3
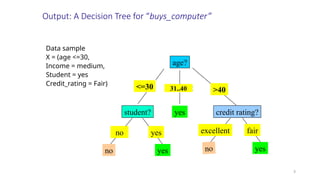
Output: A DecisionTree for “buys_computer”
age?
overcast
student? credit rating?
<=30 >40
no yes yes
yes
31..40
no
fair
excellent
yes
no
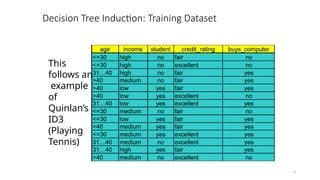
Data sample
X = (age <=30,
Income = medium,
Student = yes
Credit_rating = Fair)
5
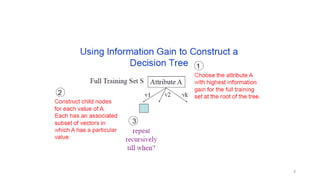
Algorithm for DecisionTree Induction
• Basic algorithm (a greedy algorithm)
• Tree is constructed in a top-down recursive divide-and-conquer manner
• At start, all the training examples are at the root
• Attributes are categorical (if continuous-valued, they are discretized in
advance)
• Examples are partitioned recursively based on selected attributes
• Test attributes are selected on the basis of a heuristic or statistical
measure (e.g., information gain)
• Conditions for stopping partitioning
• All samples for a given node belong to the same class
• There are no samples left
6.
6
Constructing decision trees
•Strategy: top down learning using recursive divide-and-
conquer process
• First: select attribute for root node
Create branch for each possible attribute value
• Then: split instances into subsets
One for each branch extending from the node
• Finally: repeat recursively for each branch, using only instances that
reach the branch
• Stop if all instances have the same class
11
Criterion for attributeselection
• Which is the best attribute?
• Want to get the smallest tree
• Heuristic: choose the attribute that produces the “purest” nodes
• Popular selection criterion: information gain
• Information gain increases with the average purity of the subsets
• Strategy: amongst attributes available for splitting, choose
attribute that gives greatest information gain
• Information gain requires measure of impurity
• Impurity measure that it uses is the entropy of the class
distribution, which is a measure from information theory
12.
12
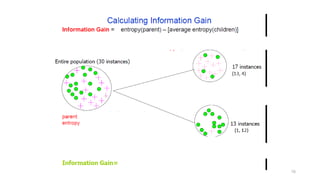
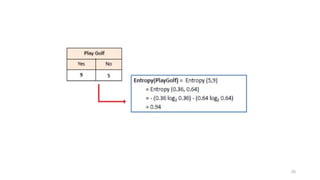
Computing information
• Wehave a probability distribution: the class distribution in a subset
of instances
• The expected information required to determine an outcome (i.e.,
class value), is the distribution’s entropy
• Formula for computing the entropy:
• Using base-2 logarithms, entropy gives the information required in
expected bits
• Entropy is maximal when all classes are equally likely and minimal
when one of the classes has probability 1
13.
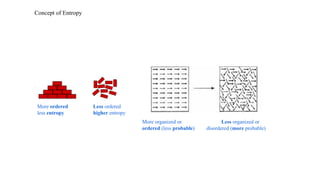
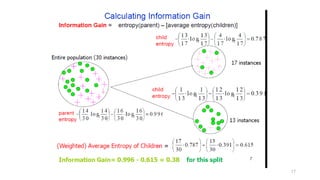
More ordered Lessordered
less entropy higher entropy
More organized or Less organized or
ordered (less probable) disordered (more probable)
Concept of Entropy
14.
14
Attribute Selection Measure:
InformationGain (ID3/C4.5)
Select the attribute with the highest information gain
Let pi be the probability that an arbitrary tuple in D
belongs to class Ci, estimated by |Ci, D|/|D|
Expected information (entropy) needed to classify a
tuple in D:
Information needed (after using A to split D into v
partitions) to classify D:
Information gained by branching on attribute A
)
(
log
)
( 2
1
i
m
i
i p
p
D
Info
)
(
|
|
|
|
)
(
1
j
v
j
j
A D
I
D
D
D
Info
(D)
Info
Info(D)
Gain(A) A
15.
