Downloaded 42 times











![Java example: Hadoop task
@Component
public class HBaseEventLogToMySQL extnds Configured implements Tool {
@Autowired private EntityManagerFactory entityManagerFactory;
@Override public int run(String[] args) throws Exception {
LogAbstractEvent lastEvent = getLastMySQLEvent();
Scan scan;
String lastEventKey = "";
if (lastEvent == null) {
scan = new Scan();
} else {
lastEventKey = lastEvent.getEventKey();
scan = new Scan(Bytes.toBytes(lastEventKey + Character.MAX_VALUE));
}
final Configuration conf = HBaseConfiguration.create(getConf());
HTable table = new HTable(conf, tableName);
ResultScanner resultScanner = table.getScanner(scan);
readRowsToMySQL(resultScanner);
}
21(24)](https://image.slidesharecdn.com/intrumjug-140805143526-phpapp01/85/Big-Data-Processing-Using-Hadoop-Infrastructure-21-320.jpg)
![Java example: Map part (Table)
public class BasicProdStatusHbaseMapper extends TableMapper<Text,
MapWritableComparable> {
@Override public void map(ImmutableBytesWritable key, Result value, Context
context) throws IOException, InterruptedException {
byte[] caseByteArr = value.getValue(FAMILY, CASE_QUALIFIER);
Map<> caseMap = HbaseUtils.convertCaseColumnByteArrToMap(caseByteArr);
MapWritableComparable map = new MapWritableComparable();
map.put(new Text("originalCapital"), new
DoubleWritable((Double)caseMap.get("OriginalCapital")));
map.put(new Text("remainingCapital"), new
DoubleWritable((Double)caseMap.get("RemainingCapital")));
context.getCounter(COUNTERS_COMMON_GROUP, COUNTER_CASES_MAPPED).increment(1);
context.write(new Text(mainStatusCode), map);
}}
22(24)](https://image.slidesharecdn.com/intrumjug-140805143526-phpapp01/85/Big-Data-Processing-Using-Hadoop-Infrastructure-22-320.jpg)



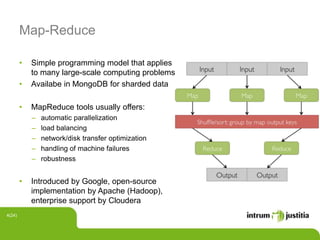
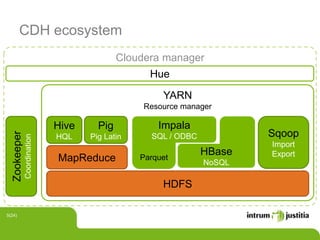
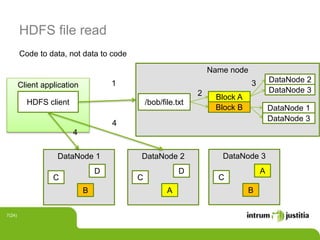
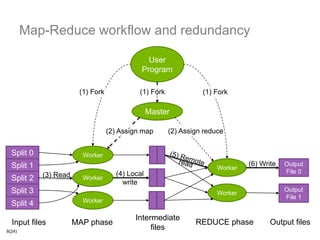
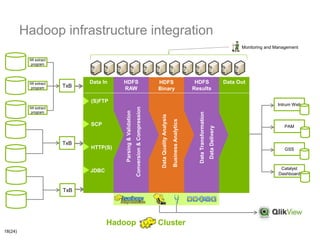
The document discusses using Hadoop infrastructure for big data processing. It describes Intrum Justitia SDC, which has data across 20 countries in various formats and a high number of data objects. Hadoop provides solutions like MapReduce and HDFS for distributed storage and processing at scale. The Hadoop ecosystem includes tools like Hive, Pig, HBase, Impala and Oozie that help process and analyze large datasets. Examples of using Hadoop with Java and integrating it into development environments are also included.











































































































