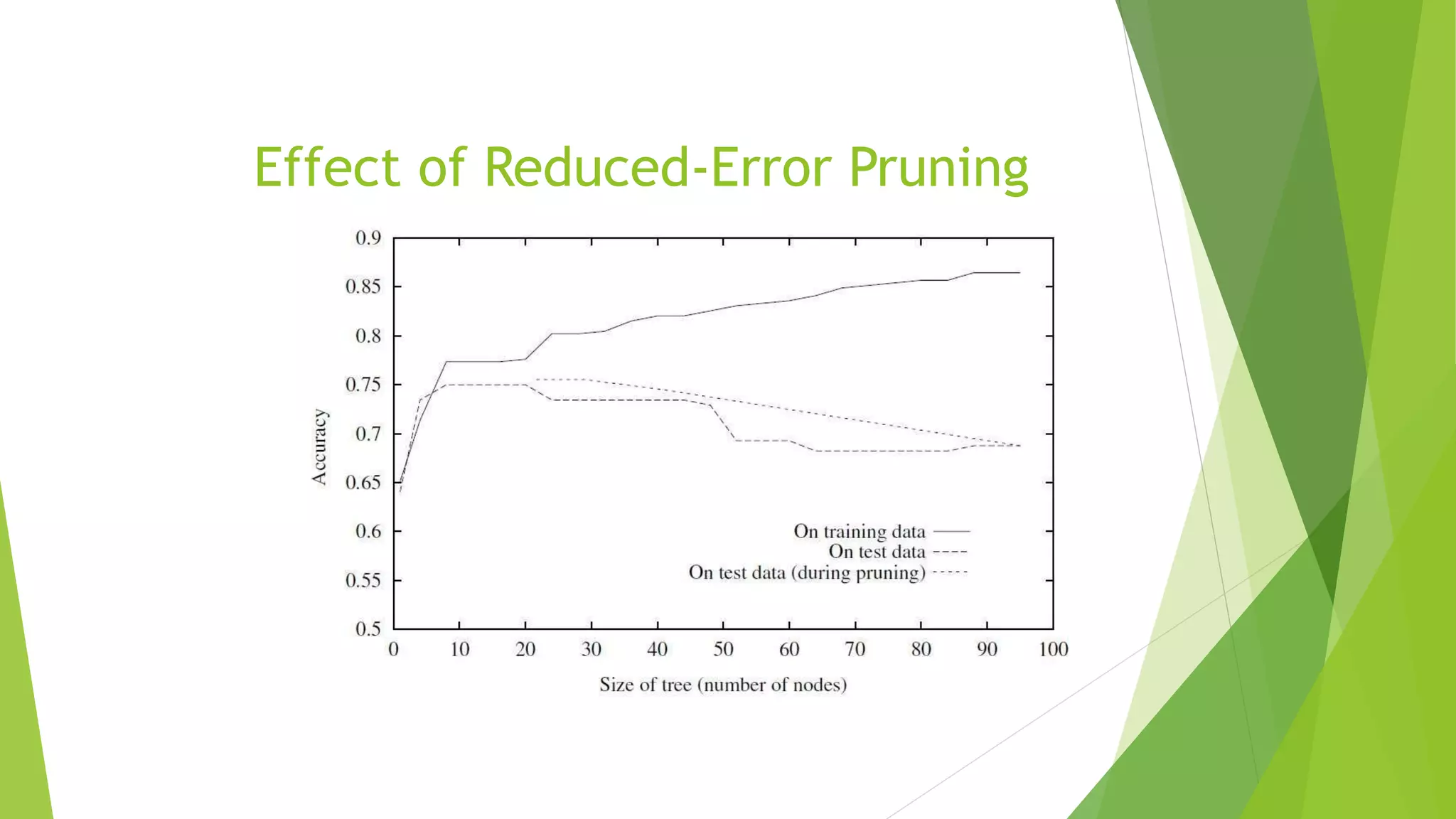
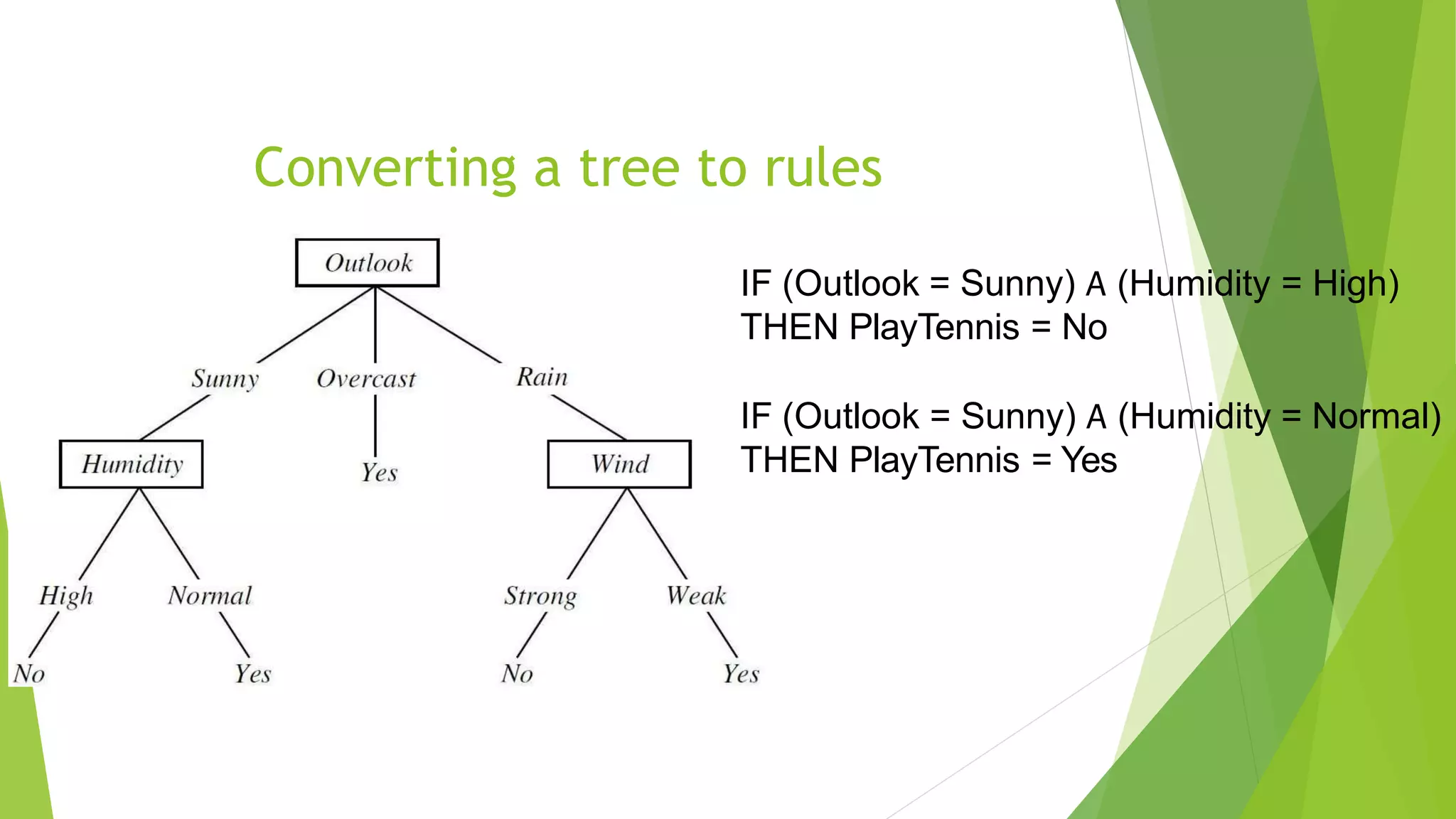
The document discusses various issues in decision tree learning, including overfitting, handling continuous-valued attributes, and managing missing attribute values. It outlines methods to avoid overfitting, such as pruning and selecting the best tree through validation, along with an explanation of reduced-error pruning. Additionally, it addresses the challenges posed by attributes with many values and associated costs, providing solutions for these issues.









![Attributes with costs
• Problem:
• Medical diagnosis, BloodTest has cost $150
• Robotics, Width_from_1ft has cost 23 sec
• One Approach - replace gain
• Tan and Schlimmer (1990)
• Nunez (1988)
• where w ∈ [0, 1] is a constant that determines the relative importance of cost versus information
gain.](https://image.slidesharecdn.com/presentationdecisiontreesmilind-150204024306-conversion-gate01-210726171841/75/Issues-in-Decision-Tree-by-Ravindra-Singh-Kushwaha-B-Tech-IT-2017-21-Chaudhary-Charan-Singh-University-Meerut-12-2048.jpg)






































































