Downloaded 11 times










![10/39
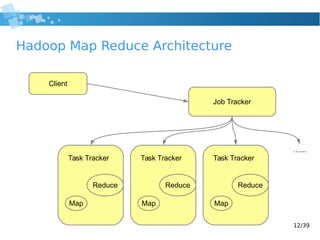
Word Count pseudo code
1: def map(String key, String value)
2: foreach word in value:
3: emit(word, 1);
4:
5: def reduce(String key, int[] values)
6: int result = 0;
7: foreach val in values:
8: result += val;
9: emit(key, result);
10:](https://image.slidesharecdn.com/2014hadoop-wrocawjug-140827024520-phpapp02/85/2014-hadoop-wroclaw-jug-10-320.jpg)









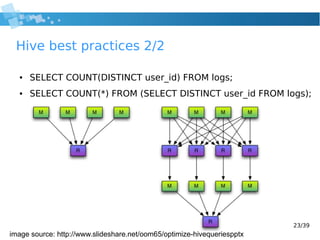











![36/39
PYMK 4/5 mapper
//user: integer, friends: integer list
function map(user, friends)
for i = 0 to friends.length-1:
emit(user, (1, friends[i])) //direct friends
for j = i+1 to friends.length-1:
//indirect friends
emit(friends[i], (2, friends[j]))
emit(friends[j], (2, friends[i]))](https://image.slidesharecdn.com/2014hadoop-wrocawjug-140827024520-phpapp02/85/2014-hadoop-wroclaw-jug-36-320.jpg)




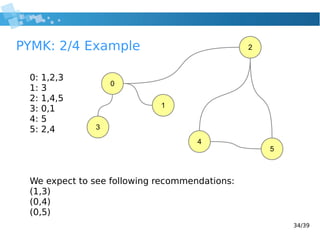
This document provides an introduction to Hadoop, including: - An overview of big data and the challenges it poses for data storage and processing. - How Hadoop addresses these challenges through its distributed, scalable architecture based on MapReduce and HDFS. - Descriptions of key Hadoop components like MapReduce, HDFS, Hive, and Sqoop. - Examples of how to perform common data processing tasks like word counting and friend recommendations using MapReduce. - Some best practices, limitations, and other tools in the Hadoop ecosystem.




































![[Sách Hay] Marketing Cho Bán Lẻ](https://cdn.slidesharecdn.com/ss_thumbnails/marketingbanle-150703041530-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


























