Downloaded 245 times

















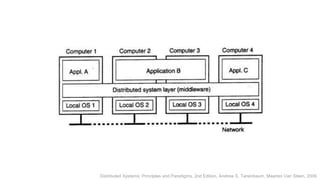
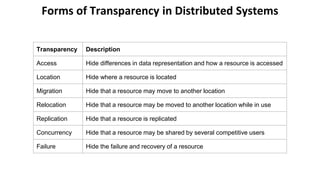








The document provides an overview of big data, its definitions, and characteristics, highlighting the challenges and the need for alternative processing methods due to its volume, velocity, and variety. It also introduces distributed systems, describing them as collections of independent computers that function as a single system, emphasizing the importance of transparency and collaboration among components. Additionally, it discusses the implications of big data on decision-making and operational efficiency.











































































































