





























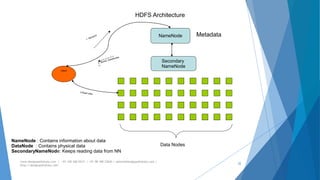

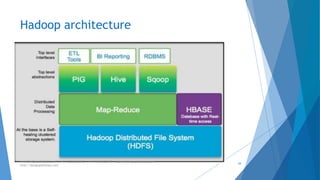

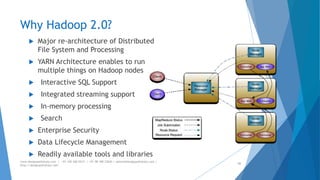
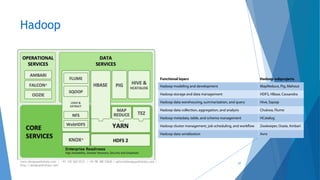
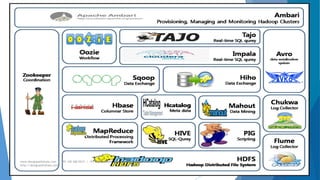





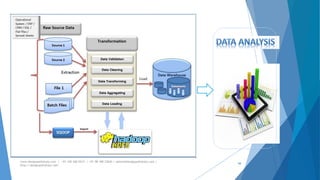

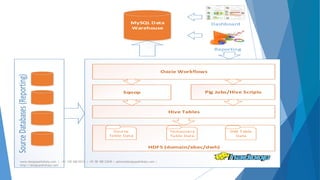
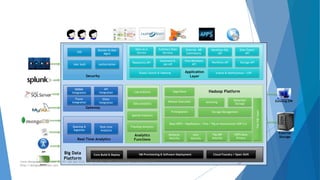
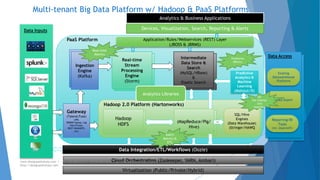


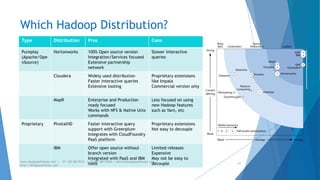
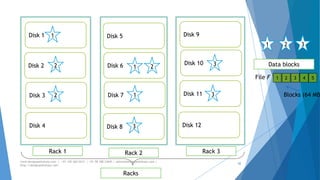



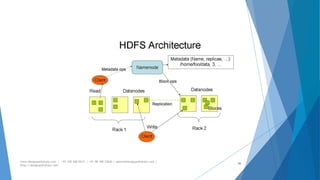



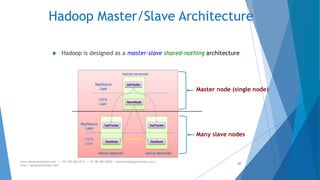


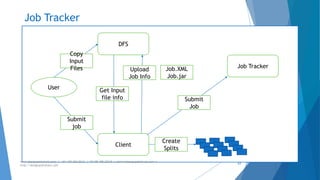
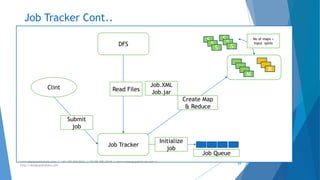
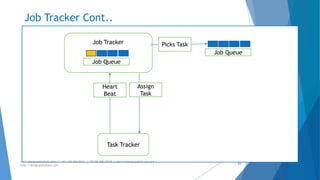

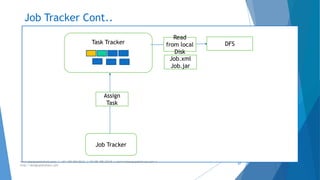


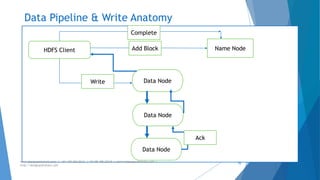


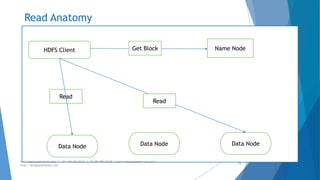



The document provides an overview of Apache Hadoop, highlighting its motivation, basic concepts, and various components such as MapReduce, Hive, Pig, and Sqoop. It emphasizes the significance of handling big data through distributed processing across clusters of commodity computers, with key features including scalability, efficiency, and reliability. Additionally, it mentions the historical context of Hadoop's development and its applications in data analysis and business intelligence.












































































![[DSC Europe 25] Paula Garcia Esteban -Building the Future: The Role of Data S...](https://cdn.slidesharecdn.com/ss_thumbnails/9ld1r1bsqpwve8qfvphy-paula-garcia-esteban-building-the-future-260122103838-4171f5cb-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)