Information Gain
15
• InformationGain
• We want to determine which attribute in a given set of training
feature vectors is most useful for discriminating between the classes
to be learned.
• Information gain tells us how important a given attribute of the
feature vectors is.
• We will use it to decide the ordering of attributes in the nodes of a
decision tree
21
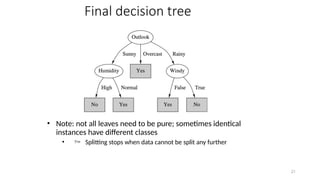
Final decision tree
•Note: not all leaves need to be pure; sometimes identical
instances have different classes
• Splitting stops when data cannot be split any further
22.
22
Attribute Selection: InformationGain
g Class P: buys_computer = “yes”
g Class N: buys_computer = “no”
means “age <=30” has 5 out of 14
samples, with 2 yes’es and 3 no’s.
Hence
Similarly,
age pi ni I(pi, ni)
<=30 2 3 0.971
31…40 4 0 0
>40 3 2 0.971
694
.
0
)
2
,
3
(
14
5
)
0
,
4
(
14
4
)
3
,
2
(
14
5
)
(
I
I
I
D
Infoage
048
.
0
)
_
(
151
.
0
)
(
029
.
0
)
(
rating
credit
Gain
student
Gain
income
Gain
246
.
0
)
(
)
(
)
(
D
Info
D
Info
age
Gain age
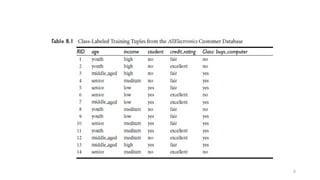
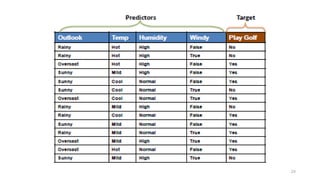
age income student credit_rating buys_computer
<=30 high no fair no
<=30 high no excellent no
31…40 high no fair yes
>40 medium no fair yes
>40 low yes fair yes
>40 low yes excellent no
31…40 low yes excellent yes
<=30 medium no fair no
<=30 low yes fair yes
>40 medium yes fair yes
<=30 medium yes excellent yes
31…40 medium no excellent yes
31…40 high yes fair yes
>40 medium no excellent no
)
3
,
2
(
14
5
I
940
.
0
)
14
5
(
log
14
5
)
14
9
(
log
14
9
)
5
,
9
(
)
( 2
2
I
D
Info
23.
23
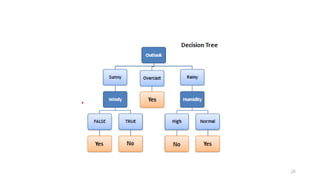
age?
student? credit rating?
<=30>40
no yes yes
yes
31..40
no
fair
excellent
yes
no
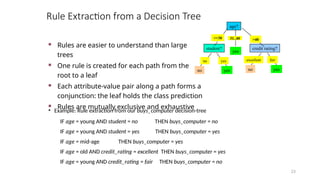
• Example: Rule extraction from our buys_computer decision-tree
IF age = young AND student = no THEN buys_computer = no
IF age = young AND student = yes THEN buys_computer = yes
IF age = mid-age THEN buys_computer = yes
IF age = old AND credit_rating = excellent THEN buys_computer = yes
IF age = young AND credit_rating = fair THEN buys_computer = no
Rule Extraction from a Decision Tree
Rules are easier to understand than large
trees
One rule is created for each path from the
root to a leaf
Each attribute-value pair along a path forms a
conjunction: the leaf holds the class prediction
Rules are mutually exclusive and exhaustive
Decision Tree
• Conceptof Decision Tree
• Use of Decision Tree to classify data
• Basic algorithm to build Decision Tree
• Some illustrations
• Concept of Entropy
• Basic concept of entropy in information theory
• Mathematical formulation of entropy
• Calculation of entropy of a training set
• Decision Tree induction algorithms
• ID3
• CART
• C4.5
34
35.
