Downloaded 48 times









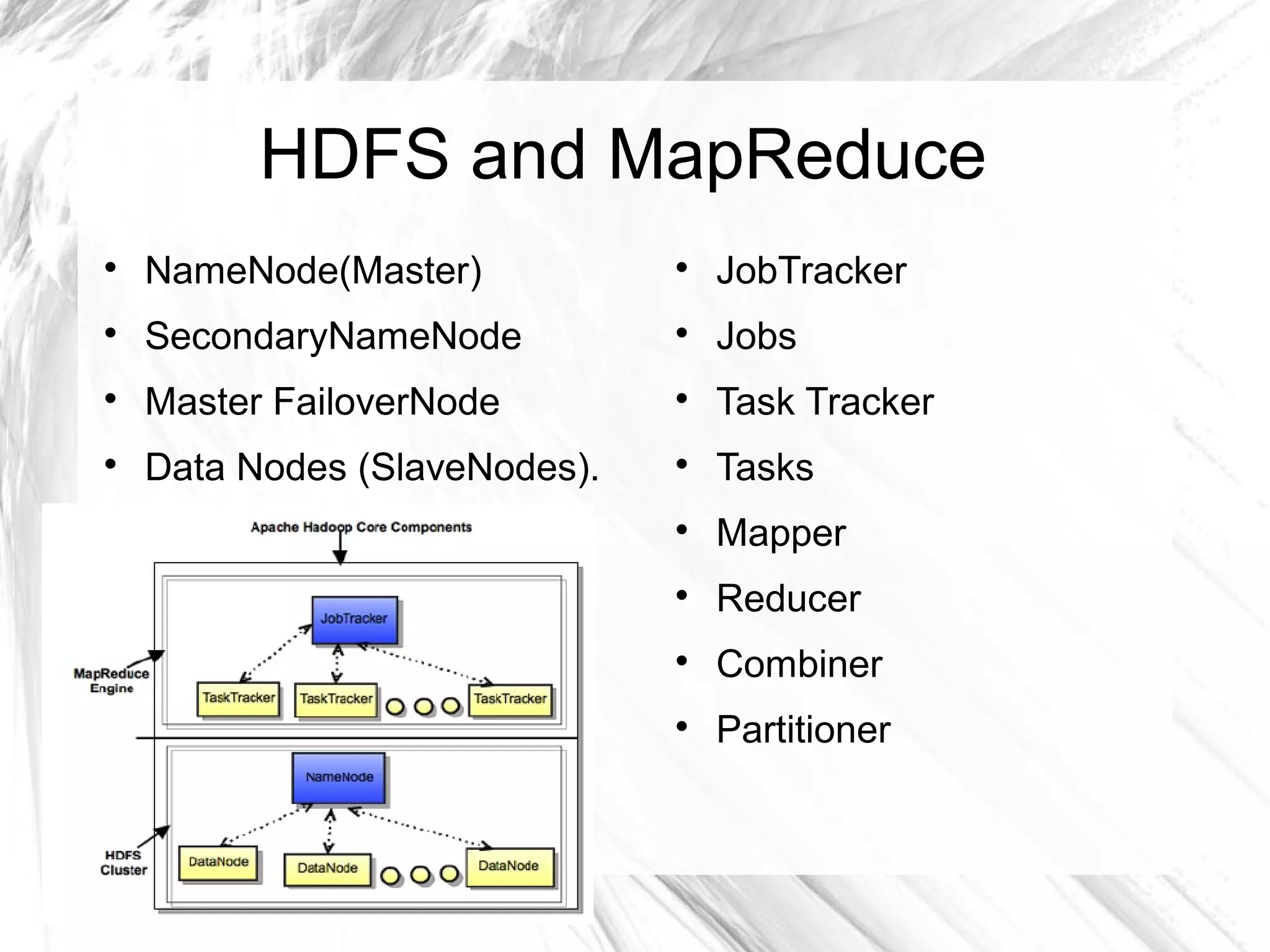
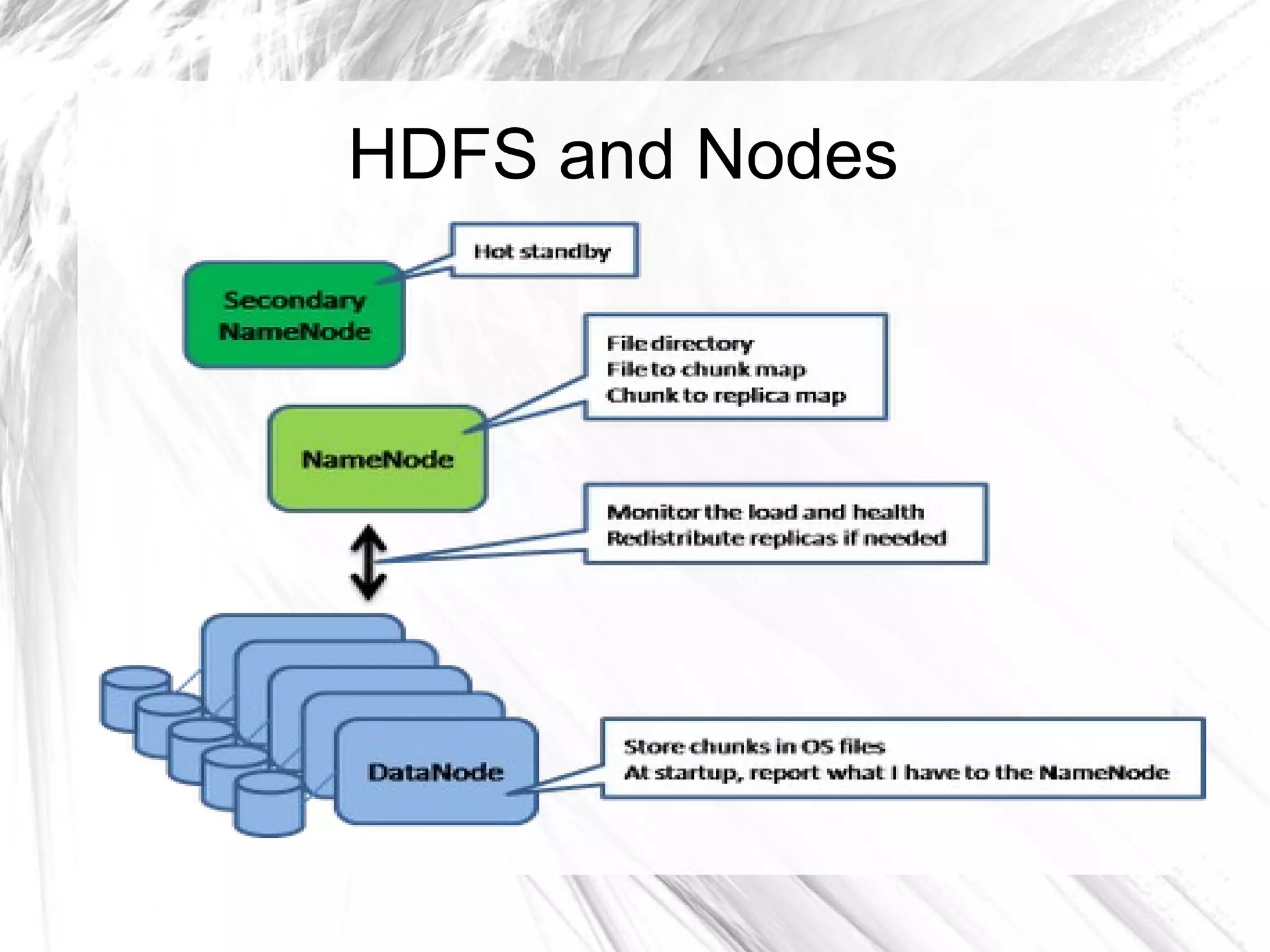
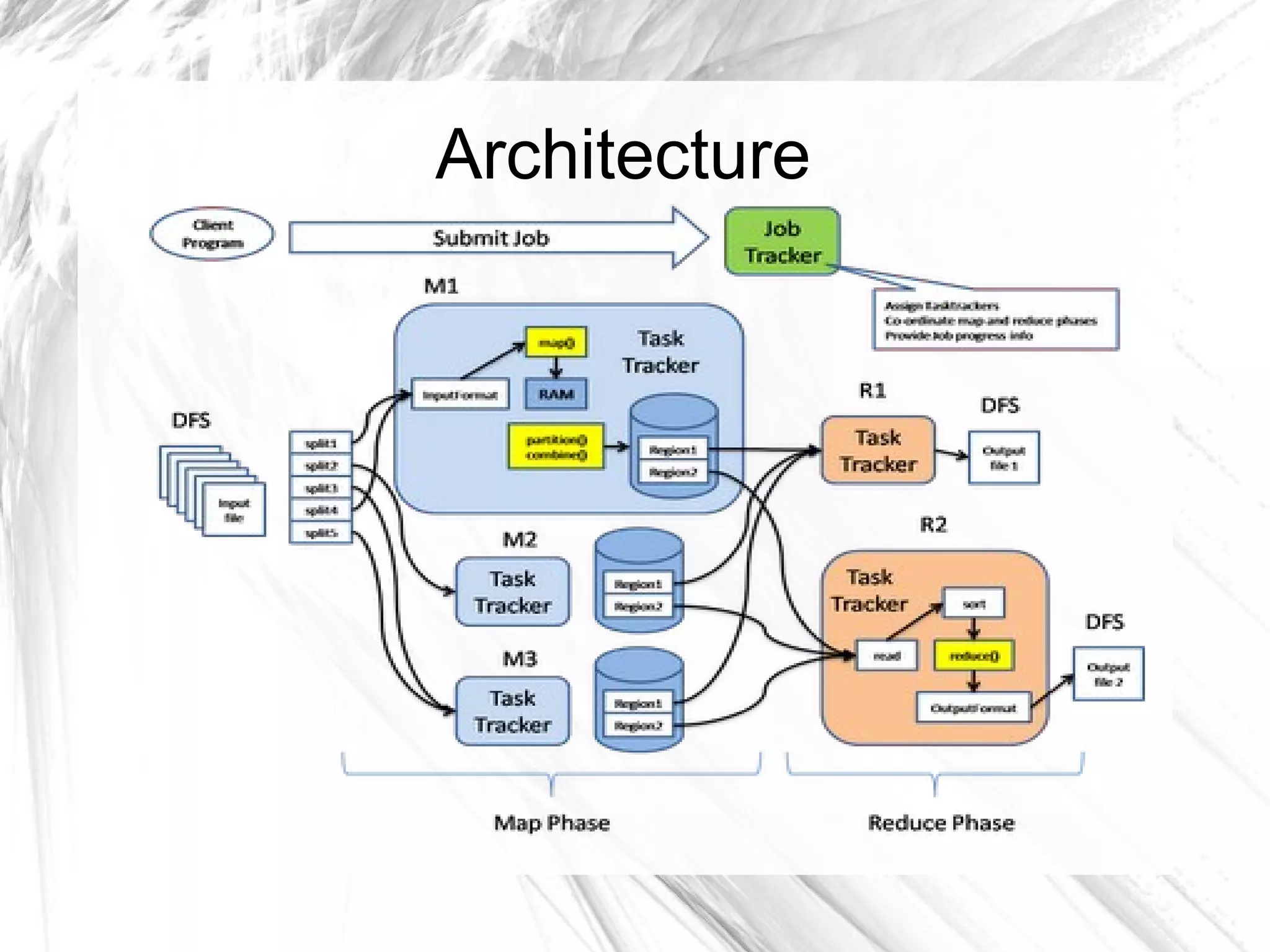
