economy.
Discover, qualify, and connect with exceptional job candidates twice as effectively. => [hiring, career and jobs, recruitment,
marketplace, coaching]
• Dropbox is a free service that lets you bring your photos, docs, and videos anywhere and share them easily. Dropbox was founded
in 2007 by Drew Houston and Arash Ferdowsi, two MIT students tired of emailing files to themselves to work from more than one
computer. => [cloud, collaborative documents, collaboration, file sharing, storage, photo sharing, photo editing, ]
• PeopleGraph is building a people search engine. 3 billion searches a day are for people, yet there's no way to comprehensively
search someone's online footprint. We are well on the way to solving that problem. => [search, people, ]
>> Bucharest.AI #5 << :: 05 Dec 17](https://image.slidesharecdn.com/bucharest-ai-aiwholi-171208225434/85/AI-Wholi-Bucharest-AI-Meetup-5-10-320.jpg)


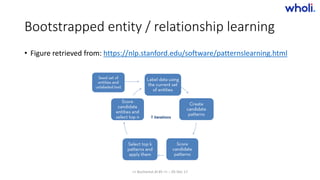
![Bootstrapped entity / relationship learning
• Seeds either initialized manually (e.g. hobbies), or from labeled data in our index (e.g. worksAt, livesIn)
• Seed hobbies:
• football, poker, martial arts, chess, swimming, jogging, hiking, fishing, archery, cooking
• Computes:
• baketball[0.0016682103969337127] baseball[0.0018129626504372067]
• dogs[0.0011119719042083742]
• drinks[1.4506528794721354E-4] beer[1.1687126552358244E-4] martini[2.4980405990967884E-4]
• husband[1.7630337419381701E-4]
• church[1.3872841379648836E-4] god[2.0515591306815217E-4]
• gadgets[2.67475711957433E-4]
• music[1.2155990349464713E-4]
• games[1.7018667163236963E-4]
• singing[1.5344948928898647E-4]
• birds[2.746465269584744E-4]
• facebook[1.5347921795982061E-4]
>> Bucharest.AI #5 << :: 05 Dec 17](https://image.slidesharecdn.com/bucharest-ai-aiwholi-171208225434/85/AI-Wholi-Bucharest-AI-Meetup-5-14-320.jpg)
![Bootstrapped entity / relationship learning
• Patterns for role:
left 1.0000 : __company__ - [support=6891]
right 0.9802 : di __company__ [support=1879]
right 0.9442 : bei __company__ __end__ [support=5043]
right 0.5559 : @ __company__ __end__ [support=343]
left 1.0000 : __start__ __role__ at __company__ and [support=90]
>> Bucharest.AI #5 << :: 05 Dec 17](https://image.slidesharecdn.com/bucharest-ai-aiwholi-171208225434/85/AI-Wholi-Bucharest-AI-Meetup-5-15-320.jpg)








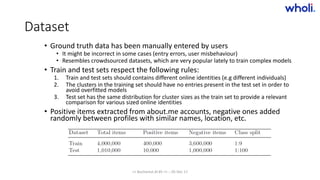





![Results – examples
• Ground truth
• ['twitter/etniqminerals', 'instagram/etniqminerals', 'googleplus/106318957043871071183', 'facebook/etniqminerals',
'facebook/rockcityelitesalsa', 'facebook/1renaissancewoman', 'facebook/naturalblackgirlguide', 'linkedin/leahpatterson’]
• Computed
• [ 'facebook/1renaissancewoman’, 'linkedin/leahpatterson’, 'googleplus/106318957043871071183’]
• ['twitter/etniqminerals', 'instagram/etniqminerals', 'facebook/etniqminerals']
• [ 'facebook/naturalblackgirlguide']
• “Leah Patterson” is an individual who has two different companies “Etniq Minerals” and “Natural Black
Girl Guide”
• Ground truth
• 3 different individuals whose first name is “Tim” and all of them work in IT
• Computed
• ['googleplus/113375270405699485276', 'linkedin/timsmith78', 'googleplus/117829094399867770981',
'twitter/bbyxinnocenz', 'facebook/tim.tio.5', 'vimeo/user616297', 'linkedin/timtio', 'twitter/wbcsaint', 'twitter/turnitontim']
>> Bucharest.AI #5 << :: 05 Dec 17](https://image.slidesharecdn.com/bucharest-ai-aiwholi-171208225434/85/AI-Wholi-Bucharest-AI-Meetup-5-32-320.jpg)



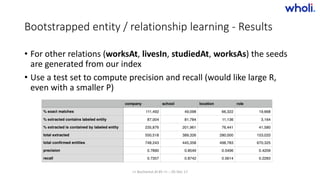


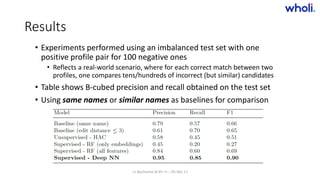
Wholi is a company that aggregates data from public online sources to build knowledge graphs about people and companies. They use machine learning and natural language processing techniques like named entity recognition and topic modeling to extract useful features from text data. They also employ bootstrapped entity and relationship learning to infer additional information. Wholi matches profiles using a deep learning classifier trained on a large dataset of over 500,000 social media profiles to determine which profiles belong to the same individuals. Their goal is to provide a more complete online identity for matching purposes.















































































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)






![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)