Basic Concept
• ADecision Tree is an important data structure known to solve many
computational problems
Example : Binary Decision Tree
35
A B C f
0 0 0 m0
0 0 1 m1
0 1 0 m2
0 1 1 m3
1 0 0 m4
1 0 1 m5
1 1 0 m6
1 1 1 m7
36.
Basic Concept
• Inprevious Example, we have considered a decision tree where values of any
attribute if binary only. Decision tree is also possible where attributes are of
continuous data type
Example: Decision Tree with numeric data
36
37.
Some Characteristics
• Decisiontree may be n-ary, n ≥ 2.
• There is a special node called root node.
• All nodes drawn with circle (ellipse) are called internal nodes.
• All nodes drawn with rectangle boxes are called terminal nodes or leaf nodes.
• Edges of a node represent the outcome for a value of the node.
• In a path, a node with same label is never repeated.
• Decision tree is not unique, as different ordering of internal nodes can give 37
38.
Decision Tree andClassification Task
• Decision tree helps us to classify data.
• Internal nodes are some attribute
• Edges are the values of attributes
• External nodes are the outcome of classification
• Such a classification is, in fact, made by posing questions starting from the
root node to each terminal node.
38
39.
Building Decision Tree
•In principle, there are exponentially many decision tree that can be
constructed from a given database (also called training data).
• Some of the tree may not be optimum
• Some of them may give inaccurate result
• Two approaches are known
• Greedy strategy
• A top-down recursive divide-and-conquer
• Modification of greedy strategy
• ID3
• C4.5
• CART, etc.
39
40.
Node Splitting
• DTalgorithm must provides a method for expressing an attribute test condition
and corresponding outcome for different attribute type
• Case: Binary attribute
• This is the simplest case of node splitting
• The test condition for a binary attribute generates only two outcomes
40
41.
Node Splitting inDT Algorithm
• Case: Nominal attribute
• Since a nominal attribute can have many values, its test condition can be expressed
in two ways:
• A multi-way split
• A binary split
• Muti-way split: Outcome depends on the number of distinct values for the
corresponding attribute
• Binary splitting by grouping attribute values
41
42.
Node Splitting inDT Algorithm
• Case: Ordinal attribute
• It also can be expressed in two ways:
• A multi-way split
• A binary split
• Muti-way split: It is same as in the case of nominal attribute
• Binary splitting attribute values should be grouped maintaining the order property
of the attribute values
42
43.
Node Splitting inDT Algorithm
• Case: Numerical attribute
• For numeric attribute (with discrete or continuous values), a test condition can be
expressed as a comparison set
• Binary outcome: A > v or A ≤ v
• In this case, decision tree induction must consider all possible split positions
• Range query : vi ≤ A < vi+1 for i = 1, 2, …, q (if q number of ranges are chosen)
• Here, q should be decided a priori
• For a numeric attribute, decision tree induction is a combinatorial optimization
43
44.
Illustration : DTAlgorithm
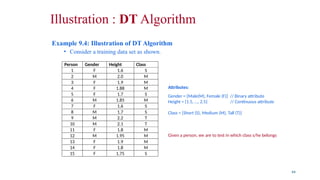
Example 9.4: Illustration of DT Algorithm
• Consider a training data set as shown.
44
Person Gender Height Class
1 F 1.6 S
2 M 2.0 M
3 F 1.9 M
4 F 1.88 M
5 F 1.7 S
6 M 1.85 M
7 F 1.6 S
8 M 1.7 S
9 M 2.2 T
10 M 2.1 T
11 F 1.8 M
12 M 1.95 M
13 F 1.9 M
14 F 1.8 M
15 F 1.75 S
Attributes:
Gender = {Male(M), Female (F)} // Binary attribute
Height = {1.5, …, 2.5} // Continuous attribute
Class = {Short (S), Medium (M), Tall (T)}
Given a person, we are to test in which class s/he belongs
45.