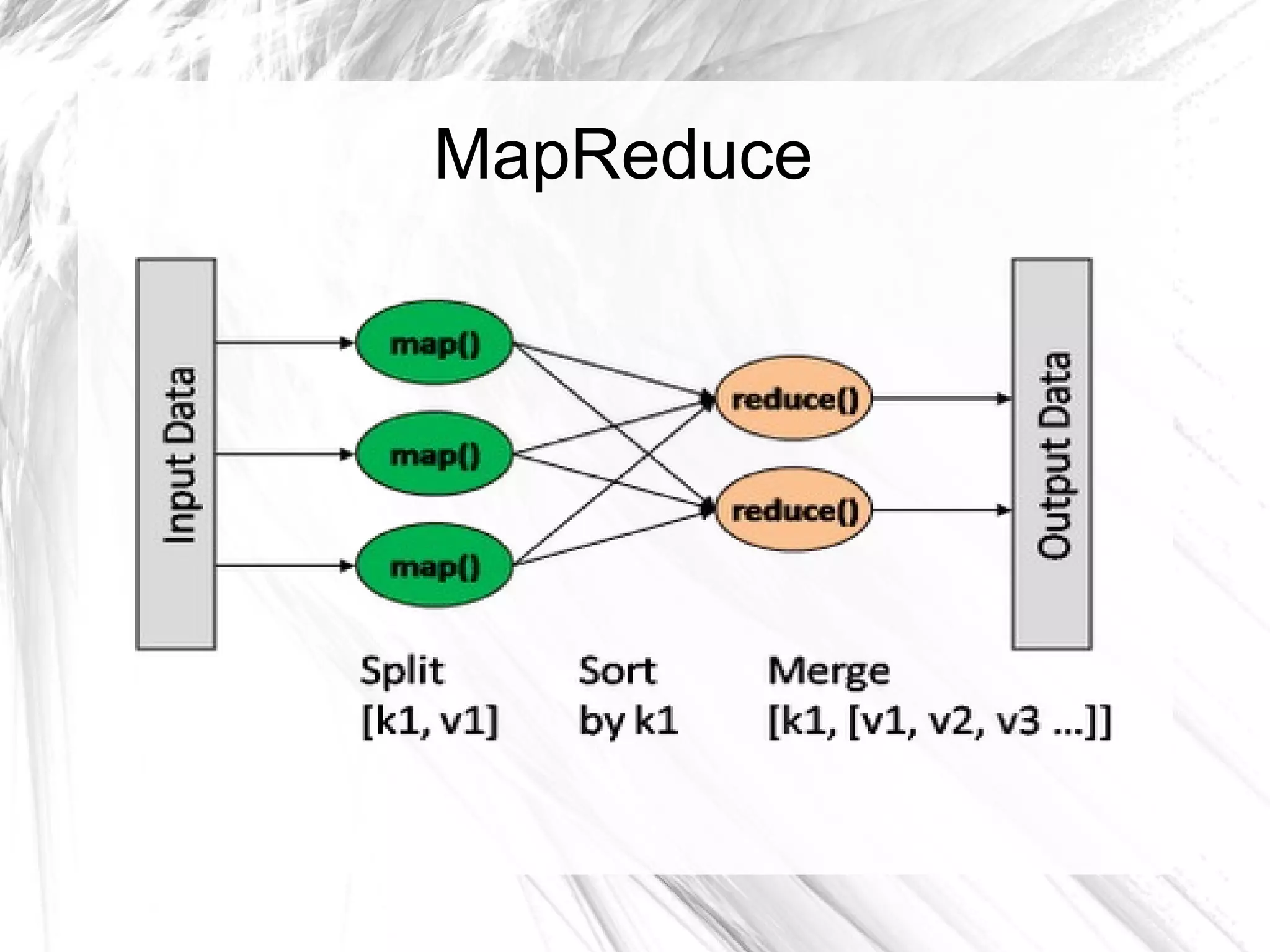
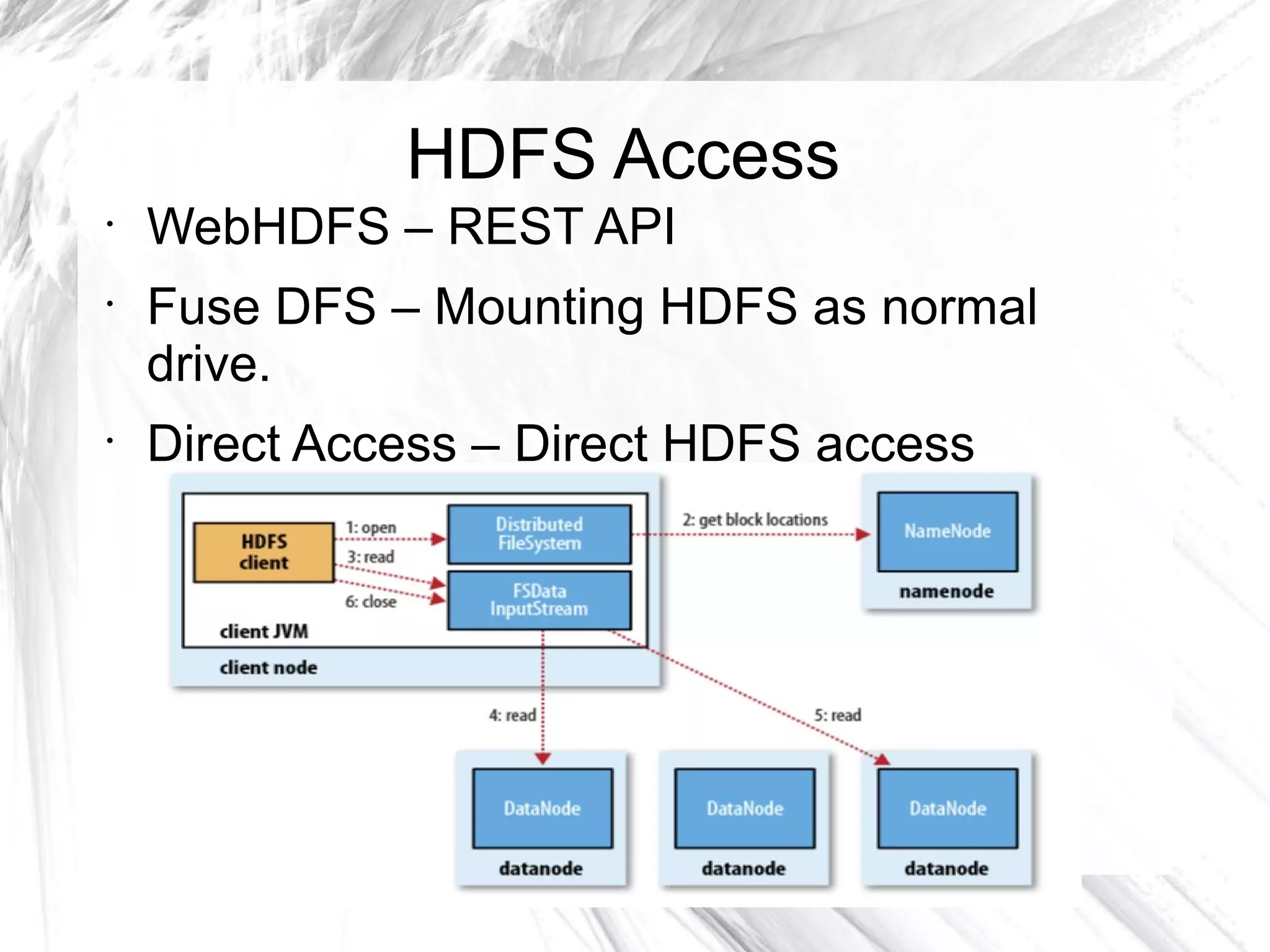


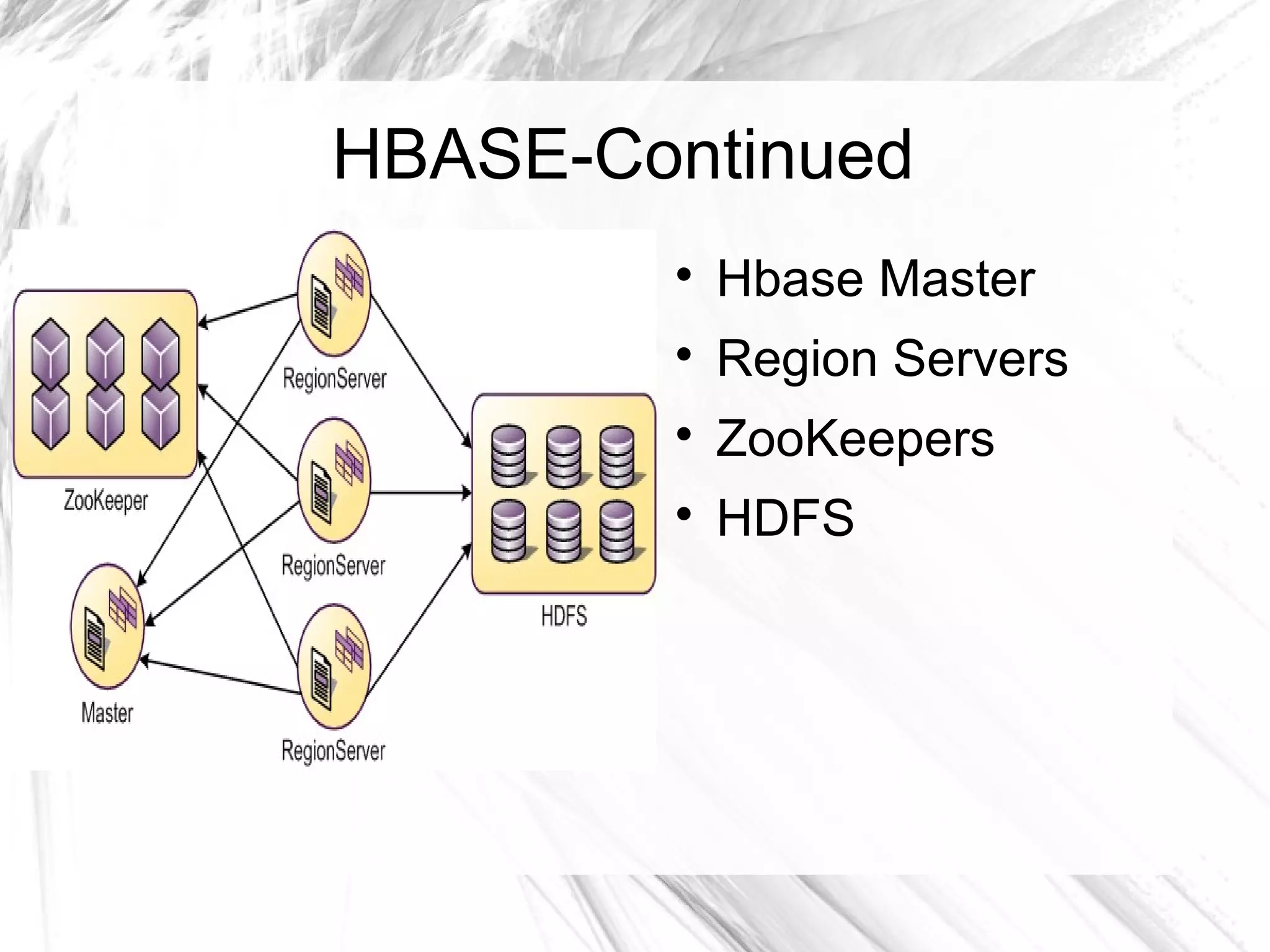





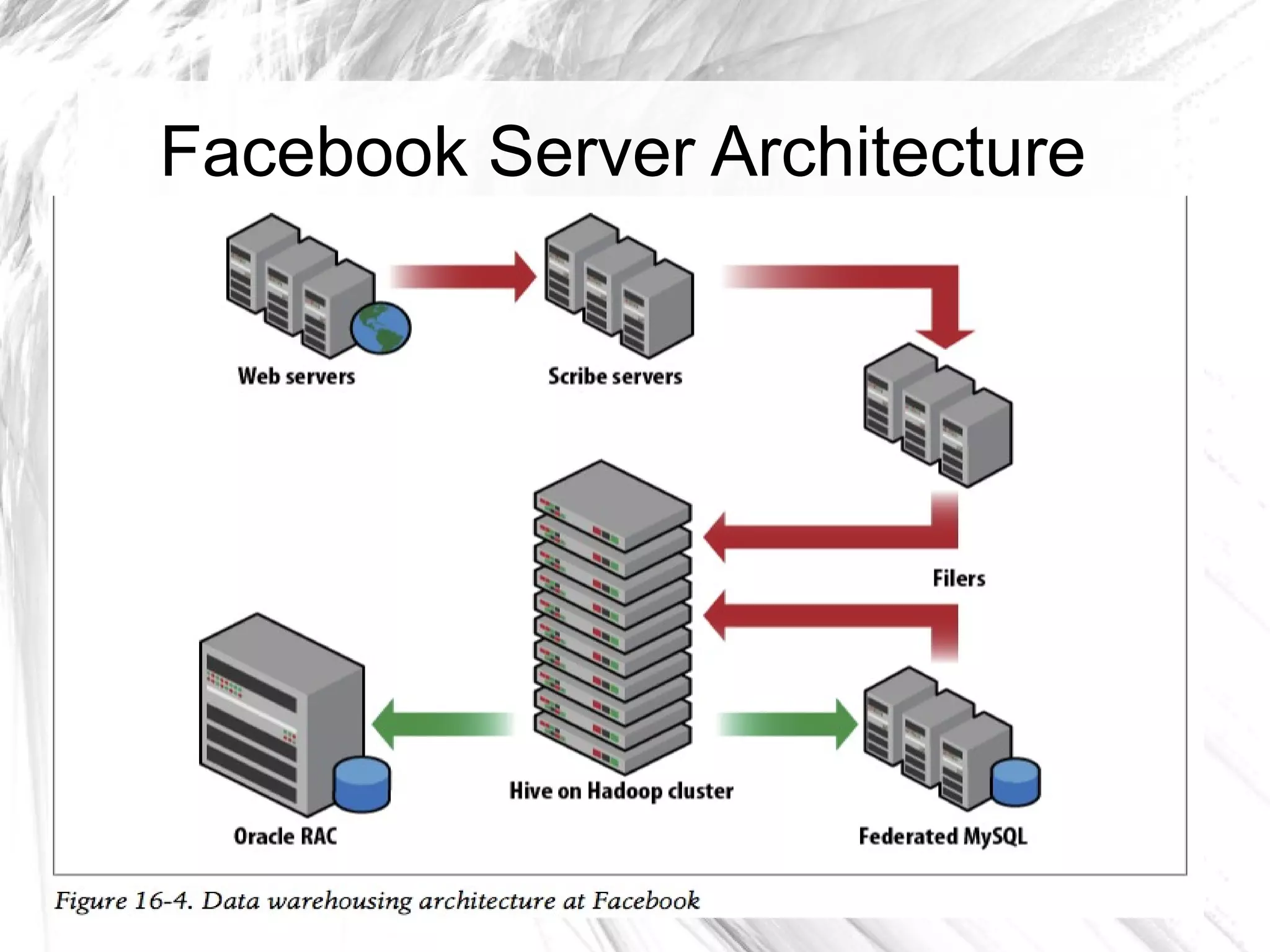

The document provides an overview of big data and Hadoop, detailing its architecture, components, and tools used for processing large datasets. It discusses the challenges of big data management and the advantages of using Hadoop alongside traditional RDBMS for efficient data processing. Key Hadoop components such as HDFS, MapReduce, Hive, Pig, and HBase are explained, highlighting their roles in distributed data operations and analytics.




























![[123] quality without qa](https://cdn.slidesharecdn.com/ss_thumbnails/132qualitywithoutqa-150914011521-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)










































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)



![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)