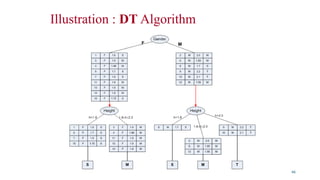
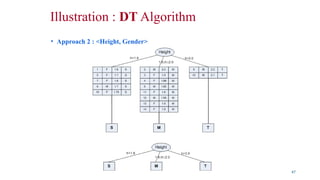
Illustration : DTAlgorithm
• To built a decision tree, we can select an attribute in two different orderings:
<Gender, Height> or <Height, Gender>
• Further, for each ordering, we can choose different ways of splitting
• Different instances are shown in the following.
• Approach 1 : <Gender, Height>
45
Illustration : DTAlgorithm
Example 9.5: Illustration of DT Algorithm
• Consider an anonymous database as shown.
48
A1 A2 A3 A4 Class
a11 a21 a31 a41 C1
a12 a21 a31 a42 C1
a11 a21 a31 a41 C1
a11 a22 a32 a41 C2
a11 a22 a32 a41 C2
a12 a22 a31 a41 C1
a11 a22 a32 a41 C2
a11 a22 a31 a42 C1
a11 a21 a32 a42 C2
a11 a22 a32 a41 C2
a12 a22 a31 a41 C1
a12 a22 a31 a42 C1
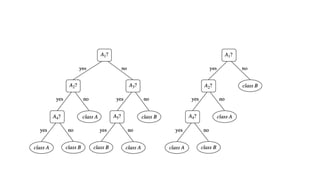
• Is there any “clue” that enables to
select the “best” attribute first?
• Suppose, following are two
attempts:
• A1A2A3A4 [naïve]
• A3A2A4A1 [Random]
• Draw the decision trees in the above-
mentioned two cases.
• Are the trees different to classify any test
data?
• If any other sample data is added into the
database, is that likely to alter the decision
tree already obtained?
49.
49
Computing Information-Gain forContinuous-
Valued Attributes
• Let attribute A be a continuous-valued attribute
• Must determine the best split point for A
• Sort the value A in increasing order
• Typically, the midpoint between each pair of adjacent values is
considered as a possible split point
• (ai+ai+1)/2 is the midpoint between the values of ai and ai+1
• The point with the minimum expected information
requirement for A is selected as the split-point for A
• Split:
• D1 is the set of tuples in D satisfying A ≤ split-point, and D2 is
the set of tuples in D satisfying A > split-point
50.
CS 40003: DataAnalytics 50
Splitting of Continuous Attribute Values
• In the foregoing discussion, we assumed that an attribute to be splitted is
with a finite number of discrete values. Now, there is a great deal if the
attribute is not so, rather it is a continuous-valued attribute.
• There are two approaches mainly to deal with such a case.
1. Data Discretization: All values of the attribute can be discretized into a
finite number of group values and then split point can be decided at each
boundary point of the groups.
So, if there are of discrete values, then we have split points.
𝑣 1 𝑣 2 𝑣 3 𝑣 𝑁
51.
CS 40003: DataAnalytics 51
Splitting of Continuous attribute values
2. Mid-point splitting: Another approach to avoid the data discretization.
• It sorts the values of the attribute and take the distinct values only in it.
• Then, the mid-point between each pair of adjacent values is considered as a
split-point.
• Here, if n-distinct values are there for the attribute , then we choose split
points as shown above.
• For example, there is a split point in between and
• For each split-point, we have two partitions: , and finally the point with
maximum information gain is the desired split point for that attribute.
𝑣1 𝑣2 𝑣3 𝑣𝑖 𝑣𝑖+1 𝑣𝑛
52.
52
Gain Ratio forAttribute Selection (C4.5)
• Information gain measure is biased towards attributes with a
large number of values
• C4.5 (a successor of ID3) uses gain ratio to overcome the
problem (normalization to information gain)
• GainRatio(A) = Gain(A)/SplitInfo(A)
• Ex.
• gain_ratio(income) = 0.029/1.557 = 0.019
• The attribute with the maximum gain ratio is selected as the
splitting attribute
)
|
|
|
|
(
log
|
|
|
|
)
( 2
1 D
D
D
D
D
SplitInfo
j
v
j
j
A
53.
53
Gini Index (CART,IBM IntelligentMiner)
• If a data set D contains examples from n classes, gini index, gini(D) is
defined as
where pj is the relative frequency of class j in D
• If a data set D is split on A into two subsets D1 and D2, the gini index
gini(D) is defined as
• Reduction in Impurity:
• The attribute provides the smallest ginisplit(D) (or the largest
reduction in impurity) is chosen to split the node (need to
enumerate all the possible splitting points for each attribute)
n
j
p j
D
gini
1
2
1
)
(
)
(
|
|
|
|
)
(
|
|
|
|
)
( 2
2
1
1
D
gini
D
D
D
gini
D
D
D
giniA
)
(
)
(
)
( D
gini
D
gini
A
gini A
54.
54
Computation of GiniIndex
• Ex. D has 9 tuples in buys_computer = “yes” and 5 in “no”
• Suppose the attribute income partitions D into 10 in D1: {low,
medium} and 4 in D2
Gini{low,high} is 0.458; Gini{medium,high} is 0.450. Thus, split on the
{low,medium} (and {high}) since it has the lowest Gini index
• All attributes are assumed continuous-valued
• May need other tools, e.g., clustering, to get the possible split
values
• Can be modified for categorical attributes
459
.
0
14
5
14
9
1
)
(
2
2
D
gini
)
(
14
4
)
(
14
10
)
( 2
1
}
,
{ D
Gini
D
Gini
D
gini medium
low
income
55.
55
Comparing Attribute SelectionMeasures
• The three measures, in general, return good results but
• Information gain:
• biased towards multivalued attributes
• Gain ratio:
• tends to prefer unbalanced splits in which one partition is much
smaller than the others
• Gini index:
• biased to multivalued attributes
• has difficulty when # of classes is large
• tends to favor tests that result in equal-sized partitions and purity in
both partitions
56.
56
Other Attribute SelectionMeasures
• CHAID: a popular decision tree algorithm, measure based on χ2
test for
independence
• C-SEP: performs better than info. gain and gini index in certain cases
• G-statistic: has a close approximation to χ2
distribution
• MDL (Minimal Description Length) principle (i.e., the simplest solution is preferred):
• The best tree as the one that requires the fewest # of bits to both (1) encode
the tree, and (2) encode the exceptions to the tree
• Multivariate splits (partition based on multiple variable combinations)
• CART: finds multivariate splits based on a linear comb. of attrs.
• Which attribute selection measure is the best?
• Most give good results, none is significantly superior than others
57.
57
Overfitting and TreePruning
• Overfitting: An induced tree may overfit the training data
• Too many branches, some may reflect anomalies due to
noise or outliers
• Poor accuracy for unseen samples
• Two approaches to avoid overfitting
• Prepruning: Halt tree construction early do not split a node if
̵
this would result in the goodness measure falling below a
threshold
• Difficult to choose an appropriate threshold
• Postpruning: Remove branches from a “fully grown” tree—
get a sequence of progressively pruned trees
• Use a set of data different from the training data to decide which is
the “best pruned tree”
59.
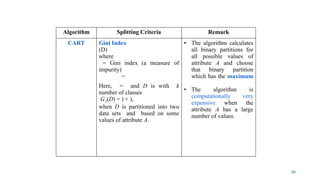
Table 11.6
Algorithm SplittingCriteria Remark
ID3 Information Gain
(D)
Where
= Entropy of D (a measure of
uncertainty) =
where D is with set of k classes
, , … , and = ; Here, is the
set of tuples with class in D.
(D) = Weighted average
entropy when D is partitioned
on the values of attribute A = )
Here, m denotes the distinct
values of attribute A.
• The algorithm
calculates ,D) for all in
D and choose that
attribute which has
maximum ,D).
• The algorithm can handle
both categorical and
numerical attributes.
• It favors splitting those
attributes, which has a
large number of distinct
values.
59
60.
60
Algorithm Splitting CriteriaRemark
CART Gini Index
(D)
where
= Gini index (a measure of
impurity)
=
Here, = and D is with k
number of classes
GA(D) = ) + ),
when D is partitioned into two
data sets and based on some
values of attribute A.
• The algorithm calculates
all binary partitions for
all possible values of
attribute A and choose
that binary partition
which has the maximum
• The algorithm is
computationally very
expensive when the
attribute A has a large
number of values.
61.
61
Algorithm Splitting CriteriaRemark
C4.5 Gain Ratio
where
= Information gain of D (same
as in ID3, and
= splitting information
=
when D is partitioned into , ,
… , partitions corresponding
to m distinct attribute values of
A.
• The attribute A with
maximum value of is
selected for splitting.
• Splitting information is a
kind of normalization, so
that it can check the
biasness of information
gain towards the
choosing attributes with
a large number of distinct
values.
In addition to this, we also highlight few important characteristics
of decision tree induction algorithms in the following.
Editor's Notes
#14 I : the expected information needed to classify a given sample
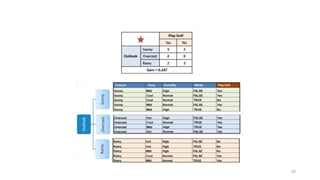
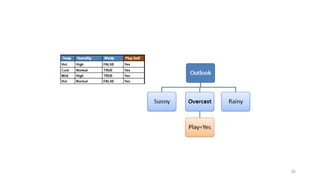
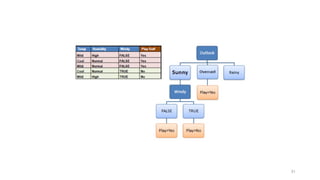
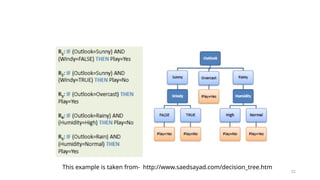
E (entropy) : expected information based on the partitioning into subsets by A










![19
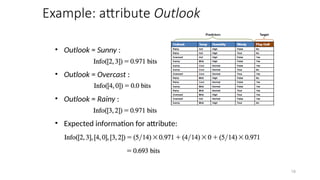
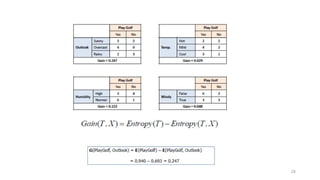
Computing information gain
• Information gain: information before splitting –
information after splitting
• Information gain for attributes from weather data:
Gain(Outlook ) = 0.247 bits
Gain(Temperature ) = 0.029 bits
Gain(Humidity ) = 0.152 bits
Gain(Windy ) = 0.048 bits
Gain(Outlook ) = Info([9,5]) – info([2,3],[4,0],[3,2])
= 0.940 – 0.693
= 0.247 bits](https://image.slidesharecdn.com/decisiontree-250317044305-cb724e31/85/DecisionTree-pptx-for-btech-cse-student-19-320.jpg)















![Illustration : DT Algorithm
Example 9.5: Illustration of DT Algorithm
• Consider an anonymous database as shown.
48
A1 A2 A3 A4 Class
a11 a21 a31 a41 C1
a12 a21 a31 a42 C1
a11 a21 a31 a41 C1
a11 a22 a32 a41 C2
a11 a22 a32 a41 C2
a12 a22 a31 a41 C1
a11 a22 a32 a41 C2
a11 a22 a31 a42 C1
a11 a21 a32 a42 C2
a11 a22 a32 a41 C2
a12 a22 a31 a41 C1
a12 a22 a31 a42 C1
• Is there any “clue” that enables to
select the “best” attribute first?
• Suppose, following are two
attempts:
• A1A2A3A4 [naïve]
• A3A2A4A1 [Random]
• Draw the decision trees in the above-
mentioned two cases.
• Are the trees different to classify any test
data?
• If any other sample data is added into the
database, is that likely to alter the decision
tree already obtained?](https://image.slidesharecdn.com/decisiontree-250317044305-cb724e31/85/DecisionTree-pptx-for-btech-cse-student-48-320.jpg)